

【2013年12月12日 外电头条】Hadoop已经通过自身的蓬勃发展证明,它不仅仅是一套用于将工作内容传播到计算机群组当中的小型堆栈–不,这与它的潜能相比简直微不足道。这套核心的价值已经被广泛证实,目前大量项目如雨后春笋般围绕它建立起来。有些项目负责数据管理、有些负责流程监控、还有一些则提供先进的数据存储机制。

Hadoop业界正在迅速发展,从业企业拿出的解决方案也多种多样,其中包括提供技术支持、在托管集群中提供按时租用服务、为这套开源核心开发先进的功能强化或者将自有工具添加到方案组合当中。
在今天的文章中,我们将一同了解当下Hadoop生态系统当中那些最为突出的杰作。总体而言,这是一套由众多工具及代码构成的坚实基础、共同聚集在"Hadoop"这面象征着希望的大旗之下。
Hadoop

虽然很多人会把映射与规约工具广义化称为Hadoop,但从客观角度讲、其实只有一小部分核心代码算是真正的Hadoop。多个工作节点负责对保存在本地的数据进行功能执行,而基于Java的代码则对其加以同步。这些工作节点得到的结果随后经过汇总并整理为报告。第一个步骤被称为"映射(即map)",而第二步骤则被称为"规约(reduce)"。
Hadoop为本地数据存储与同步系统提供一套简化抽象机制,从而保证程序员能够将注意力集中在编写代码以实现数据分析工作上,其它工作交给Hadoop处理即可。Hadoop会将任务加以拆分并设计执行规程。错误或者故障在意料之中,Hadoop的设计初衷就在于适应由单独设备所引发的错误。
项目代码遵循Apache许可机制。
官方网站:hadoop.apache.org
Ambari
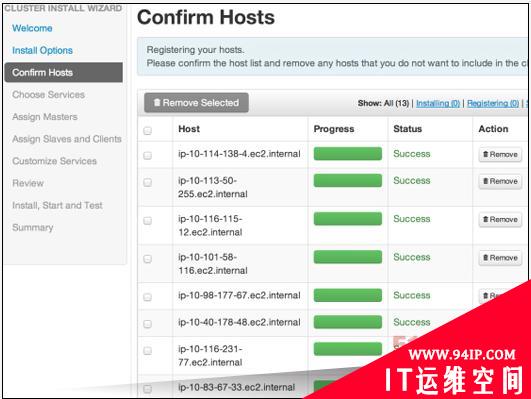
Hadoop集群的建立需要涉及大量重复性工作。Ambari提供一套基于Web的图形用户界面并配备引导脚本,能够利用大部分标准化组件实现集群设置。在大家采纳Ambari并将其付诸运行之后,它将帮助各位完成配置、管理以及监管等重要的Hadoop集群相关任务。上图显示的就是集群启动后Ambari所显示的信息屏幕。
Ambari属于Apache旗下的衍生项目,并由Hortonworks公司负责提供支持。
下载地址:http://incubator.apache.org/ambari/
HDFS (即Hadoop分布式文件系统)
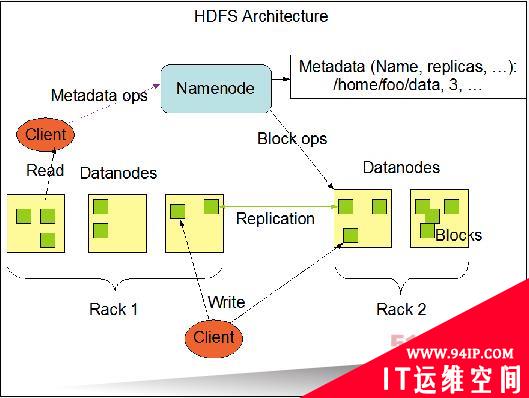
Hadoop分布式文件系统提供一套基础框架,专门用于拆分收集自不同节点之间的数据,并利用复制手段在节点故障时实现数据恢复。大型文件会被拆分成数据块,而多个节点能够保留来自同一个文件的所有数据块。上图来自Apache公布的说明文档,旨在展示数据块如何分布至各个节点当中。
这套文件系统的设计目的在于同时实现高容错性与高数据吞吐能力的结合。加载数据块能够保持稳定的信息流通,而低频率缓存处理则将延迟降至最小。默认模式假设的是需要处理大量本地存储数据的长时间作业,这也吻合该项目所提出的"计算能力迁移比数据迁移成本更低"的座右铭。
HDFS同样遵循Apache许可。
官方网站:hadoop.apache.org
HBase
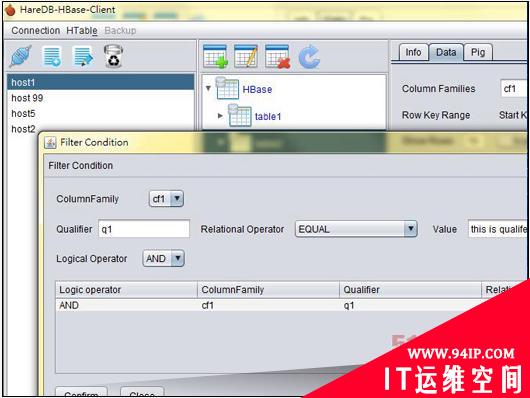
当数据被汇总成一套规模庞大的列表时,HBase将负责对其进行保存、搜索并自动在不同节点之间共享该列表,从而保证MapReduce作业能够以本地方式运行。即使列表中容纳的数据行数量高达数十亿,该作业的本地版本仍然能够对其进行查询。
该代码并不能提供其它全功能数据库所遵循的ACID保证,但它仍然为我们带来一部分关于本地变更的承诺。所有衍生版本的命运也都维系在一起–要么共同成功、要么一起失败。
这套系统通常被与谷歌的BigTable相提并论,上图所示为来自HareDB(一套专为HBase打造的图形用户界面客户端)的截图。
官方网站:hbase.apache.org
#p#
Hive

将数据导入集群还只是大数据分析的第一步。接下来我们需要提取HBase中来自文件的所有数据内容,而Hive的设计初衷在于规范这一提取流程。它提供一套SQL类语言,用于深入发掘文件内容并提取出代码所需要的数据片段。这样一来,所有结果数据就将具备标准化格式,而Hive则将其转化为可直接用于查询的存储内容。
上图所示为Hive代码,这部分代码的作用在于创建一套列表、向其中添加数据并选择信息。
Hive由Apache项目负责发行。
官方网站:hive.apache.org
Sqoop
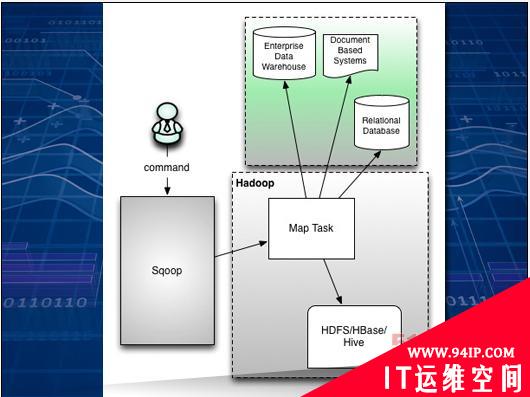
要将蕴藏在SQL数据库中的数据宝库发掘出来并交给Hadoop打理需要进行一系列调整与操作。Sqoop负责将饱含信息的大型列表从传统数据库中移动到Hive或者HBase等工具的控制之下。
Sqoop是一款命令行工具,能够控制列表与数据存储层之间的映射关系,并将列表转化为可为HDFS、HBase或者Hive所接纳的可配置组合。上图所示为Apache文档材料中的内容,可以看到Sqoop位于传统库与节点上的Hadoop结构之间。
Sqoop的最新稳定版本为1.4.4,但目前其2.0版本同样进展顺利。两个版本目前都可供下载,且遵循Apache许可。
官方网站:sqoop.apache.org
Pig
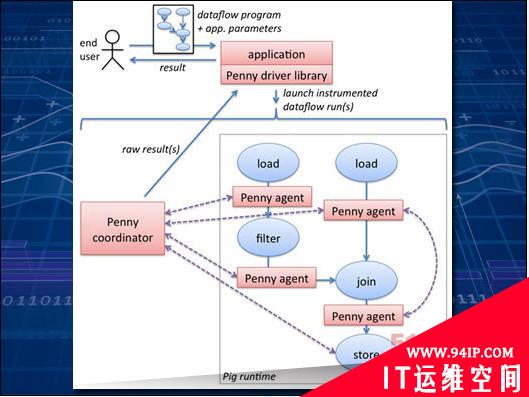
一旦数据以Hadoop能够识别的方式被保存在节点当中,有趣的分析工作将由此展开。Apache的Pig会用自己的小"猪拱"梳理数据,运行利用自有语言(名为Pig Latin)所编写的代码,并添加处理数据所需要的各种抽象机制。这样的结构会一步步指引用户走向那些易于以并行方式运行在整个集群当中的算法。
Pig还拥有一系列针对常见任务的标准化功能,能够轻松处理诸如数据平均值计算、日期处理或者字符串差异比较等工作。如果这些还不够用–实际上一般都不够用–大家还可以动手编写属于自己的功能。上图所示为Apache说明文档中的一项实例,解释了用户如何将自己的代码与Pig代码结合起来、从而实现数据发掘。
目前Pig的最新版本为0.12.0。
官方网站:pig.apache.org
ZooKeeper
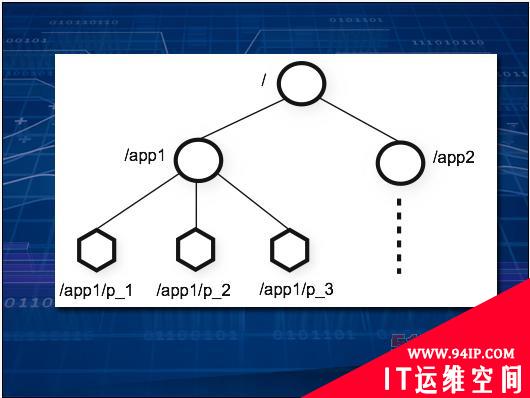
一旦Hadoop需要在大量设备之上,集群运作的顺序就显得非常重要,特别是在其中某些设备开始签出的情况下。
ZooKeeper在集群中强制执行一套文件系统式的层级结构,并为设备保存所有元数据,这样我们就可以在不同设备之间进行作业同步。(上图所示为一套简单的二层式集群。)说明文档展示了如何在数据处理流程中实施多种标准化技术,例如生产方-消费方队列,从而保证数据能够以正确的顺序进行拆分、清理、筛选以及分类。当上述过程结束后,使用ZooKeeper的节点会彼此通信、并以最终生成的数据为起点开始分析工作。
如果大家希望了解
转载请注明:IT运维空间 » 运维技术 » 十八款Hadoop工具帮你驯服大数据
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/5.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值










发表评论