

随着互联网、移动互联网和物联网的发展,谁也无法否认,我们已经切实地迎来了一个海量数据的时代,数据调查公司IDC预计2011年的数据总量将达到1.8万亿GB,对这些海量数据的分析已经成为一个非常重要且紧迫的需求。
作为一家互联网数据分析公司,我们在海量数据的分析领域那真是被“逼上梁山”。多年来在严苛的业务需求和数据压力下,我们几乎尝试了所有可能的大数据分析方法,最终落地于Hadoop平台之上。
Hadoop在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,事实上已成为当前互联网企业主流的大数据分析平台。本文主要介绍一种基于Hadoop平台的多维分析和数据挖掘平台架构。
大数据分析的分类
Hadoop平台对业务的针对性较强,为了让你明确它是否符合你的业务,现粗略地从几个角度将大数据分析的业务需求分类,针对不同的具体需求,应采用不同的数据分析架构。
按照数据分析的实时性,分为实时数据分析和离线数据分析两种。
实时数据分析一般用于金融、移动和互联网B2C等产品,往往要求在数秒内返回上亿行数据的分析,从而达到不影响用户体验的目的。要满足这样的需求,可以采用精心设计的传统关系型数据库组成并行处理集群,或者采用一些内存计算平台,或者采用HDD的架构,这些无疑都需要比较高的软硬件成本。目前比较新的海量数据实时分析工具有EMC的Greenplum、SAP的HANA等。
对于大多数反馈时间要求不是那么严苛的应用,比如离线统计分析、机器学习、搜索引擎的反向索引计算、推荐引擎的计算等,应采用离线分析的方式,通过数据采集工具将日志数据导入专用的分析平台。但面对海量数据,传统的ETL工具往往彻底失效,主要原因是数据格式转换的开销太大,在性能上无法满足海量数据的采集需求。互联网企业的海量数据采集工具,有Facebook 开源的Scribe、LinkedIn开源的Kafka、淘宝开源的Timetunnel、Hadoop的Chukwa等,均可以满足每秒数百MB的日志数据采集和传输需求,并将这些数据上载到Hadoop中央系统上。
按照大数据的数据量,分为内存级别、BI级别、海量级别三种。
这里的内存级别指的是数据量不超过集群的内存***值。不要小看今天内存的容量,Facebook缓存在内存的Memcached中的数据高达 320TB,而目前的PC服务器,内存也可以超过百GB。因此可以采用一些内存数据库,将热点数据常驻内存之中,从而取得非常快速的分析能力,非常适合实时分析业务。图1是一种实际可行的MongoDB分析架构。
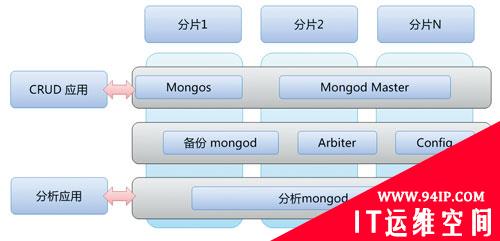 图1 用于实时分析的MongoDB架构
图1 用于实时分析的MongoDB架构
MongoDB大集群目前存在一些稳定性问题,会发生周期性的写堵塞和主从同步失效,但仍不失为一种潜力十足的可以用于高速数据分析的NoSQL。
此外,目前大多数服务厂商都已经推出了带4GB以上SSD的解决方案,利用内存+SSD,也可以轻易达到内存分析的性能。随着SSD的发展,内存数据分析必然能得到更加广泛的应用。
BI级别指的是那些对于内存来说太大的数据量,但一般可以将其放入传统的BI产品和专门设计的BI数据库之中进行分析。目前主流的BI产品都有支持TB级以上的数据分析方案。种类繁多,就不具体列举了。
海量级别指的是对于数据库和BI产品已经完全失效或者成本过高的数据量。海量数据级别的优秀企业级产品也有很多,但基于软硬件的成本原因,目前大多数互联网企业采用Hadoop的HDFS分布式文件系统来存储数据,并使用MapReduce进行分析。本文稍后将主要介绍Hadoop上基于 MapReduce的一个多维数据分析平台。
#p#
数据分析的算法复杂度
根据不同的业务需求,数据分析的算法也差异巨大,而数据分析的算法复杂度和架构是紧密关联的。举个例子,Redis是一个性能非常高的内存Key-Value NoSQL,它支持List和Set、SortedSet等简单集合,如果你的数据分析需求简单地通过排序,链表就可以解决,同时总的数据量不大于内存 (准确地说是内存加上虚拟内存再除以2),那么无疑使用Redis会达到非常惊人的分析性能。
还有很多易并行问题(Embarrassingly Parallel),计算可以分解成完全独立的部分,或者很简单地就能改造出分布式算法,比如大规模脸部识别、图形渲染等,这样的问题自然是使用并行处理集群比较适合。
而大多数统计分析,机器学习问题可以用MapReduce算法改写。MapReduce目前最擅长的计算领域有流量统计、推荐引擎、趋势分析、用户行为分析、数据挖掘分类器、分布式索引等。
面对大数据OLAP分析的一些问题
OLAP分析需要进行大量的数据分组和表间关联,而这些显然不是NoSQL和传统数据库的强项,往往必须使用特定的针对BI优化的数据库。比如绝大多数针对BI优化的数据库采用了列存储或混合存储、压缩、延迟加载、对存储数据块的预统计、分片索引等技术。
Hadoop平台上的OLAP分析,同样存在这个问题,Facebook针对Hive开发的RCFile数据格式,就是采用了上述的一些优化技术,从而达到了较好的数据分析性能。如图2所示。
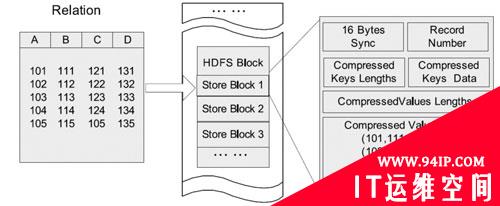 图2 RCFile的行列混合存
图2 RCFile的行列混合存
然而,对于Hadoop平台来说,单单通过使用Hive模仿出SQL,对于数据分析来说远远不够,首先Hive虽然将HiveQL翻译 MapReduce的时候进行了优化,但依然效率低下。多维分析时依然要做事实表和维度表的关联,维度一多性能必然大幅下降。其次,RCFile的行列混合存储模式,事实上限制死了数据格式,也就是说数据格式是针对特定分析预先设计好的,一旦分析的业务模型有所改动,海量数据转换格式的代价是极其巨大的。***,HiveQL对OLAP业务分析人员依然是非常不友善的,维度和度量才是直接针对业务人员的分析语言。
而且目前OLAP存在的***问题是:业务灵活多变,必然导致业务模型随之经常发生变化,而业务维度和度量一旦发生变化,技术人员需要把整个Cube(多维立方体)重新定义并重新生成,业务人员只能在此Cube上进行多维分析,这样就限制了业务人员快速改变问题分析的角度,从而使所谓的BI系统成为死板的日常报表系统。
使用Hadoop进行多维分析,首先能解决上述维度难以改变的问题,利用Hadoop中数据非结构化的特征,采集来的数据本身就是包含大量冗余信息的。同时也可以将大量冗余的维度信息整合到事实表中,这样可以在冗余维度下灵活地改变问题分析的角度。其次利用Hadoop MapReduce强大的并行化处理能力,无论OLAP分析中的维度增加多少,开销并不显著增长。换言之,Hadoop可以支持一个巨大无比的Cube,包含了无数你想到或者想不到的维度,而且每次多维分析,都可以支持成千上百个维度,并不会显著影响分析的性能。
因此,我们的大数据分析架构在这个巨大Cube的支持下,直接把维度和度量的生成交给业务人员,由业务人员自己定义好维度和度量之后,将业务的维度和度量直接翻译成 MapReduce运行,并最终生成报表。可以简单理解为用户快速自定义的“MDX”(多维表达式,或者多维立方体查询)语言→MapReduce的转换工具。同时OLAP分析和报表结果的展示,依然兼容传统的BI和报表产品。如图3所示。
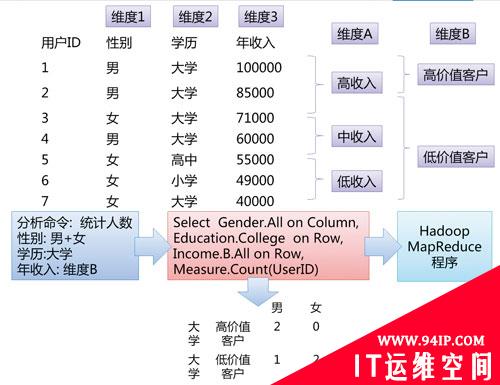 图3 MDX→MapReduce简略示意图
图3 MDX→MapReduce简略示意图
图3可以看出,在年收入上,用户可以自己定义子维度。另外,用户也可以在列上自定义维度,比如将性别和学历合并为一个维度。由于Hadoop数据的非结构化特征,维度可以根据业务需求任意地划分和重组。
#p#
一种Hadoop多维分析平台的架构
整个架构由四大部分组成:数据采集模块、数据冗余模块、维度定义模块、并行分析模块。如图4所示。
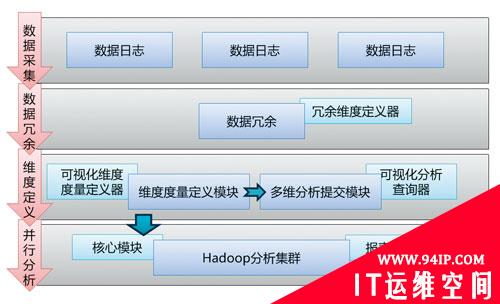 图4 Hadoop多维分析平台架构图
图4 Hadoop多维分析平台架构图
数据采集模块采用了Cloudera的Flume,将海量的小日志文件进行高速传输和合并,并能够确保数据的传输安全性。单个collector宕机之后,数据也不会丢失,并能将agent数据自动转移到其他的colllecter处理,不会影响整个采集系统的运行。如图5所示。
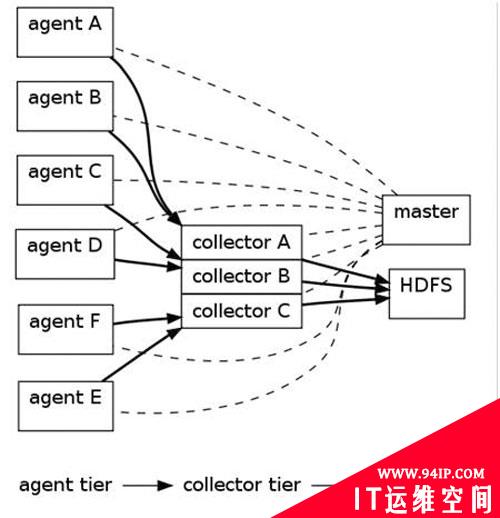 图5 采集模块
图5 采集模块
数据冗余模块不是必须的,但如果日志数据中没有足够的维度信息,或者需要比较频繁地增加维度,则需要定义数据冗余模块。通过冗余维度定义器定义需要冗余的维度信息和来源(数据库、文件、内存等),并指定扩展方式,将信息写入数据日志中。在海量数据下,数据冗余模块往往成为整个系统的瓶颈,建议使用一些比较快的内存NoSQL来冗余原始数据,并采用尽可能多的节点进行并行冗余;或者也完全可以在Hadoop中执行批量Map,进行数据格式的转化。
维度定义模块是面向业务用户的前端模块,用户通过可视化的定义器从数据日志中定义维度和度量,并能自动生成一种多维分析语言,同时可以使用可视化的分析器通过GUI执行刚刚定义好的多维分析命令。
并行分析模块接受用户提交的多维分析命令,并将通过核心模块将该命令解析为Map-Reduce,提交给Hadoop集群之后,生成报表供报表中心展示。
核心模块是将多维分析语言转化为MapReduce的解析器,读取用户定义的维度和度量,将用户的多维分析命令翻译成MapReduce程序。核心模块的具体逻辑如图6所示。
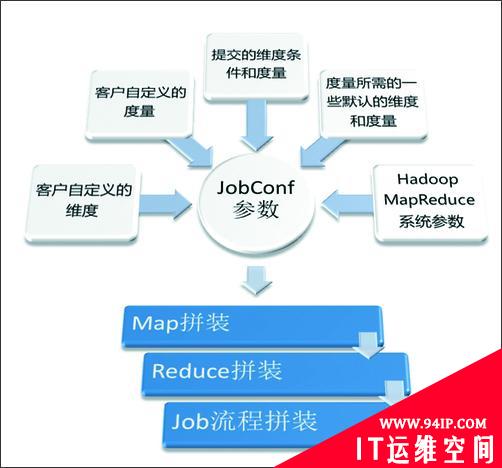 图6 核心模块的逻辑
图6 核心模块的逻辑
图6中根据JobConf参数进行Map和Reduce类的拼装并不复杂,难点是很多实际问题很难通过一个MapReduce Job解决,必须通过多个MapReduce Job组成工作流(WorkFlow),这里是最需要根据业务进行定制的部分。图7是一个简单的MapReduce工作流的例子。
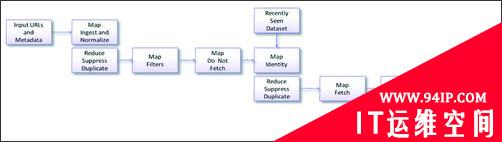 图7 MapReduce WorkFlow例子
图7 MapReduce WorkFlow例子
MapReduce的输出一般是统计分析的结果,数据量相较于输入的海量数据会小很多,这样就可以导入传统的数据报表产品中进行展现。
结束语
当然,这样的多维分析架构也不是没有缺点。由于MapReduce本身就是以蛮力去扫描大部分数据进行计算,因此无法像传统BI产品一样对条件查询做优化,也没有缓存的概念。往往很多很小的查询需要“兴师动众”。尽管如此,开源的Hadoop还是解决了很多人在大数据下的分析问题,真可谓是“功德无量”。
Hadoop集群软硬件的花费极低,每GB存储和计算的成本是其他企业级产品的百分之一甚至千分之一,性能却非常出色。我们可以轻松地进行千亿乃至万亿数据级别的多维统计分析和机器学习。
6月29日的Hadoop Summit 2011上,Yahoo!剥离出一家专门负责Hadoop开发和运维的公司Hortonworks。Cloudera带来了大量的辅助工具,MapR带来了号称三倍于Hadoop MapReduce速度的并行计算平台。Hadoop必将很快迎来下一代产品,届时其必然拥有更强大的分析能力和更便捷的使用方式,从而真正轻松面对未来海量数据的挑战。
转载请注明:IT运维空间 » 运维技术 » 大数据下的数据分析-Hadoop架构解析
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/9.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值










发表评论