

Hadoop 和数据处理
Hadoop 将许多重要特性结合在一起,这使 Hadoop 对于将大量数据分解为更小、实用的数据块非常有用。
Hadoop 的主要组件是 HDFS 文件系统,它支持将信息分布到整个集群中。对于使用这种分布格式存储的信息,可以通过一个名为 MapReduce 的系统在每个集群节点上进行单独处理。MapReduce 进程将存储在 HDFS 文件系统中的信息转换为更小的、经过处理的、更容易管理的数据块。
因为 Hadoop 可在多个节点上运行,所以可以使用它来处理大量输入数据,并将这些数据简化为更实用的信息块。此过程可使用一个简单的 MapReduce 系统来处理。
MapReduce 转换传入信息(不一定为结构化格式),将该信息转换为一种可更轻松地使用、查询和处理的结构。
例如,一种典型的用途是处理来自数百个不同应用程序的日志信息,以便可以识别特定的问题、计数或其他事件。通过使用 MapReduce 格式,您可以开始度量并查找趋势,将平常非常多的信息转换为更小的数据块。举例而言,在查看某个 Web 服务器的日志时,您可能希望查看特定页面上的特定范围中发生的错误。您可以编写一个 MapReduce 函数来识别特定页面上的特定错误,并在输出中生成该信息。使用此方法,您可从日志文件中精减多行信息,得到一个仅包含错误信息的小得多的记录集合。
理解 MapReduce
MapReduce 的工作方式分两个阶段。映射 (map) 过程获取传入信息,并将这些信息映射到某种标准化的格式。对于某些信息类型,此映射可以是直接和显式的。例如,如果要处理 Web 日志等输入数据,那么仅从 Web 日志的文本中提取一列数据即可。对于其他数据,映射可能更复杂。在处理文本信息时,比如研究论文,您可能需要提取短语或更复杂的数据块。
精减 (reduce) 阶段用于收集和汇总数据。精减实际上能够以多种不同方式发生,但典型的过程是处理一个基本计数、总和或其他基于来自映射阶段的个别数据的统计数据。
想象一个简单的示例,比如 Hadoop 中用作示例 MapReduce 的字数,映射阶段将对原始文本进行分解,以识别各个单词,并为每个单词生成一个输出数据块。reduce 函数获取这些映射的信息块,对它们进行精减,以便在所看到的每个惟一单词上进行递增。给定一个包含 100 个单词的文本文件,映射过程将生成 100 个数据块,但精减阶段可对此进行汇总,提供惟一单词的数量(比如 56 个)和每个单词出现的次数。
借助 Web 日志,映射将获取输入数据,为日志文件中的每个错误创建一条记录,然后为每个错误生成一个数据块,其中包含日期、时间和导致该问题的页面。
在 Hadoop 内,MapReduce 阶段会出现在存储各个源信息块的各个节点上。这使 Hadoop 能够处理以下大型信息集:通过允许多个节点同时处理数据。例如,对于 100 个节点,可以同时处理 100 个日志文件,比通过单个节点快得多地简化许多 GB(或 TB)的信息。
Hadoop 信息
核心 Hadoop 产品的一个主要限制是,无法在数据库中存储和查询信息。数据添加到 HDFS 系统中,但您无法要求 Hadoop 返回与某个特定数据集匹配的所有数据的列表。主要原因是 Hadoop 不会存储、结构化或理解存储在 HDFS 中的数据的结构。这正是 MapReduce 系统需要将信息分析并处理为更加结构化的格式的原因。
但是,我们可以将 Hadoop 的处理能力与更加传统的数据库相结合,使我们可以查询 Hadoop 通过自己的 MapReduce 系统生成的数据。可能的解决方案有许多,其中包括一些传统 SQL 数据库,但我们可以通过使用 Couchbase Server 来保持 MapReduce 风格(它对大型数据集非常有效)。
系统之间的数据共享的基本结构如图 1所示。
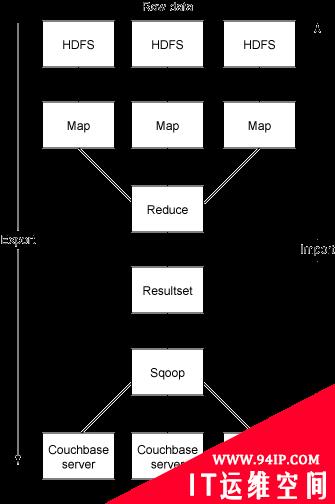
图 1. 系统之间的数据共享的基本结构#p#
安装 Hadoop
如果您尚未安装 Hadoop,最简单的方法是使用一个 Cloudera 安装。为了保持 Hadoop、Sqoop 和 Couchbase 之间的兼容性,***的解决方案是使用 CDH3 安装(参阅参考资料)。为此,您需要使用 Ubuntu 10.10 到 11.10 版。更高的 Ubuntu 版本会引入不兼容问题,因为它们不再支持 Cloudera Hadoop 安装所需的一个包。
在安装之前,请确保已经安装了一个 Java™ 虚拟机,确保在 JAVA_HOME 变量中为 JDK 配置了正确的主目录。请注意,您必须拥有完整的 Java 开发工具包,而不只是拥有 Java 运行时环境 (JRE),因为 Sqoop 将代码编译为 Couchbase Server 与 Hadoop 之间的导出和导入数据。
要在 Ubuntu 和类似的系统上使用 CDH3 安装,您需要执行以下步骤:
1、下载 CDH3 配置包。这会将 CDH3 源文件的配置添加到 apt 存储库中。
2、更新您的存储库缓存:$ apt-get update。
3、。安装主要 Hadoop 包:$ apt-get install hadoop-0.20。
4、安装 Hadoop 组件(参见 清单 1)
清单 1. 安装 Hadoop 组件
$ for comp in namenode datanode secondarynamenode jobtracker tasktracker do apt-get install hadoop-0.20-$comp done
5、编辑配置文件,以确保您设置了核心组件。
6、编辑 /etc/hadoop/conf/core-site.xml,使其如 清单 2 所示。
清单 2. 编辑后的 /etc/hadoop/conf/core-site.xml 文件
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
这将配置存储数据的默认 hdfs 位置。
编辑 /etc/hadoop/conf/hdfs-site.xml(参见 清单 3)。
清单 3. 编辑后的 /etc/hadoop/conf/hdfs-site.xml 文件
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
这支持复制存储的数据。
编辑 /etc/hadoop/conf/mapred-site.xml(参见 清单 4)。
清单 4. 编辑后的 /etc/hadoop/conf/mapred-site.xml 文件
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
这实现了 MapReduce 的作业跟踪器。
7、***,编辑 Hadoop 环境,使其正确地指向 /usr/lib/hadoop/conf/hadoop-env.sh 中您的 JDK 安装目录。其中会有一个注释掉的 JAVA_HOME 变量行。您应该取消注释它,并将它设置为您的 JDK 位置。例如:export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk。
8、现在,在您的系统上启动 Hadoop。最简单的方法是使用 start-all.sh 脚本:$ /usr/lib/hadoop/bin/start-all.sh。
假设所有设置均已正确配置,您现在应有一个正在运行的 Hadoop 系统。#p#
Couchbase Server 概述
Couchbase Server 是一个集群化的、基于文档的数据库系统,它使用一个缓存层来提供非常快的数据访问,将大部分数据都存储在 RAM 中。该系统使用多个节点和一个自动分散在整个集群上的缓存层。这实现了一种弹性,您可扩大和紧缩集群,以便利用更多 RAM 或磁盘 I/O 来帮助提升性能。
Couchbase Server 中的所有数据最终会持久存储在磁盘中,但最初会通过缓存层执行写入和更新操作,这正是提供高性能的源泉,是我们通过处理 Hadoop 数据来获得实时信息和查询内容时可利用的优势。
Couchbase Server 的基本形式是一个基本文档和基于键/值的存储。只有在您知道文档 ID 时,才能检索集群提供的信息。在 Couchbase Server 2.0 中,您可以将文档存储为 JSON 格式,然后使用视图系统在存储的 JSON 文档上创建一个视图。视图是在存储在数据库中的文档上执行的一个 MapReduce 组合。来自视图的输出是一个索引,它通过 MapReduce 函数来匹配您定义的结构。索引的存在为您提供了查询底层的文档数据的能力。
我们可以使用此功能从 Hadoop 获取已处理的信息,将该信息存储在 Couchbase Server 中,然后使用它作为查询该数据的基础。Couchbase Server 可以方便地使用一个 MapReduce 系统来处理文档和创建索引。这在用于处理数据的方法之间提供了一定的兼容性和一致性水平。
安装 Couchbase Server
安装 Couchbase Server 很容易。从 Couchbase 网站下载适合您平台的 Couchbase Server 2.0 版本(参见 参考资料),使用 dpkg 或 RPM(具体依赖于您的平台)安装该包。
安装之后,Couchbase Server 会自动启动。要配置它,请打开一个 Web 浏览器,并将它指向您的机器的 localhost:8091(或使用该机器的 IP 地址远程访问它)。
按照屏幕上的配置说明进行操作。您可使用在安装期间提供的大部分默认设置,但最重要的设置是写入数据库中的数据的数据文件的位置,以及您分配给 Couchbase Server 的 RAM 量。#p#
使 Couchbase Server 能够与 Hadoop 连接器通信
Couchbase Server 使用 Sqoop 连接器与您的 Hadoop 集群通信。Sqoop 提供了一个连接在 Hadoop 与 Couchbase Server 之间批量传输数据。
从技术上讲,Sqoop 是一个设计用于在结构化数据库与 Hadoop 之间转换信息的应用程序。Sqoop 这个名称实际上来源于 SQL 和 Hadoop。
安装 Sqoop
如果使用 CDH3 安装,您可使用报管理器来安装 Sqoop:$ sudo apt-get install sqoop。
这将把 Sqoop 安装在 /usr/lib/sqoop 中。
注意:Sqoop 中一个***的 bug 表明它有时会尝试传输uowu的数据集。修补程序包含在 Sqoop 1.4.2 版中。如果遇到问题,请尝试使用 V1.4.2 或更高的版本。
安装 Couchbase Hadoop Connector
Couchbase Hadoop Connector 是一个支持 Sqoop 与 Couchbase 之间的连接的 Java jar 文件集合。从 Couchbase 网站下载 Hadoop 连接器(参阅 参考资料)。该文件封装为一个 zip 文件。解压它,然后运行其中的 install.sh 脚本,提供 Sqoop 系统的位置。例如:$ sudo bash install.sh /usr/lib/sqoop。
这将安装所有必要的库和配置文件。现在我们可以开始在两个系统之间交换信息了。
将数据从 Couchbase Server 导入 Hadoop
尽管该场景不是我们这里将直接处理的场景,但需要注意我们可从 Couchbase Server 将数据导入 Hadoop。如果您在 Couchbase Server 中加载了大量数据,并希望利用 Hadoop 来处理和简化它,这可能很有用。为此,您可以使用以下命令,从 Couchbase Server 将整个数据集加载到 HDFS 中的一个 Hadoop 文件中:$ sqoop import –connect http://192.168.0.71:8091/pools –table cbdata。
这里提供的 URL 是 Couchbase Server 桶池 (bucket pool) 的位置。这里指定的表实际上是 HDFS 中将存储数据的目录的名称。
数据本身被存储为来自 Couchbase Server 的信息的一种键/值转储形式。在 Couchbase Server 2.0 中,这意味着数据是使用惟一文档 ID 写出的,包含记录的 JSON 值。
将 JSON 数据写入 Hadoop MapReduce
要在 Hadoop 与 Couchbase Server 之间交换信息,需要使用一种通用语言来表达这些信息,在本例中使用的是 JSON(参见 清单 5)。
清单 5. 在 Hadoop MapReduce 中输出 JSON
package org.mcslp;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
import com.google.gson.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable,
Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text,
IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text,
IntWritable, Text, Text> {
class wordRecord {
private String word;
private int count;
wordRecord() {
}
}
public void reduce(Text key,
Iterator<IntWritable> values,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
wordRecord word = new wordRecord();
word.word = key.toString();;
word.count = sum;
Gson json = new Gson();
System.out.println(json.toJson(word));
output.collect(key, new Text(json.toJson(word)));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
该代码是 Hadoop 发行版所提供的字数示例的修改版。
此版本使用 Google Gson 库从处理过程的精减阶段写入 JSON 信息。为了方便起见,我们使用了一个新类 (wordRecord),它由 Gson 转换为一条 JSON 记录,这种记录是 Couchbase Server 逐个文档地处理和解析内容所需的格式。
请注意,我们没有为 Hadoop 定义一个 Combiner 类。这将阻止 Hadoop 尝试重新精减该信息,该操作在当前的代码中会失败,因为我们的精减阶段仅接收该单词和一位数,并输出一个 JSON 值。对于辅助的精减/组合阶段,我们需要解析 JSON 输入或定义一个新 Combiner 类,以便输出信息的 JSON 版本。这稍微简化了定义。
要在 Hadoop 中使用此代码,首先需要将 Google Gson 库复制到 Hadoop 目录中 (/usr/lib/hadoop/lib)。然后重新启动 Hadoop,以确保 Hadoop 已经正确识别出该库。
接下来,将您的代码编译到一个目录中: $ javac -classpath ${HADOOP_HOME}/hadoop-${HADOOP_VERSION}-core.jar:./google-gson-2.2.1/gson-2.2.1.jar -d wordcount_classes WordCount.java 。
现在为您的库创建一个 jar 文件: $ jar -cvf wordcount.jar -C wordcount_classes/。
完成此过程后,您可以将一些文本文件复制到某个目录中,然后使用此 jar 文件将这些文本文件处理为许多独立的单词,创建一条 JSON 记录来包含每个单词和计数。例如,要在一些 Project Gutenberg 文本上处理此数据: $ hadoop jar wordcount.jar org.mcslp.WordCount /user/mc/gutenberg /user/mc/gutenberg-output。
这将在我们的目录中生成已由 Hadoop 内的 MapReduce 函数统计的单词列表。
将数据从 Hadoop 导出到 Couchbase Server
要从 Hadoop 取回数据并导入 Couchbase Server 中,则需要使用 Sqoop 导出该数据: $ sqoop export –connect http://10.2.1.55:8091/pools –table ignored –export-dir gutenberg-output。
此示例中忽略了 –table 参数,但 –export-dir 是要导出的信息所在的目录的名称。#p#
在 Couchbase Server 中编写 MapReduce
在 Hadoop 中,MapReduce 函数是使用 Java 编写的。在 Couchbase Server 中,MapReduce 函数是使用 Javascript 编写的。作为一种已解释的语言,这意味着您不需要编译视图,它会支持您编辑和细化 MapReduce 结构。
要在 Couchbase Server 中创建一个视图,请打开管理控制台(在 http://localhost:8091 上),然后单击 View 按钮。视图收集在一个设计文档中。您可以在单个设计文档中创建多个视图,也可以创建多个设计文档。要提升服务器的总体性能,系统还支持一种可编辑的开发视图以及一个无法编辑的生产视图。生产视图无法编辑是因为这么做会使视图索引无效,并会导致需要重新构建索引。
单击 Create Development View 按钮并命名您的设计文档和视图。
在 Couchbase Server 内,有两个相同的函数:map 和 reduce。map 函数用于将输入数据(JSON 文档)映射到某个表。然后使用 reduce 函数汇总和精减该表。reduce 函数是可选的,不是索引功能所必需的,所以,出于本文的目的,我们将忽略 reduce 函数。
对于 map 函数,函数的格式如 清单 6 所示。
清单 6. map 函数的格式
map(doc) {
}
参数 doc 是每个存储的 JSON 文档。Couchbase Server 的存储格式是一种 JSON 文档,视图是使用 Javascript 语言编写的,所以我们可使用以下语句访问 JSON 中一个名为 count 的字段:doc.count。
要从 map 函数发出信息,可以调用 emit() 函数。emit() 函数接受两个参数,***个是键(用于选择和查询信息),第二个参数是相应的值。因此,我们可以创建一个 map 函数来使用来输出单词和计数,如 清单 7 中的代码所示。
清单 7. 输出单词和计数的 map 函数
function (doc) {
if (doc.word) {
emit(doc.word,doc.count);
}
}
这将为每个输出文档输出一行数据,其中包含文档 ID(实际上是我们的单词)、用作键的单词和该单词在源文本中出现的次数。可在 清单 8 中看到原始的 JSON 输出。
清单 8. 原始的 JSON 输出
{"total_rows":113,"rows":[
{"id":"acceptance","key":"acceptance","value":2},
{"id":"accompagner","key":"accompagner","value":1},
{"id":"achieve","key":"achieve","value":1},
{"id":"adulteration","key":"adulteration","value":1},
{"id":"arsenic","key":"arsenic","value":2},
{"id":"attainder","key":"attainder","value":1},
{"id":"beerpull","key":"beerpull","value":2},
{"id":"beware","key":"beware","value":5},
{"id":"breeze","key":"breeze","value":2},
{"id":"brighteyed","key":"brighteyed","value":1}
]
}
在输出中,id 是文档 ID,key 是您在 emit 语句中指定的键,value 是在 emit 语句中指定的值。
获取实时数据
现在我们已在 Hadoop 中处理了信息,请将它导入 Couchbase Server 中,然后在 Couchbase Server 中为该数据创建了一个视图,我们可以开始查询已处理和存储的信息了。视图可使用一个 REST 样式的 API 来访问,或者在使用一个 Couchbase Server SDK 时,通过相应的视图查询函数来访问它。
查询可通过 3 种主要选择来执行:
单独的键。例如,显示与某个特定键(比如 ‘unkind’)匹配的信息。
键列表。您可提供一个键值数组,这将返回其键值与一个提供的值匹配的所有记录。例如,[‘unkind’,’kind’] 将返回与其中一个单词匹配的记录。
键范围。您可指定一个开始和结束键。
例如,要找到一个指定的单词的数量,可使用 key 参数进行查询:
http://192.168.0.71:8092/words/_design/dev_words/_view/byword?connection_timeout= 60000&limit=10&skip=0&key=%22breeze%22
Couchbase Server 会很自然地采用 UTF-8 排序方式输出一个 MapReduce 的按指定的键排序的结果。这意味着您可以通过指定开始值和结束值来获取一个值范围。例如,要获取 ‘breeze’ 与 ‘kind’ 之间的所有单词,可使用:
http://192.168.0.71:8092/words/_design/dev_words/_view/byword?connection_timeout= 60000&limit=10&skip=0&startkey=%22breeze%22&endkey=%22kind%22
该查询很简单,但非常强大,尤其是在您认识到可以将它与灵活的视图系统结合使用,生成具有您想要的格式的数据的时候。
结束语
Hadoop 本身提供了一个强大的处理平台,但没有提供从已处理的数据中实际提取有用信息的方法。通过将 Hadoop 连接到另一个系统,可使用该系统来查询和提取信息。因为 Hadoop 使用 MapReduce 进行相关处理,所以您可以通过 Couchbase Server 中的 MapReduce 系统,利用 MapReduce 的知识来提供查询平台。使用此方法,您可以在 Hadoop 中处理数据,以 JSON 文档格式将数据从 Hadoop 导出到 Couchbase Server 中,然后在 Couchbase Server 中使用 MapReduce 查询已处理的信息。
转载请注明:IT运维空间 » 运维技术 » Hadoop和Couchbase结合使用的技巧
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/5.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论