


简介
最近一个 MongoDB 集群环境中的某节点异常下电了,导致业务出现了中断,随即又恢复了正常。
通过ELK 告警也监测到了业务报错日志。
运维部对于节点下电的原因进行了排查,发现仅仅是资源分配上的一个失误导致。 在解决了问题之后,大家也对这次中断的也提出了一些问题:
"当前的 MongoDB集群 采用了分片副本集的架构,其中主节点发生故障会产生多大的影响?"
"MongoDB 副本集不是能自动倒换吗,这个是不是秒级的?"
带着这些问题,下面针对副本集的自动Failover机制做一些分析。
日志分析
首先可以确认的是,这次掉电的是一个副本集上的主节点,在掉电的时候,主备关系发生了切换。
从另外的两个备节点找到了对应的日志:
备节点1的日志
2019-05-06T16:51:11.766+0800IREPL[ReplicationExecutor]Startinganelection,sincewe'veseennoPRIMARYinthepast10000ms
2019-05-06T16:51:11.766+0800IREPL[ReplicationExecutor]conductingadryrunelectiontoseeifwecouldbeelected
2019-05-06T16:51:11.766+0800IASIO[NetworkInterfaceASIO-Replication-0]Connectingto172.30.129.78:30071
2019-05-06T16:51:11.767+0800IREPL[ReplicationExecutor]VoteRequester(term3dryrun)receivedayesvotefrom172.30.129.7:30071;responsemessage:{term:3,voteGranted:true,reason:"",ok:1.0}
2019-05-06T16:51:11.767+0800IREPL[ReplicationExecutor]dryelectionrunsucceeded,runningforelection
2019-05-06T16:51:11.768+0800IASIO[NetworkInterfaceASIO-Replication-0]Connectingto172.30.129.78:30071
2019-05-06T16:51:11.771+0800IREPL[ReplicationExecutor]VoteRequester(term4)receivedayesvotefrom172.30.129.7:30071;responsemessage:{term:4,voteGranted:true,reason:"",ok:1.0}
2019-05-06T16:51:11.771+0800IREPL[ReplicationExecutor]electionsucceeded,assumingprimaryroleinterm4
2019-05-06T16:51:11.771+0800IREPL[ReplicationExecutor]transitiontoPRIMARY
2019-05-06T16:51:11.771+0800IREPL[ReplicationExecutor]Enteringprimarycatch-upmode.
2019-05-06T16:51:11.771+0800IASIO[NetworkInterfaceASIO-Replication-0]Endingconnectiontohost172.30.129.78:30071duetobadconnectionstatus;2connectionstothathostremainopen
2019-05-06T16:51:11.771+0800IASIO[NetworkInterfaceASIO-Replication-0]Connectingto172.30.129.78:30071
2019-05-06T16:51:13.350+0800IREPL[ReplicationExecutor]Errorinheartbeatrequestto172.30.129.78:30071;ExceededTimeLimit:Couldn'tgetaconnectionwithinthetimelimit
备节点2的日志
2019-05-06T16:51:12.816+0800IASIO[NetworkInterfaceASIO-Replication-0]Endingconnectiontohost172.30.129.78:30071duetobadconnectionstatus;0connectionstothathostremainopen
2019-05-06T16:51:12.816+0800IREPL[ReplicationExecutor]Errorinheartbeatrequestto172.30.129.78:30071;ExceededTimeLimit:Operationtimedout,requestwasRemoteCommand72553--target:172.30.129.78:30071db:adminexpDate:2019-05-06T16:51:12.816+0800cmd:{replSetHeartbeat:"shard0",configVersion:96911,from:"172.30.129.7:30071",fromId:1,term:3}
2019-05-06T16:51:12.821+0800IREPL[ReplicationExecutor]Member172.30.129.160:30071isnowinstatePRIMARY
可以看到,备节点1在 16:51:11 时主动发起了选举,并成为了新的主节点,随即备节点2在 16:51:12 获知了最新的主节点信息,因此可以确认此时主备切换已经完成。
同时在日志中出现的,还有对于原主节点(172.30.129.78:30071)大量心跳失败的信息。
那么,备节点具体是怎么感知到主节点已经 Down 掉的,主备节点之间的心跳是如何运作的,这对数据的同步复制又有什么影响?
下面,我们挖掘一下 ** 副本集的 自动故障转移(Failover)** 机制
副本集 如何实现 Failover
如下是一个PSS(一主两备)架构的副本集,主节点除了与两个备节点执行数据复制之外,三个节点之间还会通过心跳感知彼此的存活。
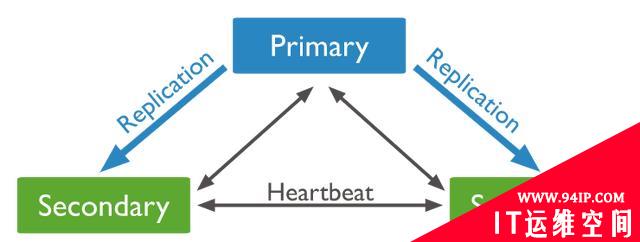
一旦主节点发生故障以后,备节点将在某个周期内检测到主节点处于不可达的状态,此后将由其中一个备节点事先发起选举并最终成为新的主节点。 这个检测周期 由electionTimeoutMillis 参数确定,默认是10s。
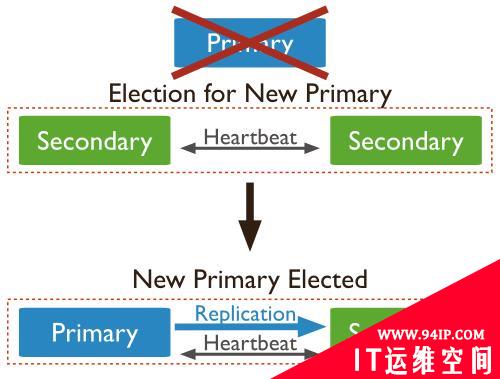
接下来,我们通过一些源码看看该机制是如何实现的:
<<来自 MongoDB 3.4源码>>
db/repl/replication_coordinator_impl_heartbeat.cpp
相关方法
- ReplicationCoordinatorImpl::_startHeartbeats_inlock 启动各成员的心跳
- ReplicationCoordinatorImpl::_scheduleHeartbeatToTarget 调度任务-(计划)向成员发起心跳
- ReplicationCoordinatorImpl::_doMemberHeartbeat 执行向成员发起心跳
- ReplicationCoordinatorImpl::_handleHeartbeatResponse 处理心跳响应
- ReplicationCoordinatorImpl::_scheduleNextLivenessUpdate_inlock 调度保活状态检查定时器
- ReplicationCoordinatorImpl::_cancelAndRescheduleElectionTimeout_inlock 取消并重新调度选举超时定时器
- ReplicationCoordinatorImpl::_startElectSelfIfEligibleV1 发起主动选举
db/repl/topology_coordinator_impl.cpp
相关方法
- TopologyCoordinatorImpl::prepareHeartbeatRequestV1 构造心跳请求数据
- TopologyCoordinatorImpl::processHeartbeatResponse 处理心跳响应并构造下一步Action实例
下面这个图,描述了各个方法之间的调用关系
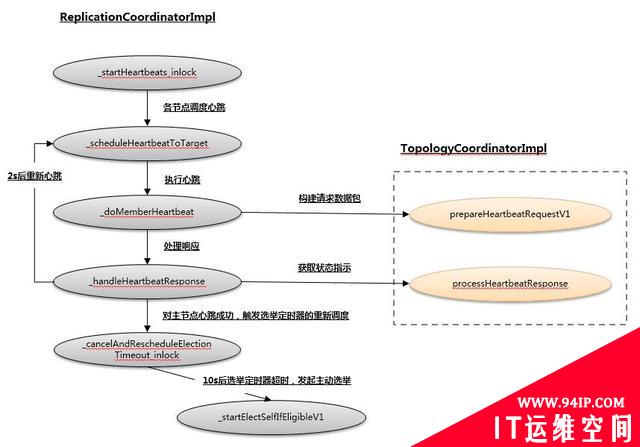
图-主要关系
心跳的实现
首先,在副本集组建完成之后,节点会通过ReplicationCoordinatorImpl::_startHeartbeats_inlock方法开始向其他成员发送心跳:
voidReplicationCoordinatorImpl::_startHeartbeats_inlock(){
constDate_tnow=_replExecutor.now();
_seedList.clear();
//获取副本集成员
for(inti=0;i<_rsConfig.getNumMembers();++i){
if(i==_selfIndex){
continue;
}
//向其他成员发送心跳
_scheduleHeartbeatToTarget(_rsConfig.getMemberAt(i).getHostAndPort(),i,now);
}
//仅仅是刷新本地的心跳状态数据
_topCoord->restartHeartbeats();
//使用V1的选举协议(3.2之后)
if(isV1ElectionProtocol()){
for(auto&&slaveInfo:_slaveInfo){
slaveInfo.lastUpdate=_replExecutor.now();
slaveInfo.down=false;
}
//调度保活状态检查定时器
_scheduleNextLivenessUpdate_inlock();
}
}
在获得当前副本集的节点信息后,调用_scheduleHeartbeatToTarget方法对其他成员发送心跳,
这里_scheduleHeartbeatToTarget 的实现比较简单,其真正发起心跳是由 _doMemberHeartbeat 实现的,如下:
voidReplicationCoordinatorImpl::_scheduleHeartbeatToTarget(constHostAndPort&target,
inttargetIndex,
Date_twhen){
//执行调度,在某个时间点调用_doMemberHeartbeat
_trackHeartbeatHandle(
_replExecutor.scheduleWorkAt(when,
stdx::bind(&ReplicationCoordinatorImpl::_doMemberHeartbeat,
this,
stdx::placeholders::_1,
target,
targetIndex)));
}
ReplicationCoordinatorImpl::_doMemberHeartbeat 方法的实现如下:
voidReplicationCoordinatorImpl::_doMemberHeartbeat(ReplicationExecutor::CallbackArgscbData,
constHostAndPort&target,
inttargetIndex){
LockGuardtopoLock(_topoMutex);
//取消callback跟踪
_untrackHeartbeatHandle(cbData.myHandle);
if(cbData.status==ErrorCodes::CallbackCanceled){
return;
}
constDate_tnow=_replExecutor.now();
BSONObjheartbeatObj;
Millisecondstimeout(0);
//3.2以后的版本
if(isV1ElectionProtocol()){
conststd::pair<ReplSetHeartbeatArgsV1,Milliseconds>hbRequest=
_topCoord->prepareHeartbeatRequestV1(now,_settings.ourSetName(),target);
//构造请求,设置一个timeout
heartbeatObj=hbRequest.first.toBSON();
timeout=hbRequest.second;
}else{
...
}
//构造远程命令
constRemoteCommandRequestrequest(
target,"admin",heartbeatObj,BSON(rpc::kReplSetMetadataFieldName<<1),nullptr,timeout);
//设置远程命令回调,指向_handleHeartbeatResponse方法
constReplicationExecutor::RemoteCommandCallbackFncallback=
stdx::bind(&ReplicationCoordinatorImpl::_handleHeartbeatResponse,
this,
stdx::placeholders::_1,
targetIndex);
_trackHeartbeatHandle(_replExecutor.scheduleRemoteCommand(request,callback));
}
上面的代码中存在的一些细节:
- 心跳的超时时间,在_topCoord.prepareHeartbeatRequestV1方法中就已经设定好了
- 具体的算法就是:
**hbTimeout=_rsConfig.getHeartbeatTimeoutPeriodMillis()-alreadyElapsed**
其中heartbeatTimeoutPeriodMillis是可配置的参数,默认是10s, 那么alreadyElapsed是指此前连续心跳失败(最多2次)累计的消耗时间,在心跳成功响应或者超过10s后alreadyElapsed会置为0。因此可以判断,随着心跳失败次数的增加,超时时间会越来越短(心跳更加密集)
心跳执行的回调,指向自身的_handleHeartbeatResponse方法,该函数实现了心跳响应成功、失败(或是超时)之后的流程处理。
ReplicationCoordinatorImpl::_handleHeartbeatResponse方法的代码片段:
voidReplicationCoordinatorImpl::_handleHeartbeatResponse(
constReplicationExecutor::RemoteCommandCallbackArgs&cbData,inttargetIndex){
LockGuardtopoLock(_topoMutex);
//removehandlefromqueuedheartbeats
_untrackHeartbeatHandle(cbData.myHandle);
...
//响应成功后
if(responseStatus.isOK()){
networkTime=cbData.response.elapsedMillis.value_or(Milliseconds{0});
constauto&hbResponse=hbStatusResponse.getValue();
//只要primary心跳响应成功,就会重新调度electionTimeout定时器
if(hbResponse.hasState()&&hbResponse.getState().primary()&&
hbResponse.getTerm()==_topCoord->getTerm()){
//取消并重新调度electionTimeout定时器
cancelAndRescheduleElectionTimeout();
}
}
...
//调用topCoord的processHeartbeatResponse方法处理心跳响应状态,并返回下一步执行的Action
HeartbeatResponseActionaction=_topCoord->processHeartbeatResponse(
now,networkTime,target,hbStatusResponse,lastApplied);
...
//调度下一次心跳,时间间隔采用action提供的信息
_scheduleHeartbeatToTarget(
target,targetIndex,std::max(now,action.getNextHeartbeatStartDate()));
//根据Action执行处理
_handleHeartbeatResponseAction(action,hbStatusResponse,false);
}
这里省略了许多细节,但仍然可以看到,在响应心跳时会包含这些事情的处理:
对于主节点的成功响应,会重新调度 electionTimeout定时器(取消之前的调度并重新发起)
通过_topCoord对象的processHeartbeatResponse方法解析处理心跳响应,并返回下一步的Action指示
根据Action 指示中的下一次心跳时间设置下一次心跳定时任务
处理Action指示的动作
那么,心跳响应之后会等待多久继续下一次心跳呢? 在 TopologyCoordinatorImpl::processHeartbeatResponse方法中,实现逻辑为:
如果心跳响应成功,会等待heartbeatInterval,该值是一个可配参数,默认为2s;
如果心跳响应失败,则会直接发送心跳(不等待)。
代码如下:
HeartbeatResponseActionTopologyCoordinatorImpl::processHeartbeatResponse(...){
...
constMillisecondsalreadyElapsed=now-hbStats.getLastHeartbeatStartDate();
Date_tnextHeartbeatStartDate;
//计算下一次心跳启动时间
//numFailuresSinceLastStart对应连续失败的次数(2次以内)
if(hbStats.getNumFailuresSinceLastStart()<=kMaxHeartbeatRetries&&
alreadyElapsed<_rsConfig.getHeartbeatTimeoutPeriod()){
//心跳失败,不等待,直接重试心跳
nextHeartbeatStartDate=now;
}else{
//心跳成功,等待一定间隔后再次发送(一般是2s)
nextHeartbeatStartDate=now+heartbeatInterval;
}
...
//决定下一步的动作,可能发生tackover(本备节点优先级更高,且数据与主节点一样新时)
HeartbeatResponseActionnextAction;
if(_rsConfig.getProtocolVersion()==0){
...
}else{
nextAction=_updatePrimaryFromHBDataV1(memberIndex,originalState,now,myLastOpApplied);
}
nextAction.setNextHeartbeatStartDate(nextHeartbeatStartDate);
returnnextAction;
}
electionTimeout 定时器
至此,我们已经知道了心跳实现的一些细节,默认情况下副本集节点会每2s向其他节点发出心跳(默认的超时时间是10s)。
如果心跳成功,将会持续以2s的频率继续发送心跳,在心跳失败的情况下,则会立即重试心跳(以更短的超时时间),一直到心跳恢复成功或者超过10s的周期。
那么,心跳失败是如何触发主备切换的呢,electionTimeout 又是如何发挥作用?
在前面的过程中,与electionTimeout参数相关两个方法如下,它们也分别对应了单独的定时器:
ReplicationCoordinatorImpl::_scheduleNextLivenessUpdate_inlock 发起保活状态检查定时器
ReplicationCoordinatorImpl::_cancelAndRescheduleElectionTimeout_inlock 重新发起选举超时定时器
第一个是 _scheduleNextLivenessUpdate_inlock这个函数,它的作用在于保活状态检测,如下:
voidReplicationCoordinatorImpl::_scheduleNextLivenessUpdate_inlock(){
//仅仅支持3.2+
if(!isV1ElectionProtocol()){
return;
}
//earliestDate取所有节点中更新时间最早的(以尽可能早的发现问题)
//electionTimeoutPeriod默认为10s
autonextTimeout=earliestDate+_rsConfig.getElectionTimeoutPeriod();
//设置超时回调函数为_handleLivenessTimeout
autocbh=_scheduleWorkAt(nextTimeout,
stdx::bind(&ReplicationCoordinatorImpl::_handleLivenessTimeout,
this,
stdx::placeholders::_1));
}
因此,在大约10s后,如果没有什么意外,_handleLivenessTimeout将会被触发,如下:
voidReplicationCoordinatorImpl::_handleLivenessTimeout(...){
...
for(auto&&slaveInfo:_slaveInfo){
...
//lastUpdate不够新(小于electionTimeout)
if(now-slaveInfo.lastUpdate>=_rsConfig.getElectionTimeoutPeriod()){
...
//在保活周期后仍然未更新节点,置为down状态
slaveInfo.down=true;
//如果当前节点是主,且检测到某个备节点为down的状态,进入memberdown流程
if(_memberState.primary()){
//调用_topCoord的setMemberAsDown方法,记录某个备节点不可达,并获得下一步的指示
//当大多数节点不可见时,这里会获得让自身降备的指示
HeartbeatResponseActionaction=
_topCoord->setMemberAsDown(now,memberIndex,_getMyLastDurableOpTime_inlock());
//执行指示
_handleHeartbeatResponseAction(action,
makeStatusWith<ReplSetHeartbeatResponse>(),
true);
}
}
}
//继续调度下一个周期
_scheduleNextLivenessUpdate_inlock();
}
可以看到,这个定时器主要是用于实现主节点对其他节点的保活探测逻辑:
当主节点发现大多数节点不可达时(不满足大多数原则),将会让自己执行降备
因此,在一个三节点的副本集中,其中两个备节点挂掉后,主节点会自动降备。 这样的设计主要是为了避免产生意外的数据不一致情况产生。
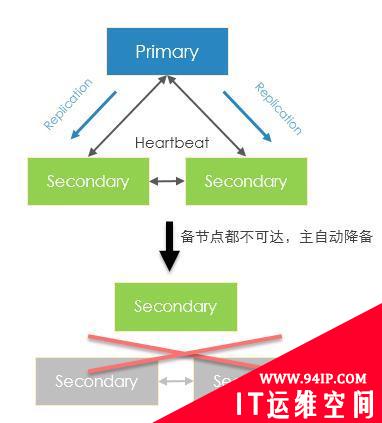
图- 主自动降备
第二个是_cancelAndRescheduleElectionTimeout_inlock函数,这里则是实现自动Failover的关键了,
它的逻辑中包含了一个选举定时器,代码如下:
voidReplicationCoordinatorImpl::_cancelAndRescheduleElectionTimeout_inlock(){
//如果上一个定时器已经启用了,则直接取消
if(_handleElectionTimeoutCbh.isValid()){
LOG(4)<<"Cancelingelectiontimeoutcallbackat"<<_handleElectionTimeoutWhen;
_replExecutor.cancel(_handleElectionTimeoutCbh);
_handleElectionTimeoutCbh=CallbackHandle();
_handleElectionTimeoutWhen=Date_t();
}
//仅支持3.2后的V1版本
if(!isV1ElectionProtocol()){
return;
}
//仅备节点可执行
if(!_memberState.secondary()){
return;
}
...
//是否可以选举
if(!_rsConfig.getMemberAt(_selfIndex).isElectable()){
return;
}
//检测周期,由electionTimeout+randomOffset
//randomOffset是随机偏移量,默认为0~0.15*ElectionTimeoutPeriod=0~1.5s
MillisecondsrandomOffset=_getRandomizedElectionOffset();
autonow=_replExecutor.now();
autowhen=now+_rsConfig.getElectionTimeoutPeriod()+randomOffset;
LOG(4)<<"Schedulingelectiontimeoutcallbackat"<<when;
_handleElectionTimeoutWhen=when;
//触发调度,时间为now+ElectionTimeoutPeriod+randomOffset
_handleElectionTimeoutCbh=
_scheduleWorkAt(when,
stdx::bind(&ReplicationCoordinatorImpl::_startElectSelfIfEligibleV1,
this,
StartElectionV1Reason::kElectionTimeout));
}
上面代码展示了这个选举定时器的逻辑,在每一个检测周期中,定时器都会尝试执行超时回调,
而回调函数指向的是_startElectSelfIfEligibleV1,这里面就实现了主动发起选举的功能,
如果心跳响应成功,通过cancelAndRescheduleElectionTimeout调用将直接取消当次的超时回调(即不会发起选举)
如果心跳响应迟迟不能成功,那么定时器将被触发,进而导致备节点发起选举并成为新的主节点!
同时,这个回调方法(产生选举)被触发必须要满足以下条件:
- 当前是备节点
- 当前节点具备选举权限
- 在检测周期内仍然没有与主节点心跳成功
这其中的检测周期略大于electionTimeout(10s),加入一个随机偏移量后大约是10-11.5s内,猜测这样的设计是为了错开多个备节点主动选举的时间,提升成功率。
最后,将整个自动选举切换的逻辑梳理后,如下图所示:
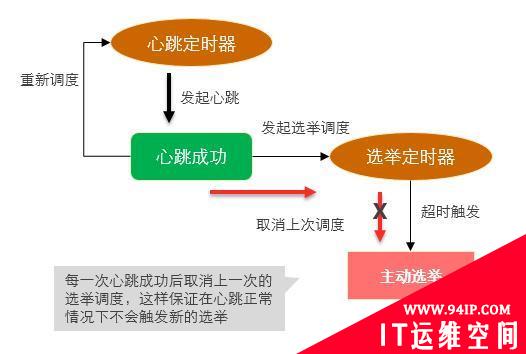
图-超时自动选举
业务影响评估
副本集发生主备切换的情况下,不会影响现有的读操作,只会影响写操作。 如果使用3.6及以上版本的驱动,可以通过开启retryWrite来降低影响。
但是如果主节点是属于强制掉电,那么整个 Failover 过程将会变长,很可能需要在Election定时器超时后才被副本集感知并恢复,这个时间窗口会在12s以内。
此外还需要考虑客户端或mongos对于副本集角色的监视和感知行为。但总之在问题恢复之前,对于原主节点的任何读写都会发生超时。
因此,对于极为重要的业务,建议最好在业务层面做一些防护策略,比如设计重试机制。
转载请注明:IT运维空间 » 运维技术 » MongoDB一次节点宕机引发的思考
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-
oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值















发表评论