

在11月初的时候,我们了解了Ubuntu 12.04 搭建 hadoop 集群版环境的方法,今天再来看看在单机版环境中,Ubuntu12.04搭建hadoop是如何实现的。
一. 你要安装Ubuntu这一步省略;
二. 在Ubuntu下创建hadoop用户组和用户;
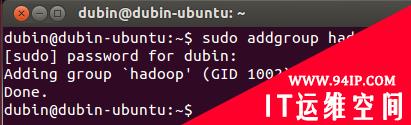
1. 创建hadoop用户组:
| sudo addgroup hadoop |
如图:
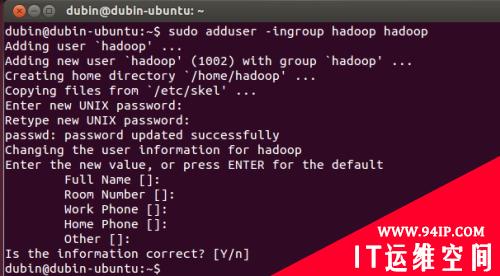
2. 创建hadoop用户:
| sudo adduser -ingroup hadoop hadoop |
如图:
3. 给hadoop用户添加权限,打开/etc/sudoers文件:
| sudo gedit /etc/sudoers |
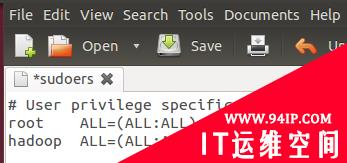
按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。
在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
| hadoop ALL=(ALL:ALL) ALL |
如图:
三. 在Ubuntu下安装JDK
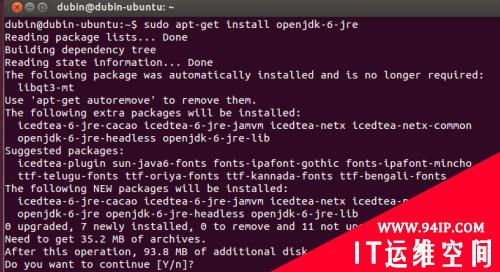
使用如下命令执行即可:
| sudo apt-get install openjdk-6-jre |
如图:
四. 修改机器名
每当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。
1. 打开/etc/hostname文件:
| sudo gedit /etc/hostname |
2. 将/etc/hostname文件中的ubuntu改为你想取的机器名。这里我取"dubin-ubuntu"。 重启系统后才会生效。
五. 安装ssh服务
这里的ssh和三大框架:spring,struts,hibernate没有什么关系,ssh可以实现远程登录和管理,具体可以参考其他相关资料。
安装openssh-server,
| sudo apt-get install ssh openssh-server |
这时假设您已经安装好了ssh,您就可以进行第六步了哦~
六、 建立ssh无密码登录本机
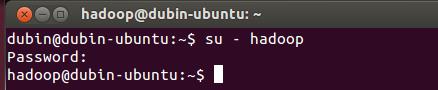
首先要转换成hadoop用户,执行以下命令:
| su – hadoop |
如图:
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1. 创建ssh-key,,这里我们采用rsa方式:
| ssh-keygen -t rsa -P "" |
如图:
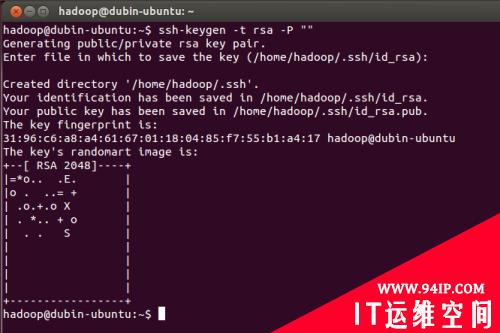
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2. 进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的:
| cd ~/.ssh cat id_rsa.pub >> authorized_keys |
如图:

(完成后就可以无密码登录本机了。)
3. 登录localhost:
| ssh localhost |
如图:
( 注:当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。)
4. 执行退出命令:
| exit |
七. 安装hadoop
我们采用的hadoop版本是:hadoop-0.20.203(http://www.apache.org/dyn/closer.cgi/hadoop/common/ ),因为该版本比较稳定。
1. 假设hadoop-0.20.203.tar.gz在桌面,将它复制到安装目录 /usr/local/下:
| sudo cp hadoop-0.20.203.0rc1.tar.gz /usr/local/ |
2. 解压hadoop-0.20.203.tar.gz:
| cd /usr/local sudo tar -zxf hadoop-0.20.203.0rc1.tar.gz |
3. 将解压出的文件夹改名为hadoop:
| sudo mv hadoop-0.20.203.0 hadoop |
4. 将该hadoop文件夹的属主用户设为hadoop:
| sudo chown -R hadoop:hadoop hadoop |
5. 打开hadoop/conf/hadoop-env.sh文件:
| sudo gedit hadoop/conf/hadoop-env.sh |
6. 配置conf/hadoop-env.sh(找到#export JAVA_HOME=…,去掉#,然后加上本机jdk的路径):
| export JAVA_HOME=/usr/lib/jvm/java-6-openjdk |
7. 打开conf/core-site.xml文件:
| sudo gedit hadoop/conf/core-site.xml |
编辑如下:
<?xmlversion="1.0"?> <?xml-stylesheettype="text/xsl"href="configuration.xsl"?> <!--Putsite-specificpropertyoverridesinthisfile.--> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
8. 打开conf/mapred-site.xml文件:
| sudo gedit hadoop/conf/mapred-site.xml |
编辑如下:
<?xmlversion="1.0"?> <?xml-stylesheettype="text/xsl"href="configuration.xsl"?> <!--Putsite-specificpropertyoverridesinthisfile.--> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
9. 打开conf/hdfs-site.xml文件:
| sudo gedit hadoop/conf/hdfs-site.xml |
编辑如下:
<configuration> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
10. 打开conf/masters文件,添加作为secondarynamenode的主机名,作为单机版环境,这里只需填写 localhost 就Ok了。
| sudo gedit hadoop/conf/masters |
11. 打开conf/slaves文件,添加作为slave的主机名,一行一个。作为单机版,这里也只需填写 localhost就Ok了。
| sudo gedit hadoop/conf/slaves |
八. 在单机上运行hadoop
1. 进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作,
| cd /usr/local/hadoop/ bin/hadoop namenode -format |
2. 当你看到下图时,就说明你的hdfs文件系统格式化成功了。
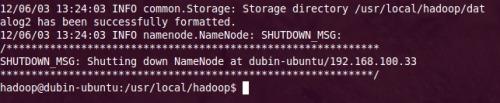
3. 启动bin/start-all.sh:
| bin/start-all.sh |
4. 检测hadoop是否启动成功:
| jps |
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五个进程,就说明你的hadoop单机版环境配置好了!
如下图:
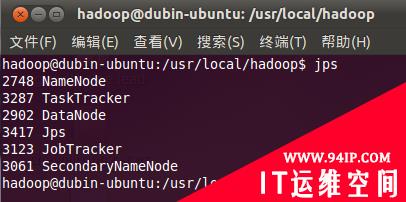
至此,一个hadoop的单机版环境就搭建好了,如果有什么问题,请给我提出来,咱们可以相互交流。
后续我将会整理hadoop集群的搭建,和测试的教程。敬请关注!
转载请注明:IT运维空间 » 运维技术 » Ubuntu 12.04搭建hadoop单机版环境
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/3.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论