

作者简介
本文作者佐思、烧鱼、Shirley博,来自于携程Cloud Container团队,主要从事Service Mesh在携程的落地,负责控制面的可用性及优化建设,以及推进各类基础设施服务的云原生化。该团队负责K8s容器平台的研发和优化工作,专注于推动基础设施云原生架构升级,以及创新产品的研发和落地。
一、背景
为了支撑业务的高速发展,从17年开始,携程内部逐步推进应用容器化改造与业务上云工作,同期携程技术架构经历了从集中式单体应用到分布式微服务化的演进过程。 随着Kubernetes的不断发展和推广,服务网格(Service Mesh)在近几年也变得很流行。而 Servive Mesh 之所以越来越受欢迎,在提供更丰富的服务治理、安全性、可观测性等核心能力外,其从架构设计层面解决了以上几个痛点,服务治理能力以 Sidecar 的模式下沉到数据面,解决了 SDK 升级及多语言的问题,对于像负载均衡、熔断、限流等策略配置,由控制面统一管理和配置,并下发到数据面生效。在整体架构上云技术方案选型上,权衡各类方案的功能完备性、架构扩展性、改造维护成本及社区发展等,最终选择基于Istio构建Service Mesh平台治理方案。
1.1 携程Service Mesh发展
从2020年中,我们依托K8S底座能力,进行Service Mesh技术预研,深度定制Istio,并与携程框架部门合作进行了小规模的落地试点。2021年底,接入非核心应用600+,为Service Mesh在携程的最终落地奠定基础。到目前为止,生产环境已有2000个应用(业务POD数近1W)接入,预期下半年推进核心应用的接入。

1.2 携程Service Mesh数据表现
在前期应用接入过程中,针对Istio稳定性(主要在性能)方面,梳理了以下几个问题:
控制面并发性能:pilot对象处理的并发性能是否满足平台需求?
控制面配置下发时效性:配置下发的延迟及准确性是否能够满足业务需求?
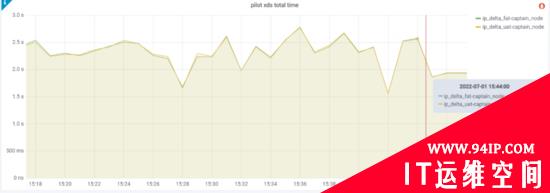
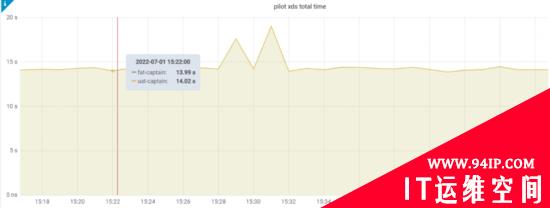
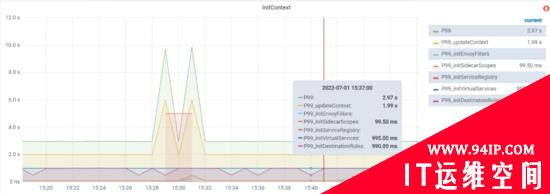
本文主要分享在当前的体量下,回答上述问题,使控制面平稳支撑大规模 Sidecar 的落地,通过下述优化之后,测试域(Istio CR量级在1W+)如下图所示:
-
从实际生产来看,ServiceEntry的处理效率提升了15倍左右
从测试域来看,整体initContext时延从原先P99 30s左右到目前P99 5-10秒左右
从测试域来看,整体优化水平从原先P99 30s+到目前的P99 15s左右(该处为全量推送水平,其中15s的结果是平衡资源使用与推送效率调参的目标值,这里PILOT_DEBOUNCE_AFTER设置为10s)
开启增量推送后,实例推送在测试域的推送效果从10-30s缩减至2.5s左右
携程目前Istio落地版本为1.10
二、Service Mesh优化的思路与挑战
2.1 现状
针对Service Mesh在携程落地的服务目标,可以用一句话进行总结:能够通过横向扩展,支撑万级业务服务。为了完成上述目标,团队面临以下挑战:
-
当前 Istio的对象处理性能等方面无法满足平台需求
配置下发的延迟及准确性无法满足业务需求
经过前中期,针对 Istio架构进行深入研究以及上线前期测试的性能预研,核心问题聚焦在以下几点:
-
istio对象处理性能较低:在处理ServiceEntry时的并发性缺失及WorkloadEntry Selector模式的计算高耗时等
istio配置推送性能较低:配置推送时对象的全量处理拉长下发时延,并会随着Istio对象增长而近线性增长
2.2 优化实践
接下来主要分享携程所经历过的性能问题,和对应的优化的方向:
对象处理性能
当前istio使用内部queue处理各类Object事件,其为线性处理流程,效率比较低下,为此社区提供namespace filter方式进行处理,以减缓性能问题,但针对Istio相关对象,未实现基于namespace的隔离,因此效率提升不太符合预期。
推送性能
xDS 是 istio 控制面和数据面 envoy 之间的通信协议,其中x 表示多种协议的集合,可以简单的把 xDS 理解为,网格内的服务发现数据和治理规则的集合。xDS 数据量的大小和网格规模是正相关的。
当前 istio 下发 xDS 使用的是全量下发策略,也就是网格里的所有 sidecar,内存里都会有整个网格内所有的服务发现数据。在大量服务实例的情况下,全量下发会影响 Pilot 和 Sidecar 的性能和稳定性,虽然Istio 在不断的演进过程中引入了一些 scoping 的机制,就是 Sidecar 这个 CRD,这个配置可以显式的定义服务之间的依赖关系,但该scoping方案还是无法达到业务侧的推送延迟预期。
首先,简要介绍一下Istio推送的过程:
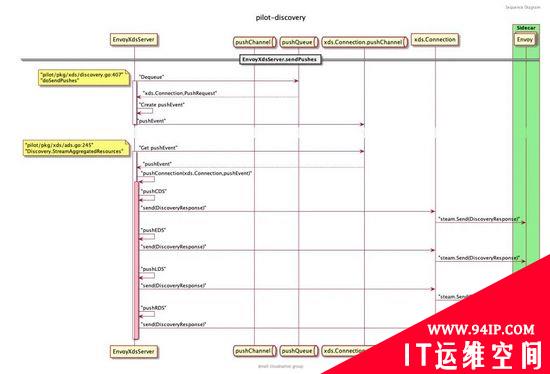 注:这里使用海东同学的推送源码分析图
根据上图结合源码可知:
注:这里使用海东同学的推送源码分析图
根据上图结合源码可知:
-
StreamAggregatedResources会和当前的 Proxy 创建一个连接,并创建一个接受请求的reqChannel。同时开启一个新的协程receiveThread处理客户端主动发起的请求,期间调用s.globalPushContext().InitContext(s.Env, nil, nil)进行数据初始化,其中InitContext需要处理Istio 所有CR的全量数据(如VirtualServices、DestinationRules、EnvoyFilters和SidecarScopes等),该操作耗时较长,因测试环境上述对象量级在2w左右,导致执行耗时P99 在28s左右。
从con.pushConnection中获取到pushEv事件后,调用s.pushConnection()进行处理,判断是否为全量推送:
if pushRequest.Full {
// Update Proxy with current information.
s.updateProxy(con.proxy, pushRequest.Push)
}
其中 updateProxy 更新proxy当前信息,主要逻辑如下所示:
func (s *DiscoveryServer) updateProxy(proxy *model.Proxy, push *model.PushContext) {
s.setProxyState(proxy, push)
if util.IsLocalityEmpty(proxy.Locality) {
...
if len(proxy.ServiceInstances) > 0 {
proxy.Locality = util.ConvertLocality(proxy.ServiceInstances[0].Endpoint.Locality.Label)
}
}
}
func (s *DiscoveryServer) setProxyState(proxy *model.Proxy, push *model.PushContext) {
proxy.SetWorkloadLabels(s.Env)
proxy.SetServiceInstances(push.ServiceDiscovery)
...
proxy.SetSidecarScope(push)
proxy.SetGatewaysForProxy(push)
}
在 setProxyState 方法中的环节获取SidecarScope等相关信息。针对上述介绍可以明确下面几个优化方向: 虽然Istio针对K8S对象实现了基于namespace级别的隔离,但未对Istio CR对象实现namespace级别隔离 在 InitContext 方法中, Push() 这么慢,主要是在 req.Full 做全量推送的时候,需要初始化 PushContext ,初始化 PushContext 的过程中需要调用 initServiceRegistry 、 initEnvoyFilters 和 initSidecarScopes 等,耗时巨大 2.2.1 Pilot性能优化 资源基于Namespace隔离 虽然Istio针对K8S对象实现了基于namespace级别的隔离,但未对Istio CR对象实现namespace级别隔离,基于此,内部团队针对Istio 1.10.3版本针对Istio CR对象实现namespace隔离,使其影响范围控制在指定namespace 下,其他用户操作Istio CR而彼此互不干扰,且能够极大缩减Istio Event事件的处理,加速Pilot启动速度,提升事件处理效率,促进配置下发效率,在CR Client结构体中,新增 namespaceFilter 等相关字段,定义如下:
// Client is a client for Istio CRDs, implementing config store cache
// This is used for CRUD operators on Istio configuration, as well as handling of events on config changes
type Client struct {
...
namespaceInformer v1.NamespaceInformer
namespaceFilter filter.DiscoveryNamespacesFilter
...
}
截至目前为止,携程Mesh平台主要分为SLB、SOA两大namespace,基于namespace隔离之后,效率提升预估在50%左右。 ServiceEntryStore 改造 ServiceEntryStore 的数据处理性能问题,主要有以下几点:
-
它里面有一个步骤,会全量更新实例的索引,这意味着 service 有一个发生变化了,它会更新全部 service 的索引,这是一个量级写放大
WorkloadEntry与ServiceEntry的关联查询的耗时,随着彼此的数量逐步放大
configController的Queue队列为线性处理,效率低下
因此,携程通过针对ServiceEntryStore进行Controller-Runtime改造,将ServiceEntry对象由线性处理改为并发处理,同时将WorkloadEntry结构体废弃,选择直接使用ServiceEntry,业务方Operator管理ServiceEntry对应Endpoint方式,优化处理性能,从实际生产效率来看,ServiceEntry的处理效率提升了4倍左右。 EnvoyFilter增量化改造 通过上述简介可知, Push() 这么慢,主要是在 req.Full 做全量推送的时候,需要初始化 PushContext ,初始化 PushContext 的过程,都是全量且嵌套循环处理,因此当多个对象量级巨大,则计算耗时成倍增长,针对EnvoyFilter的全量处理,不涉及其他对象,可以通过定义EnvoyFilterController结构体以Controller方式运行,从而实现全量改增量,结构体定义如下:
type Controller struct {
xdsUpdater model.XDSUpdater
client kube.Client
queue controllers.Queue
// processed ingresses
envoyFilter map[types.NamespacedName]*wrapEnvoyFilterWrapper
envoyFilterInformer cache.SharedInformer
envoyFilterLister v1alpha3.EnvoyFilterLister
mutex sync.Mutex
envoyFiltersByNamespace map[string][]*wrapEnvoyFilterWrapper
}
Sidecar延迟及按需计算 在 InitContext 方法中,除了EnvoyFilter耗时较多外,initSidecarScopes同样耗时巨大,通过代码可知, Sidecar 有两种,一种是带 WorkloadSelector 的,一种是不带的。不带 Selector 的话就是对这个命名空间所有服务生效。如果没有手动创建默认的 Sidecar ,Pilot 会通过 DefaultSidecarScopeForNamespace 为当前命名空间创建一个默认的 Sidecar ,会将网格中所有的服务都遍历一遍,写入 SidecarScope 中。 initSidecarScopes 循环计算如下:
sidecar数量x(egressConfigs数量x(selectVirtualServices耗时+selectServices耗时)+out.EgressListeners数量x(listener.services数量+listener.virtualServices数量...))
因SidecarScope涉及其他CR对象结果,因此无法简单的由全量改增量,但可以通过延迟计算和按需计算方式,进行效率提升,延迟计算主要通过将 initSidecarScopes 计算逻辑后移至push阶段,按需计算即没必要计算所有Sidecar,只需要根据链接的proxy进行计算即可,通过上述的优化,可以做以下针对性调整:
-
如果集群内服务较多,为每一个应用创建一个sidecar,防止所有服务信息推送给envoy,导致envoy OOM。
在上述优化之后,InitContext的处理耗时可以从P99 30s下降到P99 5s左右,此时,配置推送效率得到5倍左右的提升,那么 setProxyState 处的耗时,将会被放大,CPU的使用率将会成倍增长,可以通过下述配置进行优化。
2.2.2 Pilot配置优化 启用 XDS 增量推送 通过给 istiod 配置 PILOT_ENABLE_EDS_DEBOUNCE环境变量,我们启用 istiod 的增量推送而无需等待full push。 减少推送量 将 istiod 的 PILOT_FILTER_GATEWAY_CLUSTER_CONFIG 环境变量配置为 “true”,这样 Istio 将仅推送 Gateway 所需的服务信息,这个配置将极大的减少每次推送的量。开启这个特性之后,集群内的 istiod 每次向 Gateway 推送的服务信息降低90%。 关闭Headless 将 istiod 的 PILOT_ENABLE_HEADLESS_SERVICE_POD_LISTENERS环境变量配置为 “false”,因为headless svc对应的endpoints发生了变化,会触发full push的行为。 提高吞吐 默认情况下,单个 istiod 的推送并发数只有 100,在较大的集群内,可能会导致配置生效的延迟。istiod 环境变量 PILOT_PUSH_THROTTLE 可以配置这个并发数。建议根据集群规模进行配置。 避免频发推送 PILOT_DEBOUNCE_AFTER 与 PILOT_DEBOUNCE_MAX 是配置 istiod 去抖动的两个参数。 默认配置是 100ms 与 10s ,这也就意味着,当集群中有任何事件发生时,Istio 会等待 100ms,如果开启EDS,则增量推送不会等待。 若 100ms 内无任何事件进入,Istio 会立即触发推送。否则 Istio 将会等待另一个 100ms,重复这一操作,直到总共等待的时间达到 10s 时,会强制触发推送。实践中可以适当调整这两个值以匹配集群规模和实际应用。携程内部调高 PILOT_DEBOUNCE_AFTER 到 10s,以避免频繁推送对性能产生影响,也能够避免极端情况下推送不及时导致的 503 问题。
三、Service Mesh未来展望
控制面的重心在于解决规模化问题,后续控制面将会在下述领域深入探索:
-
控制⾯去除对k8s的资源的依赖,推送耗时下降到秒级别,满⾜更⼤规模的接⼊
使⽤NDS实现DNS解析功能,避免search域多次查询,提升Mesh的可⽤性
团队将与社区深度合作,针对控制面,密切关注增量推送等特性,后续将优先实现控制面稳定性增强,如下述功能:
-
连接限流:通过限流功能,降低大量Sidecar同时连接同一个 Pilot 实例的风险,减少服务风暴发生的机率。
熔断:基于生产场景的压测数据,测算出单实例 Pilot 可服务的 Sidecar 上限,超过上限值后,新连接会被Pilot 拒绝。
Service Mesh作为云原生领域下一代微服务技术,经过 2 年多摸索与演进,携程完成了多语言、多场景的业务落地, 实际论证了Service Mesh在流量管控、系统扩展性的优势,具有下沉服务治理能力到基础设施层,高度解耦中间件与业务系统的可行性。 后续,携程将在总结前期非核心应用Service Mesh化改造的基础上,逐步推进核心应用的落地,同步打磨完善平台能力,全面提升稳定性,为行业落地Service Mesh提供最佳实践和相关借鉴。
转载请注明:IT运维空间 » 运维技术 » 携程Service Mesh性能优化实践
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论