

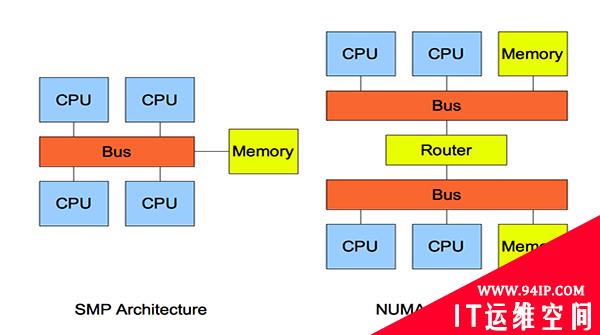
1. SMP(Symmetric Multi-Processor)
SMP (Symmetric Multi Processing),对称多处理系统内有许多紧耦合多处理器,在这样的系统中,所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。操作系统管理着一个队列,每个处理器依次处理队列中的进程。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。Access to RAM is serialized; this and cache coherency issues causes performance to lag slightly behind the number of additional processors in the system.
 所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA :Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA :Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
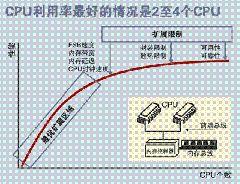 图1. SMP 服务器 CPU 利用率状态
8路服务器是服务器产业的分水岭。因为4路及以下服务器都采用SMP架构(Symmetric Multi-Processor,对称多处理结构),实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU。8是这种架构支持的处理器数量的极限,要支持8颗以上的处理器须采用另外的NUMA架构(Non-Uniform Memory Access,非一致性内存访问)。利用NUMA技术,可以较好地解决原来SMP系统的扩展问题,在一个物理服务器内可以支持上百个CPU。
图1. SMP 服务器 CPU 利用率状态
8路服务器是服务器产业的分水岭。因为4路及以下服务器都采用SMP架构(Symmetric Multi-Processor,对称多处理结构),实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU。8是这种架构支持的处理器数量的极限,要支持8颗以上的处理器须采用另外的NUMA架构(Non-Uniform Memory Access,非一致性内存访问)。利用NUMA技术,可以较好地解决原来SMP系统的扩展问题,在一个物理服务器内可以支持上百个CPU。
2. NUMA(Non-Uniform Memory Access)
由于 SMP 在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术, NUMA 就是这种努力下的结果之一。利用 NUMA 技术,可以把几十个 CPU( 甚至上百个 CPU) 组合在一个服务器内。其 CPU 模块结构如图 2 所示:
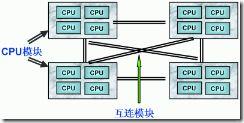 图2. NUMA 服务器 CPU 模块结构
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。如 HP 公司发布 Superdome 服务器时,曾公布了它与 HP 其它 UNIX 服务器的相对性能值,结果发现, 64 路 CPU 的 Superdome (NUMA 结构 ) 的相对性能值是 20 ,而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3 。从这个结果可以看到, 8 倍数量的 CPU 换来的只是 3 倍性能的提升。
2008年intel发布了Nehalem构架处理器,CPU内集成了内存控制器。当多CPU时任何一颗CPU都能访问全部内存。但CPU0访问本地内存(CPU0控制器直接控制的内存)消耗小,CPU0访问远地内存(CPU1内存控制器控制的内存)消耗大,NUMA功能的开启变成了必须了。
默认的NUMA功能是将计算和内存资源分配在一个NUMA内,有可能导致SWAP问题,即:NUMA0内存已经用完都开始用SWAP空间了,NUMA1还有很大的内存free。在数据库服务器上NUMA可能导致非常严重的性能问题,甚至有很多数据库死机的问题。就下图这个熊样。
图2. NUMA 服务器 CPU 模块结构
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。如 HP 公司发布 Superdome 服务器时,曾公布了它与 HP 其它 UNIX 服务器的相对性能值,结果发现, 64 路 CPU 的 Superdome (NUMA 结构 ) 的相对性能值是 20 ,而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3 。从这个结果可以看到, 8 倍数量的 CPU 换来的只是 3 倍性能的提升。
2008年intel发布了Nehalem构架处理器,CPU内集成了内存控制器。当多CPU时任何一颗CPU都能访问全部内存。但CPU0访问本地内存(CPU0控制器直接控制的内存)消耗小,CPU0访问远地内存(CPU1内存控制器控制的内存)消耗大,NUMA功能的开启变成了必须了。
默认的NUMA功能是将计算和内存资源分配在一个NUMA内,有可能导致SWAP问题,即:NUMA0内存已经用完都开始用SWAP空间了,NUMA1还有很大的内存free。在数据库服务器上NUMA可能导致非常严重的性能问题,甚至有很多数据库死机的问题。就下图这个熊样。
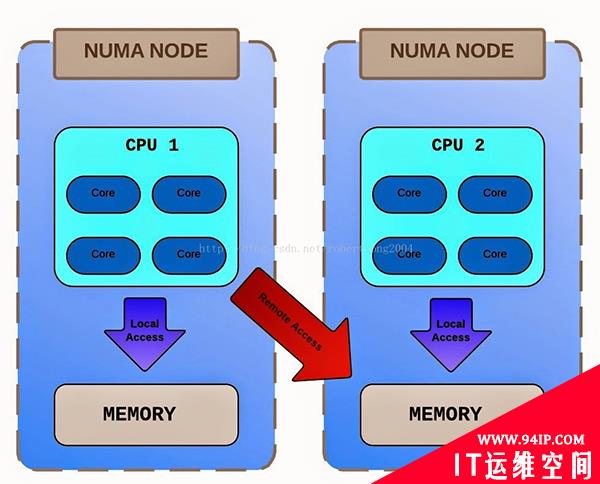 在虚拟化情况下,KVM虚机的CPU数量尽量不超过一个NUMA区域内的CPU数量,如果超过,则会出现一个KVM虚机使用了两个NUMA的情况,导致CPU等待内存时间过长,系统性能下降,此时需要手动调整KVM的配置才可以提高性能。
在虚拟化情况下,KVM虚机的CPU数量尽量不超过一个NUMA区域内的CPU数量,如果超过,则会出现一个KVM虚机使用了两个NUMA的情况,导致CPU等待内存时间过长,系统性能下降,此时需要手动调整KVM的配置才可以提高性能。
-
Ubuntu 12.02自身带有Automatic NUMA balancing,可以支持NUMA自平衡,具体情况未测试。SUSE12也支持Automatic NUMA balancing
JUNO版的Openstack中,KVM的CPU的拓扑可以通过image或者flavor进行元数据传递来定义,如果没有特别的定义此类元数据,则模拟的CPU将是多Socket单Core单NUMA节点的CPU,这样的CPU与物理CPU完全不同。
上面是KVM。Vmware ESX 5.0及之后的版本支持一种叫做vNUMA的特性,它将Host的NUMA特征暴露给了GuestOS,从而使得Guest OS可以根据NUMA特征进行更高性能的调度。
-
CPU的热添加功能不支持vNUMA功能。
vmotion等功能一旦将vmware虚机迁移,则可能导致vNUMA失效,带来严重的性能降低。所以在ESXi中保持物理服务器的一致性是有必要的。
中国第一台自主研发的,可支持32可处理器的高端服务器浪潮天梭K1,发布于2013年1月,系统可用性达到99.9994%,同时,我国也成为了时间上第三个掌握该技术的国家。
3. MPP(Massive Parallel Processing)
和 NUMA 不同, MPP 提供了另外一种进行系统扩展的方式,它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构,因而扩展能力最好,理论上其扩展无限制,目前的技术可实现 512 个节点互联,数千个 CPU 。目前业界对节点互联网络暂无标准,如 NCR 的 Bynet , IBM 的 SPSwitch ,它们都采用了不同的内部实现机制。但节点互联网仅供 MPP 服务器内部使用,对用户而言是透明的。
在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。但和 NUMA 不同的是,它不存在异地内存访问的问题。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配 (Data Redistribution) 。
但是 MPP 服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前一些基于 MPP 技术的服务器往往通过系统级软件 ( 如数据库 ) 来屏蔽这种复杂性。举例来说, NCR 的 Teradata 就是基于 MPP 技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载。
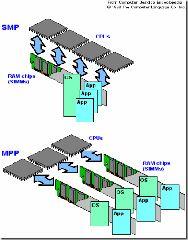
MPP (Massively Parallel Processing),大规模并行处理系统,这样的系统是由许多松耦合的处理单元组成的,要注意的是这里指的是处理单元而不是处理器。每个单元内的CPU都有自己私有的资源,如总线,内存,硬盘等。在每个单元内都有操作系统和管理数据库的实例复本。这种结构最大的特点在于不共享资源。
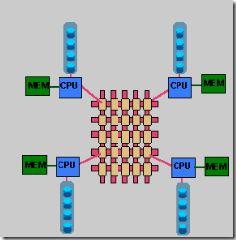
4. 三种体系架构之间的差异
4.1 SMP系统与MPP系统比较
既然有两种结构,那它们各有什么特点呢?采用什么结构比较合适呢?通常情况下,MPP系统因为要在不同处理单元之间传送信息(请注意上图),所以它的效率要比SMP要差一点,但是这也不是绝对的,因为MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。而MPP系统在决策支持和数据挖掘方面显示了优势,可以这样说,如果操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好,相反就不合适了。
通过上面两个图我们可以看到,对于SMP来说,制约它速度的一个关键因素就是那个共享的总线,因此对于DSS程序来说,只能选择MPP,而不能选择SMP,当大型程序的处理要求大于共享总线时,总线就没有能力进行处理了,这时SMP系统就不行了。当然了,两个结构互有优缺点,如果能够将两种结合起来取长补短,当然最好了。

4.2 NUMA 与 MPP 的区别
从架构来看, NUMA 与 MPP 具有许多相似之处:它们都由多个节点组成,每个节点都具有自己的 CPU 、内存、 I/O ,节点之间都可以通过节点互联机制进行信息交互。那么它们的区别在哪里?通过分析下面 NUMA 和 MPP 服务器的内部架构和工作原理不难发现其差异所在。
首先是节点互联机制不同, NUMA 的节点互联机制是在同一个物理服务器内部实现的,当某个 CPU 需要进行远地内存访问时,它必须等待,这也是 NUMA 服务器无法实现 CPU 增加时性能线性扩展的主要原因。而 MPP 的节点互联机制是在不同的 SMP 服务器外部通过 I/O 实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此 MPP 在增加节点时性能基本上可以实现线性扩展。
其次是内存访问机制不同。在 NUMA 服务器内部,任何一个 CPU 可以访问整个系统的内存,但远地访问的性能远远低于本地内存访问,因此在开发应用程序时应该尽量避免远地内存访问。在 MPP 服务器中,每个节点只访问本地内存,不存在远地内存访问的问题。
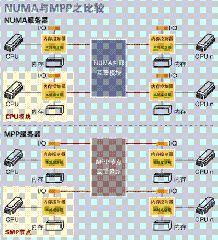 图3.MPP 服务器架构图
数据仓库的选择
哪种服务器更加适应数据仓库环境?这需要从数据仓库环境本身的负载特征入手。众所周知,典型的数据仓库环境具有大量复杂的数据处理和综合分析,要求系统具有很高的 I/O 处理能力,并且存储系统需要提供足够的 I/O 带宽与之匹配。而一个典型的 OLTP 系统则以联机事务处理为主,每个交易所涉及的数据不多,要求系统具有很高的事务处理能力,能够在单位时间里处理尽量多的交易。显然这两种应用环境的负载特征完全不同。
从 NUMA 架构来看,它可以在一个物理服务器内集成许多 CPU ,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同 CPU 模块之间的数据交互。显然, NUMA 架构更适用于 OLTP 事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使 CPU 的利用率大大降低。
相对而言, MPP 服务器架构的并行处理能力更优越,更适合于复杂的数据综合分析与处理环境。当然,它需要借助于支持 MPP 技术的关系数据库系统来屏蔽节点之间负载平衡与调度的复杂性。另外,这种并行处理能力也与节点互联网络有很大的关系。显然,适应于数据仓库环境的 MPP 服务器,其节点互联网络的 I/O 性能应该非常突出,才能充分发挥整个系统的性能。
图3.MPP 服务器架构图
数据仓库的选择
哪种服务器更加适应数据仓库环境?这需要从数据仓库环境本身的负载特征入手。众所周知,典型的数据仓库环境具有大量复杂的数据处理和综合分析,要求系统具有很高的 I/O 处理能力,并且存储系统需要提供足够的 I/O 带宽与之匹配。而一个典型的 OLTP 系统则以联机事务处理为主,每个交易所涉及的数据不多,要求系统具有很高的事务处理能力,能够在单位时间里处理尽量多的交易。显然这两种应用环境的负载特征完全不同。
从 NUMA 架构来看,它可以在一个物理服务器内集成许多 CPU ,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同 CPU 模块之间的数据交互。显然, NUMA 架构更适用于 OLTP 事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使 CPU 的利用率大大降低。
相对而言, MPP 服务器架构的并行处理能力更优越,更适合于复杂的数据综合分析与处理环境。当然,它需要借助于支持 MPP 技术的关系数据库系统来屏蔽节点之间负载平衡与调度的复杂性。另外,这种并行处理能力也与节点互联网络有很大的关系。显然,适应于数据仓库环境的 MPP 服务器,其节点互联网络的 I/O 性能应该非常突出,才能充分发挥整个系统的性能。
4.3 NUMA、MPP、SMP 之间性能的区别
NUMA的节点互联机制是在同一个物理服务器内部实现的,当某个CPU需要进行远地内存访问时,它必须等待,这也是NUMA服务器无法实现CPU增加时性能线性扩展。 MPP的节点互联机制是在不同的SMP服务器外部通过I/O实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此MPP在增加节点时性能基本上可以实现线性扩展。 SMP所有的CPU资源是共享的,因此完全实现线性扩展。
4.4 NUMA、MPP、SMP之间扩展的区别
NUMA理论上可以无限扩展,目前技术比较成熟的能够支持上百个CPU进行扩展。如HP的SUPERDOME。 MPP理论上也可以实现无限扩展,目前技术比较成熟的能够支持512个节点,数千个CPU进行扩展。 SMP扩展能力很差,目前2个到4个CPU的利用率最好,但是IBM的BOOK技术,能够将CPU扩展到8个。 MPP是由多个SMP构成,多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务。
4.5 MPP 和 SMP、NUMA 应用之间的区别
-
MPP 的优势:
MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。由于MPP系统因为要在不同处理单元之间传送信息,在通讯时间少的时候,那MPP系统可以充分发挥资源的优势,达到高效率。也就是说:操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好。因此,MPP 系统在决策支持和数据挖掘方面显示了优势。
-
SMP 的优势:
MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点。在通讯时间多的时候,那MPP系统可以充分发挥资源的优势。因此当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。
-
NUMA 架构的优势:
NUMA 架构来看,它可以在一个物理服务器内集成许多CPU,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同CPU模块之间的数据交互。显然,NUMA架构更适用于OLTP事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使CPU的利用率大大降低。
转载请注明:IT运维空间 » 运维技术 » 五分钟理解服务器 SMP、NUMA、MPP 三大体系结构
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/8.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论