

运维自动化来源于工作中的痛点,京东数据库团队面对的是商城成千上万的研发工程师,这种压力推动我们不断变革,然而变革不是一蹴而就,也经历过从手工到脚本化、自动化、平台化、智能化的艰难转变,所以说是需求在驱动运维体系的建设,而运维自动化的真谛在于解放运维人员,促进人率提升,减少人为故障,要学会培养自己“懒”这个好习惯。
京东的自动化运维体系建设始于2012年,下面从两个方面进行介绍:
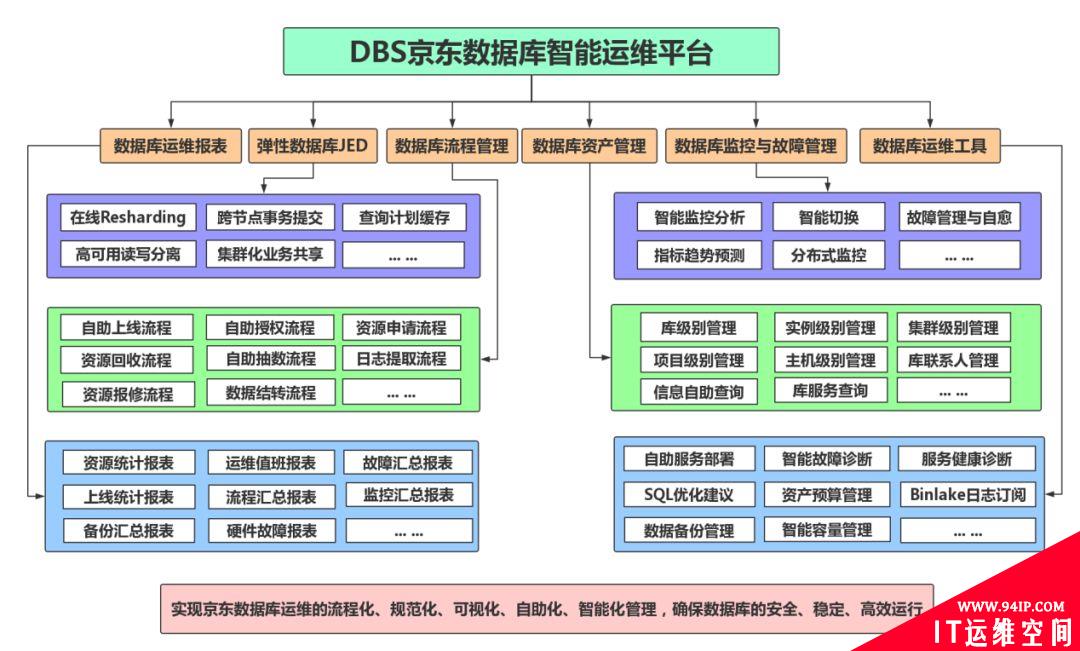
一、京东数据库智能运维平台
京东业务每年都在以爆发的形式在增长,数据库服务器的数量众多,产品线也多达上千条,要支持如此庞大的业务体系,需要一套完善的运维自动化管理平台。目前京东MySQL数据库管理平台简称DBS,主要涵盖以下内容:完善的资产管理系统、数据库流程管理系统、数据库监控系统、数据库故障管理系统、数据库报表系统、弹性数据库系统以及数据库辅助运维工具,涉及DBA运维的方方面面,实现了DBA对MySQL的自动化、自助化、可视化、智能化、服务化管理,避免DBA因手工操作失误带来的生产事故,保障京东数据库的安全、稳定、高效运行。
这里着重介绍以下部分核心功能组件:
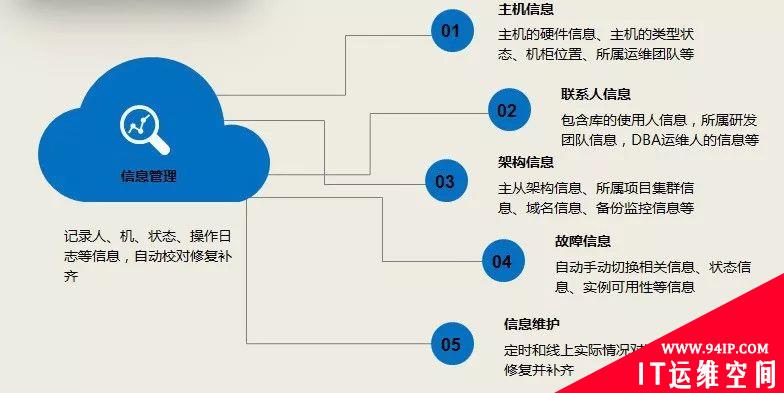
1、元数据管理
作为自动化运维的基石,它的准确性直接关系到整个数据库管理平台的可靠性。京东数据库管理平台从数据库业务方、DBA的运维习惯等方面出发,涵盖机房、主机、业务、集群、实例、库、表等多个维度:
- 机房和主机维度:主要记录硬件方面的信息。
- 业务维度:主要记录业务的名称、等级及业务部门相关信息。
- 集群维度:主要记录MySQL集群架构信息。
- 实例维度:主要记录MySQL的相关参数,为后续自动化运维提供保障。
- 库维度:主要记录数据库名称及业务人员联系信息。
2、自动化部署
面对繁杂的数据库新增,扩容等运维工作,利用自动安装部署平台可以彻底解放DBA。目前京东的自动化部署系统包含申请服务器、部署数据库实例、同步数据、一致性校验、拆分及切换等操作,整个过程流程化,包含各级业务及DBA的操作审批,最终达到全面的MySQL服务的自动化和流程化部署,如下图:
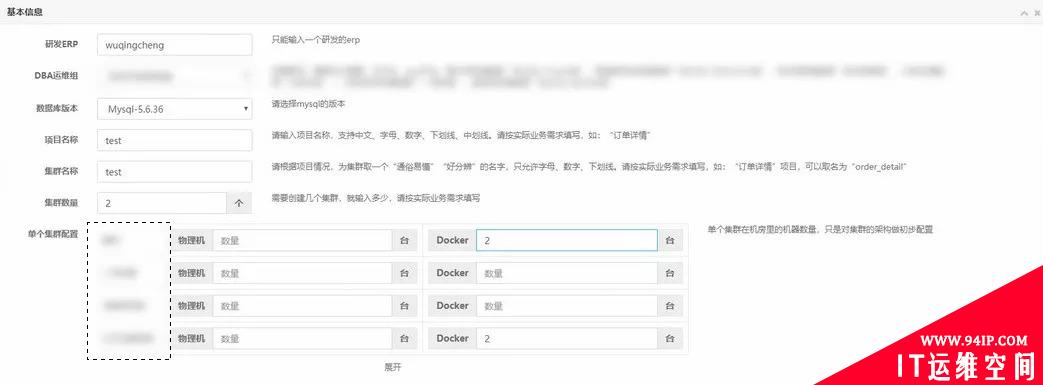
主要功能点包含以下内容:
- 安装部署MySQL实例,架构搭建,域名申请。分配规则要求同一集群主从实例不能在同一机柜,硬件性能好的主机优先为主库。
- 监控部署,备份部署,资产注册。
- MySQL服务采用镜像的形式创建,镜像依赖于K8S的镜像仓库。
- 应用账号是应用方通过自动化上线系统申请创建的。
- 主从数据一致性校验,通常会选择夜间业务低峰期定时执行。
3、智能分析与诊断
京东的智能分析与诊断涵盖4部分重要的内容,数据库监控指标采集、诊断分析、故障自愈、趋势分析:
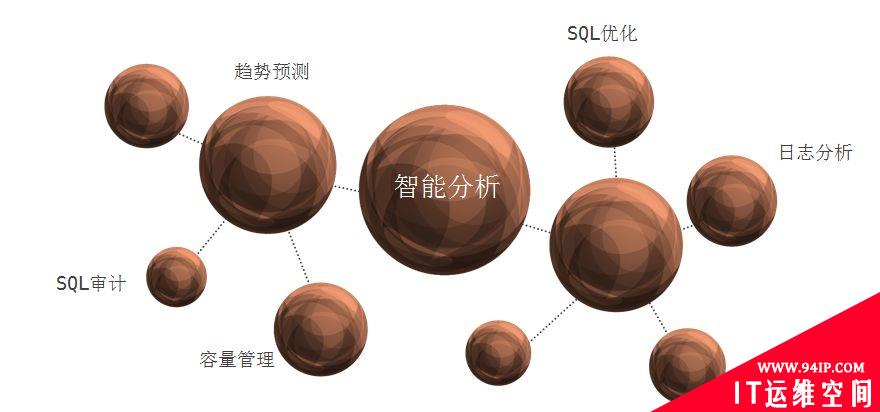
(1)监控系统
监控系统为数据库管理提供了精准的数据依据,能够让运维人员对生产服务系统运行情况了如指掌,核心的监控指标包含:OS负载、MySQL核心指标、数据库日志等。通过分析获得的监控信息,判断被监控数据库的运行状态,对可能出现的问题进行预测,并给出优化方案,保证整个系统稳定、高效。
京东的分布式监控系统采用被动模式,server端和proxy端均做高可用,防止单点故障。以下是整体架构和流程图:
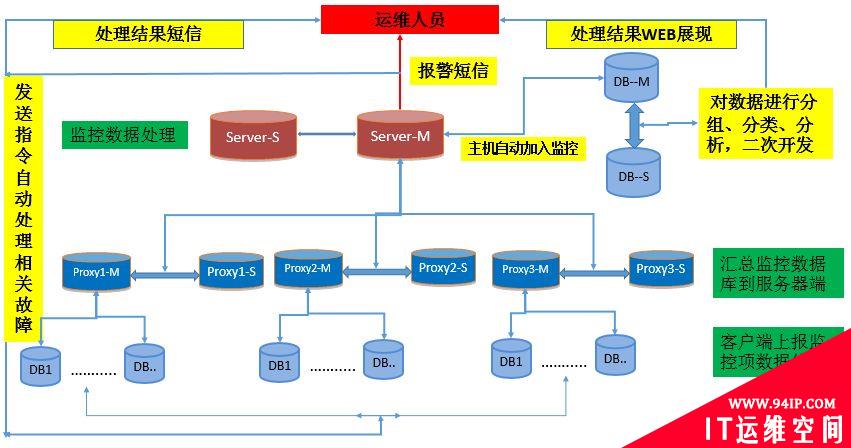
(2)监控性能分析

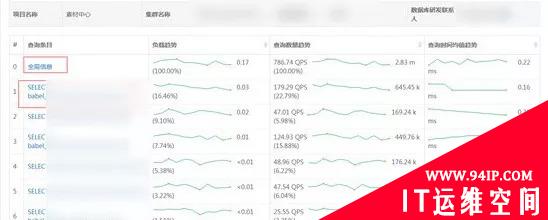
数据库性能智能分析,主要是对数据库监控数据的二次分析,排除安全隐患。在实际的生产中,有些隐患没有达到设置的报警阈值,处于一个报警的临界点,其实这种情况是最危险的,随时可能爆发,为解决这些隐患,我们通过对监控数据的环比、同比、TOP指标等方面进行分组汇总分析,提前发现隐患。
慢SQL分析:
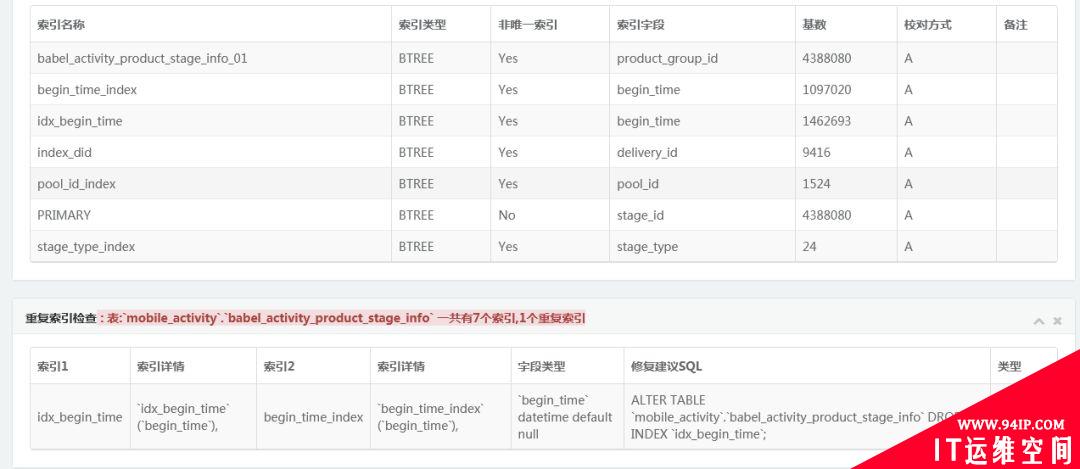
索引分析:
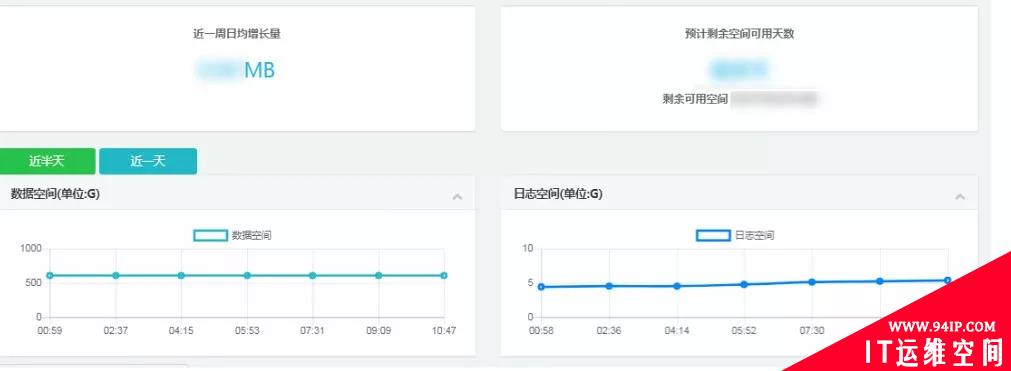
空间分析及预测:
锁分析:
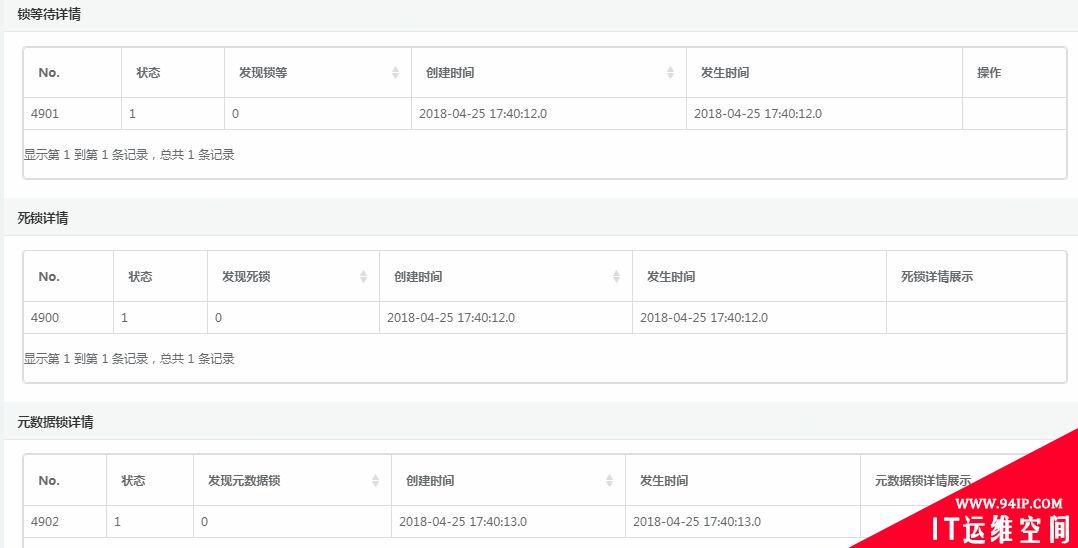
(3)故障自愈

故障出现的形态千奇百怪,而最核心的内容依赖于监控的辅助分析,如何提供最为精准的信息,所做内容如下:
- 告警过滤:将告警中不重要的告警以及重复告警过滤掉
- 生成派生告警:根据关联关系生成各类派生告警
- 告警关联:同一个时间窗内不同类型派生告警是否存在关联
- 权重计算:根据预先设置的各类告警的权重,计算成为根源告警的可能性
- 生成根源告警:将权重最大的派生告警标记为根源告警
- 根源告警合并:若多类告警计算出的根源告警相同,则将其合并
4、智能切换系统
京东数据库服务器的量级较大,会导致出故障的概率相对提高,同时对系统稳定性的要求也较为苛刻。因此为确保实现数据库高可用,保证7*24小时的持续服务,我们团队自主研发了数据库自动切换平台,实现了自动和半自动两种切换方式,实现了按单集群级别、多集群级别、机房级别等多维度的场景切换。切换过程包含监控的修改、资产信息的修改、备份策略的修改、主从角色的修改等,一键化完成,避免人为因素带来的二次故障。
(1)分布式检测
作为切换系统的核心组件,分布式检测功能主要解决系统容灾方面的问题。按照京东数据库服务器多数据中心部署的特征,独立的数据中心各部署了一个检测节点,并通过特殊标识的接口域名区分。当发生切换操作时,切换系统会根据传入的故障主机IP等信息,随机选取两个机房接口执行调用,探活操作如果发现有一个节点主机存活,那么认为主机存活;如果发现两个节点都探测为宕机,那么认为主机宕机。
(2)Master故障切换
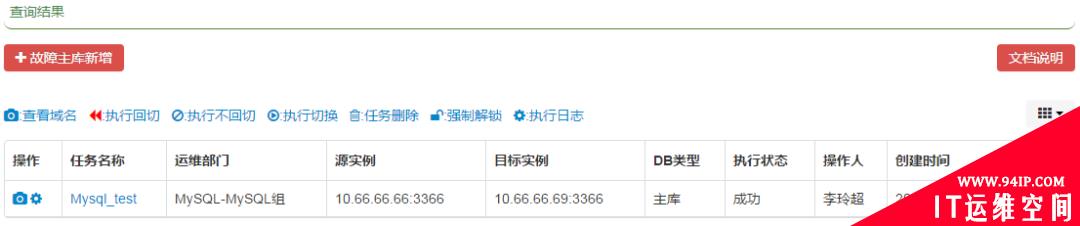
主库实例故障,切换系统会首先通过分布式检测系统检查实例存活状态,确认宕机后将根据基础信息中的实例切换标识,选择使用自动切换或手动切换,两种切换方式原理相同:先在切换系统上创建切换任务,手动切换需要DBA执行切换按钮,切换操作会通过insert方式插入数据以验证实例运行状态,避免实例夯住和硬盘只读的情况。如果没有存活的从库,则放弃本次操作并以邮件和短信的方式通知DBA。新主库是按照先本地(先连接数少,后QPS负载低),后异地的原则选择,执行切换成功后将变更相应元数据信息,示例如下:
某一主四从的集群,主库 10.66.66.66:3366故障,需要切换,如下:

- 监控系统检测到主库宕机,则自动创建切换任务,进行自动切换或者手动切换,以手动切换为例:

- 选目标实例,假如例子中的4个从都是存活的,那么根据先本地后异地原则,选出10.66.66.68:3366,10.66.66.69:3366,然后再去查连接数,在连接数都相同的情况下,则去比较QPS,选出QPS负载低的10.66.66.69:3366作为目标实例:

- 切换完成结果:
(3)Slave故障切换
从库实例故障,将故障实例下的域名变更到该集群下的非故障实例上,选择目标实例方式与主库实例选择规则一致。切换成功或失败都会发邮件及短信告知相应的DBA。故障实例恢复后,DBA判断是否需要回切。示例如下:
有一主四从的集群,从库 10.88.88.89:3366故障,需要切换,如下:
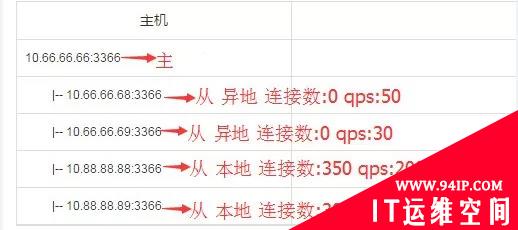
监控系统会自动创建任务,并根据先本地后异地原则,然后再查连接数、QPS,确定目标实例为10.88.88.88:3366,进行自动切换,DBA可在切换任务列表查看详情。

切换成功的任务会显示回切按钮,DBA可以执行回切,并查看回切的具体信息。

(4)主从计划性切换
主从计划性切换实现了按单集群,多集群的批量切换。执行批量切换时可以查看子任务切换的具体步骤,切换后会有前后架构的对比,具体示例如下:
集群1
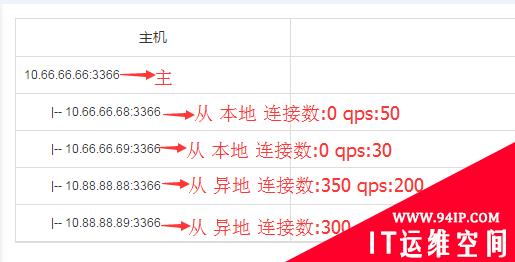
批量创建任务,选择原则根据先本地后异地,先连接数后QPS,10.66.66.66:3366选择目标主库为:10.88.88.89:3366。
批量执行切换:

切换子任务详细信息,可查看到每个子任务的切换结果,执行步骤及前后架构:

京东MySQL数据库切换系统各功能模块都已组件化、服务简化了DBA的操作流程,缩短了数据库切换的时间。
5、数据库自动化备份恢复
(1)架构设计
京东数据库备份系统在设计之初,就是为了将DBA从繁杂的备份管理工作中解脱出来,实现自动处理,减少人为干预,并提高备份文件的可用性。关于备份文件可用性问题,以轮询恢复的策略确保每个集群在一个周期内都被恢复到。系统架构设计如下图所示:

架构具备以下几个特点:
调度触发多样化
调度中心支持三种类型的触发方式interval、crontab和date:
- interval是周期调度,可以指定固定间隔时长的任务调度,支持时间单位有weeks、days、hours、minutes、seconds,并支持设定调度开始时间和结束时间以及时区设置。
- crontab是定时调度,与Linux的crontab基本相同,支持year、month、day、week、day_of_week、hour、minute、second,并且支持设置调度开始时间和结束时间以及时区设置。
- date是一次性定时调度,支持时区设置。
并发控制
由于调度任务设置具有不均衡性,可能某一时刻需要调度的任务较多,容易引起调度系统出现问题,因此执行任务通过控制并发数来使任务调度执行运行更加平稳。
触发和执行分层
任务触发本身是轻量级集的,而任务执行一般都比较重,因此对触发和执行进行了分层设计,来防止因为执行时间过长导致后续触发出现问题。
维护期间任务不丢失
Linux的crontab在停机维护期间要运行的任务开机后并不会再次执行,而基于APScheduler的调度中心则会在启动后运行指定间隔内尚未执行的任务,减少因维护而错失任务的执行。
备份策略增删改查
之前公司的备份系统是需要指定特定的IP,经常因为服务器维护而导致备份失败,故在设计之初就将备份策略与高可用结合在一起,备份策略指定域名而不是IP。从库因为故障切换时DBS会将此从库上的域名切换到集群内的其他从库,相应的备份也跟随到了此从库,保证了备份服务器是可用的。
失败自动重试
备份很可能因为偶然因素而失败,因此加入了备份重试的功能,会对6小时以内的备份失败任务进行备份重试,最多重试3次,来获得更高的备份成功率。
自动恢复检测
备份在每一步都要严格地验证,但是也无法绝对保证备份文件可用,因此引入了自动恢复检测机制,来帮助DBA对备份文件进行检测,及时发现因为各种未考虑到的情况导致备份文件不可用的情况,并且恢复检测也是审计的一个硬性要求,自动恢复检测也将DBA从繁重的恢复检测工作中彻底解脱了出来。
(2)调度设计

整个自动化备份恢复系统主要由调度系统、备份系统、恢复系统、恢复检测系统、自动修复系统组成。其中调度系统是整个系统核心,通过调度系统来协调其他系统运行。调度系统可以部署Standby来实现高可用,执行器以集群部署来实现高可用和横向扩容。
备份系统每次备份时都会进行实例健康状态检查、备份运行状态检查等,防止对无效的数据库实例进行备份;恢复系统主要是在需要进行数据恢复、弹性扩容等等需要从备份文件恢复成运行的数据库实例时使用,能够让DBA通过简单地操作即可完成数据的恢复;恢复检测在调度系统的指挥下自动对备份文件可用性进行检测,来帮助DBA及时发现不可用的备份文件;备份失败有些是能够通过失败自动重试来解决,但有一部分是重试所不能解决的,需要进行相应修复,因此开发了自动修复系统来自动修复因为环境等问题引起的备份失败。
调度系统是最核心的一个系统,是整个备份恢复系统的大脑,当时考察了几种实现方式,例如Linux的crontab、Azkaban和python的开源框架Apscheduler,最终认为Apscheduler更加灵活小巧,调度方式也更加多样化,使用Python开发后期维护成本更低,因此采用Apscheduler开发了调度中心。
(3)系统前端
主要分为备份策略管理、备份详情、备份黑名单管理、恢复详情四个模块:
备份策略管理:

备份策略管理的页面包含了备份状态分布情况、存储使用情况以及每个集群的当前备份策略状态,如果已经添加了备份策略则可以在这里进行(时间、服务器、备份方式)修改、暂停(继续)、删除操作,如果没有添加备份策略,则可以进行添加。
备份详情:

备份详情里面展示了最近备份总数、成功数、成功率、当天备份任务运行状态、备份任务24小时分布曲线图以及备份详细记录。备份详细的记录可以根据集群名、项目名等信息进行查询,方便DBA更好地掌握备份运行状况。
恢复检测详情:

恢复检测页面包含最近每天恢复检测数、恢复检测成功数、成功率柱状图、当天恢复检测任务运行状态饼图和近期恢复检测完成率,有助于DBA对恢复概况有更清晰的了解。
二、数据库变革
1、过去
在ContainerDB之前,京东的数据库服务实现了容器化,虽然数据库服务已经完全通过Docker容器实现了数据库服务的快速交付和自动故障切换等基本功能,在一定程度上提高了数据库服务的稳定性和效率,但是数据库服务的运维和使用方式与传统方式基本无异,比较典型的问题如下:
(1)资源分配粒度过大
数据库服务器资源标准固定,粒度过大,为数据库服务可提供的资源标准过少。
(2)资源浪费严重
资源分配的标准有DBA根据经验决定,存在很大的主观性,不能根据业务的实际情况进行准确评估,而DBA在分配资源的时候一般都会考虑在3年以内不需要对服务进行迁移或者扩容,而一次分配比较多的资源,存在严重资源浪费。而且由于数据库资源标准固定,标准过大,导致宿主机中的碎片过大,经常出现一台宿主机只能创建一个容器,而剩下的资源满足不了任何资源标准,导致宿主机上资源使用率过低。
(3)资源静态无调度
数据库服务一旦提供,所占据的资源就会固定,不能根据数据库的负载进行在线动态的调度,而一旦数据库的硬盘使用率过高,需要DBA人工介入进行扩容处理,效率低下。
2、现在
基于以上的问题,单纯的数据库服务容器化已经无法解决,我们需要让数据库服务更聪明,让数据库的资源能够动起来,提供资源分期交付的功能,于是ContainerDB应运而生。ContainerDB基于负载的弹性调度为京东的数据库资源赋予了智慧,令其资源真正地流动起来,并已成功服务于多次618和11.11大促。

ContainerDB针对每个业务应用都有逻辑库,逻辑库中定义了针对整个业务所有表的拆分键(Sharding Key)进行哈希取模运算时模的范围(KeySpace),在每个逻辑库中可以创建多张表,但是每个表中必须定义Sharding Key。通过该Sharding Key将表中的数据拆分成多个分片(Shard),每个分片都对应一个KeyRange,KeyRange表示对Sharding Key进行哈希取模运算之后得到的值(Sharding Index)的一个范围,每个Shard都由一整套MySQL主从架构提供数据库服务支撑。应用程序只跟Gate集群进行交互,由Gate根据元数据信息和SQL语句完成数据写入和查询的自动路由。ContainerDB中的监控中心会对所有的基础服务和资源使用状况进行实时监控,并通过在监控中心注册的Hook程序自动进行动态扩容、故障自愈、分片管理等,而这一系列操作对应用程序来说是完全无感知的。
(1)流式资源持续交付

数据库以前的服务存在资源浪费的一个主要原因就是资源初始分配粒度太大,一开始就为业务提前预支3年甚至5年的资源。而资源池中的资源是有限的,不可能让所有业务都提前预支资源,从而导致有些业务没有资源。ContainerDB采用流式的方式进行资源的持续交付。每个业务接入初始都只会分配标准的64G硬盘,随着业务的发展和数据量的持续增加,会持续增加硬盘容量直到到达硬盘限制的上限256G。

通过这种方式,我们极大地拉长了数据库资源的交付周期,进而可以在三年或者五年的所有资源预算到位之前就首先为所有服务提供数据库服务,提升了数据库的业务支撑能力。
(2)基于负载的弹性调度
数据库服务使用的资源分为两类:瞬时资源和递增资源。
瞬时资源是指会资源的使用率在短时间之内会出现严重波动,这种资源主要包括CPU和内存。
递增资源是指资源的使用率不会再短时间之内出现严重的波动,而是会缓慢增加,并且支持递增,不会出现减少的情况,这种资源主要包括硬盘。ContainerDB对于不同的资源采取了不同的调度策略。针对于瞬时资源,ContainerDB为每个数据库分配三种标准:
- 下限:2C/4G,上限:4C/8G
- 下限:4C/8G,上限:8C/16G
- 下限:8C/16G,上限:16C/32G
每个容器分配的初始资源为标准的下限值,当数据库服务出现CPU负载过高或者内存不足时,会尝试申请多于下限的CPU或者内存,但绝对不会超过上限,待负载恢复后释放多申请的资源,直至恢复至CPU和内存的下限为止。

针对递增资源:磁盘,在业务接入之初,统一分配64G的硬盘,每当当前磁盘使用率达到80%,且没有达到256G上限的时候,则进行垂直升级;若容器当前磁盘达到了256G上限则进行在线Resharding。
垂直升级:首先会进行资源check,看宿主机是否有足够的剩余硬盘资源进行垂直升级,若check通过,则会在宿主机施加全局资源锁,并对硬盘进行垂直扩容再增加64G。若check不通过,则在宿主机上提供一个硬盘大小为:磁盘容量+64G大小,CPU和内存与当前容器相同的新容器,并将数据库服务迁移到新的容器上。垂直升级是瞬间完成的不会影响数据库服务。
在线Resharding:申请两个新的Shard,新Shard中的数据库Container的硬盘、CPU和内存标准与当前Shard中的完全一致,根据当前Shard中的数据库主从关系,对新Shard中的所有数据库重建MySQL主从关系,然后启动Schema信息拷贝和过滤复制,最后更新路由规则并将读写流量切换到新的Shard上,将旧的Shard资源下线。
无论是垂直升级还是在线Resharding,都需要注意一个问题:在保证每个分片的Master在主机房的前提下,尽量不要将所有的资源都分配在一个宿主机/机架/机房,ContainerDB提供了强大的亲和/反亲和性资源分配能力。目前ContainerDB的亲和/反亲和性策略如下:

每个KeySpace都有一个主机房,属于同一个Shard中的数据库实例(目前一个shard中包含1主2从)的资源分配尽量应该满足:Master必须属于主机房,不能有任意两个实例属于同一机架,不能有任意三个实例在同一IDC,这种策略可以避免某一机柜掉电而导致主从同时出现故障,也可以避免IDC故障从而导致所有数据库实例均不可用。
由于是尽量满足,所以当资源池中的资源分布不均时,就有可能在资源分配的时候满足不了上述的反亲和性策略。因此ContainerDB有一个常驻后台进程,不停的轮询集群中的所有Shard,判断Shard中的实例分布是否满足反亲和性规则,若不满足,就会尝试进行实例重新分布。重新分布时为了不影响线上业务,会优先进行从库重分布。
基于弹性调度的能力ContainerDB实现了如下三个功能:
- 在线扩容:当某个Shard的数据库负载达到阈值后,会自动触发Shard的在线垂直升级、迁移或者Resharding。
- 在线自愈:当Shard中的某个MySQL实例出现故障,ContainerDB首先判断出现故障的实例是否为master,若是master,则选择GTID最大的slave作为新的主,并进行复制关系重建和Slave补齐;若不是master,则直接进行slave补齐。
- 在线接入:ContainerDB允许用户以完全自助化的方式启动数据在线迁移与接入任务,该任务会将传统MySQL数据库中的数据在线迁移到ContainerDB中,待数据迁移完毕后,自动进行域名切换,完成业务系统数据源的在线无感知迁移。
ContainerDB通过在线服务能力扩容、在线自愈和在线接入三大功能,实现了京东数据库服务的Always Online保证。
(3)不止于调度
弹性和流式的资源交付与调度是ContainerDB的基石,但是除了这两个核心功能之外,ContainerDB还在用户易用性、兼容性和数据安全性等方面做了很多工作,包括:
数据保护
在传统的直连数据库的方案下,当Master出现网络不可达时,一般都会选择新的Slave变为Master,然后将原来Master上的域名漂移到新的Master上。但是这种方案在网络抖动的情况下很容易由于AppServer上的DNS缓存,而导致双Master,并且出现脏写的情况。从整体架构图可以看出,ContainerDB与用户之间通过Gate连接。Gate是一个集群化服务,多个Gate服务都映射到一个域名下,Gate通过IP地址直接访问各个MySQL服务,而且Gate对各个MySQL角色的识别完全依赖于元数据服务:Topology。当ContainerDB中某个MySQL的Master产生网络不可达时,会选出新的Master,并更新路由元数据信息,最后才做Master切换,这样就避免了由于网络抖动和DNS缓存而在成双主和数据脏写,从而对数据进行了严格的保护。
流式查询处理

ContainerDB通过在Gate层实现基于优先级的归并排序提供了快速流式查询的功能,在进行大批量数据查询时,能瞬时返回部分查询结果数据,极大提高客户体验。
无感知数据迁移
ContainerDB通过在交叉在Window函数中分别执行部分存量数据拷贝和增量数据追加的算法,开发了在线数据迁移和接入工具JTransfer,通过JTransfer可以将传统MySQL数据库中的动态数据迁移到ContainerDB中,当ContainerDB中的数据与源MySQL中的数据的lag小于5秒时,首先会将源MySQL停写,待lag变为0时将源MySQL的域名漂移到Gate集群,整个迁移过程用户AppServer无感知。
兼容MySQL协议
ContainerDB完全兼容MySQL协议,支持标准MySQL客户端和官方驱动程序接入,并且支持大部分ANSI SQL语法。
路由规则透明
ContainerDB与用户之间通过Gate集群进行连接,Gate根据用户发送的查询语句形成的语法树和查询执行计划得到查询中涉及到的所有表,并根据Topology中的元数据信息获得各个表的分片信息,最后结合语句中的Join中的关联条件和Where字句中的谓词信息,将查询或者写入路由到正确的分片。整个过程都是Gate自动完成的,对用户完全透明。
自助化服务
ContainerDB将对数据库服务的实例化、DDL/DML执行、分片升级和扩容等功能抽象成为独立的接口,并借助于流程引擎提供了流程化的完全自助的用户接入服务,用户申请数据库服务成功后,ContainerDB会将数据库访问口令自动推送到用户邮箱。
3、展望
过去已去,未来已来。
我们后续会更多的从用户的角度去思考数据库能够产生的价值。我们相信京东以后的数据库服务会:
- More Smart:我们会基于各个数据库实例中CPU/内存/硬盘等各种不同资源的监控数据进行深度学习和聚类分析,分析出各个不同数据库实例的倾向资源,并智能化调高每个数据库实例倾向资源的限制并调低非倾向资源的限制。
- More Quick:我们会实时分析宿主机和容器的对应关系、各个容器的限制参数以及各个容器的历史资源增长速率,预先对容器所在宿主机碎片进行整理,从而尽量保证各个容器以垂直升级的方式实现扩容,从而极大地加快扩容速度。
- More Cheap:我们会提供完全自主研发的存储引擎,计划实现查询引擎与存储引擎的集成,并提供多模型数据库引擎,从而实现多种数据模型的统一,极大节省数据库服务所需资源以及研发成本。
- More Friendly:无论是ContainerDB还是我们自主研发的多模型数据库,我们都会完全兼容MySQL协议及语法,从而使得现有应用的迁移成本趋近于0。
- More Open:ContainerDB会在经过京东内部的各种场景的磨练之后会拥抱开源,并希望与业界各位同仁一起将ContainerDB不断完善。同时我们后续的多模型数据库最终也会贡献给开源社区,并期待其服务于业界。
转载请注明:IT运维空间 » 运维技术 » 京东数据库智能运维平台的建设之路
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论