


大家好久不见了,最近生活发生了很多变故,同时我也大病了一场,希望一切都尽快好起来吧。今天跟大家分享下Spark吧,谈谈如何修改Spark SQL解析,让其更符合你的业务逻辑。好,我们开始吧…
理论基础
ANTLR
Antlr4是一款开源的语法分析器生成工具,能够根据语法规则文件生成对应的语法分析器。现在很多流行的应用和开源项目里都有使用,比如Hadoop、Hive以及Spark等都在使用ANTLR来做语法分析。
ANTLR 语法识别一般分为二个阶段:
1.词法分析阶段 (lexical analysis)
对应的分析程序叫做 lexer ,负责将符号(token)分组成符号类(token class or token type)
2.解析阶段
根据词法,构建出一棵分析树(parse tree)或叫语法树(syntax tree)
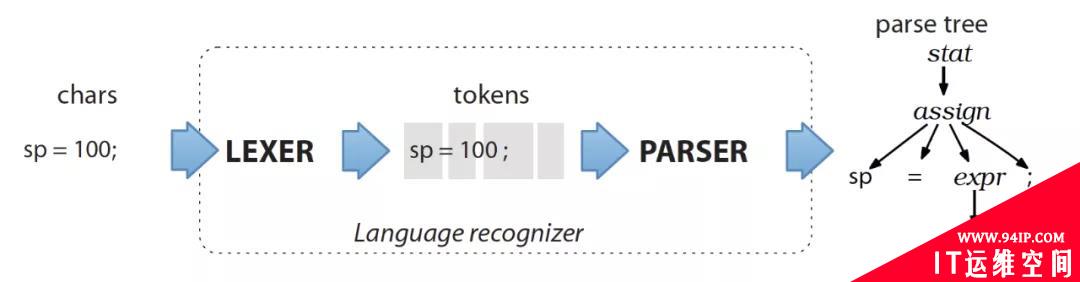
ANTLR的语法文件,非常像电路图,从入口到出口,每个Token就像电阻,连接线就是短路点。
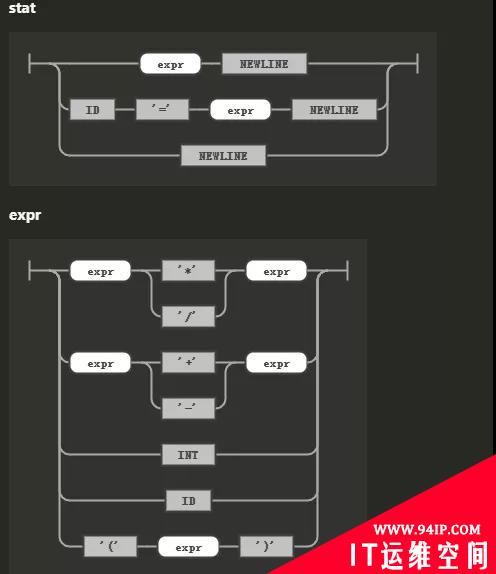
语法文件(*.g4)
上面截图对应的语法文件片段,定义了两部分语法,一部分是显示表达式和赋值,另外一部分是运算和表达式定义。
stat:exprNEWLINE#printExpr
|ID'='exprNEWLINE#assign
|NEWLINE#blank
;
expr:exprop=('*'|'/')expr#MulDiv
|exprop=('+'|'-')expr#AddSub
|INT#int
|ID#id
|'('expr')'#parens
;
接下来,加上定义词法部分,就能形成完整的语法文件。
完整语法文件:
grammarLabeledExpr;//renametodistinguishfromExpr.g4
prog:stat+;
stat:exprNEWLINE#printExpr
|ID'='exprNEWLINE#assign
|NEWLINE#blank
;
expr:exprop=('*'|'/')expr#MulDiv
|exprop=('+'|'-')expr#AddSub
|INT#int
|ID#id
|'('expr')'#parens
;
MUL:'*';//assignstokennameto'*'usedaboveingrammar
DIV:'/';
ADD:'+';
SUB:'-';
ID:[a-zA-Z]+;//matchidentifiers
INT:[0-9]+;//matchintegers
NEWLINE:'\r'?'\n';//returnnewlinestoparser(isend-statementsignal)
WS:[\t]+->skip;//tossoutwhitespace
SqlBase.g4
Spark的语法文件,在sql下的catalyst模块里,如下图:
扩展语法定义
一条正常SQL,例如 Select t.id,t.name from t , 现在我们为其添加一个 JACKY表达式,令其出现在 Select 后面 ,形成一条语句
Selectt.id,t.nameJACKY(2)fromt
我们先看一下正常的语法规则:

现在我们添加一个 jackyExpression
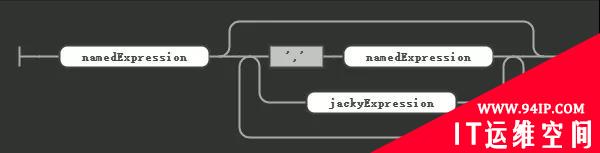
jackExpression 本身的规则就是 JACKY加上括号包裹的一个数字

将 JACKY 添加为token

修改语法文件 如下:
jackyExpression
:JACKY'('number')'
//expression
;
namedExpression
:expression(AS?(identifier|identifierList))?
;
namedExpressionSeq
:namedExpression(','namedExpression|jackyExpression)*
;
扩展逻辑计划
经过上面的修改,就可以测试语法规则,是不是符合预期了,下面是一颗解析树,我们可以看到jackyExpression已经可以正常解析了。
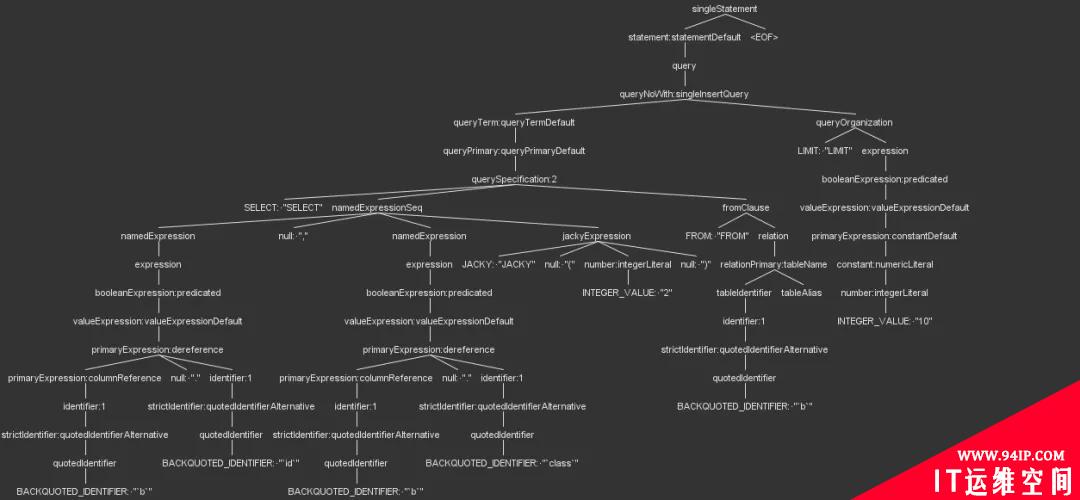
Spark 执行流程
这里引用一张经典的Spark SQL架构图
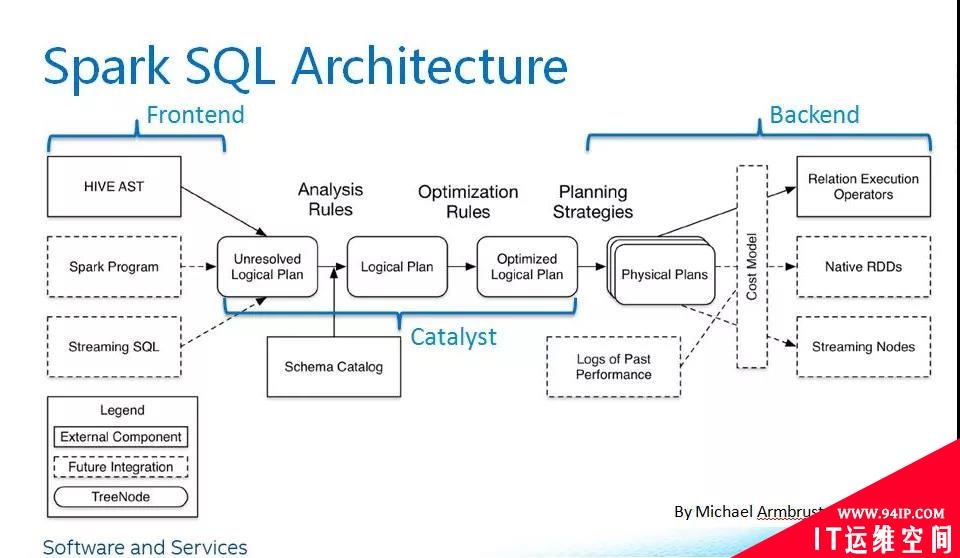
我们输入的 SQL语句 首先被解析成 Unresolved Logical Pan ,对应的是
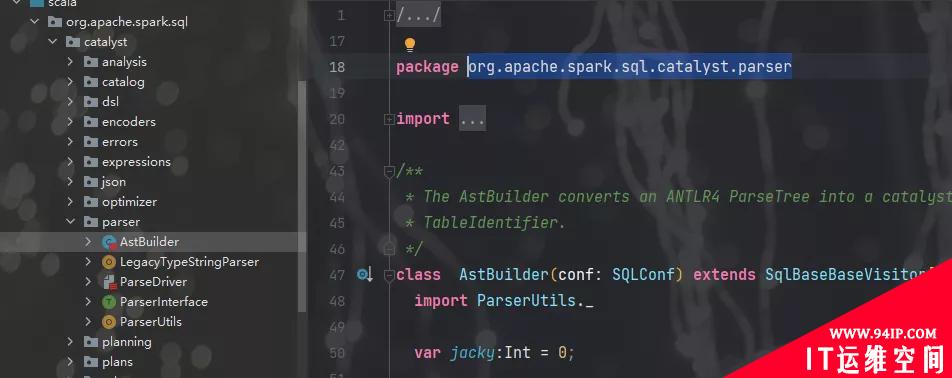
给逻辑计划添加遍历方法:
overridedefvisitJackyExpression(ctx:JackyExpressionContext):String=withOrigin(ctx){
println("thisisastbuilderjacky="+ctx.number().getText)
this.jacky=ctx.number().getText.toInt
ctx.number().getText
}
再处理namedExpression的时候,添加jackyExpression处理
//Expressions.
valexpressions=Option(namedExpressionSeq).toSeq
.flatMap(_.namedExpression.asScala)
.map(typedVisit[Expression])
//jackyExpression处理
if(namedExpressionSeq().jackyExpression()!=null&&namedExpressionSeq().jackyExpression().size()>0){
visitJackyExpression(namedExpressionSeq().jackyExpression().get(0))
}
好了,到这里从逻辑计划处理就完成了,有了逻辑计划,就可以在后续物理计划中添加相应的处理逻辑就可以了(还没研究明白… Orz)。
测试
测试用例
publicclassCase4{
publicstaticvoidmain(String[]args){
CharStreamca=CharStreams.fromString("SELECT`b`.`id`,`b`.`class`JACKY(2)FROM`b`LIMIT10");
SqlBaseLexerlexer=newSqlBaseLexer(ca);
SqlBaseParsersqlBaseParser=newSqlBaseParser(newCommonTokenStream(lexer));
ParseTreeparseTree=sqlBaseParser.singleStatement();
AstBuilderastBuilder=newAstBuilder();
astBuilder.visit(parseTree);
System.out.println(parseTree.toStringTree(sqlBaseParser));
System.out.println(astBuilder.jacky());
}
}
执行结果

转载请注明:IT运维空间 » 运维技术 » 扩展 Spark SQL 解析,你知道吗?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论