

本文通过一个经典的分布式缓存的应用场景来阐述为什么需要一致性Hash。
1. 场景描述
我们有3万张图片的存储需求,通过评估单台服务器的存储能力后,需要用三台服务器,编号为0号、1号、2号来缓存这些图片。我们希望这些图片被均匀的缓存到这3台服务器上,以便它们最大化的分摊缓存的压力。那么,我们应该怎样实现呢?
如果我们平均的将图片缓存在3台服务器上,可以满足我们的要求吗?可以!但是应该没有人会这样粗暴的分配。因为没有建立图片和机器的索引信息,当我们需要访问某个图片时,则需要遍历3台缓存服务器,从3万个缓存项中找到我们需要访问的对象,效率太低。缓存的目的就是提高速度,进而改善用户体验,减轻后端服务器压力。那么,我们该怎么办呢?比较好的做法就是对缓存项进行哈希分配存储。假设我们使用图片名称作为访问图片的key,那么,通过如下公式,查询图片存放在哪台服务器上的时间复杂度就是O(1)。
node_number = hash(key) % N # 其中 N 为节点数。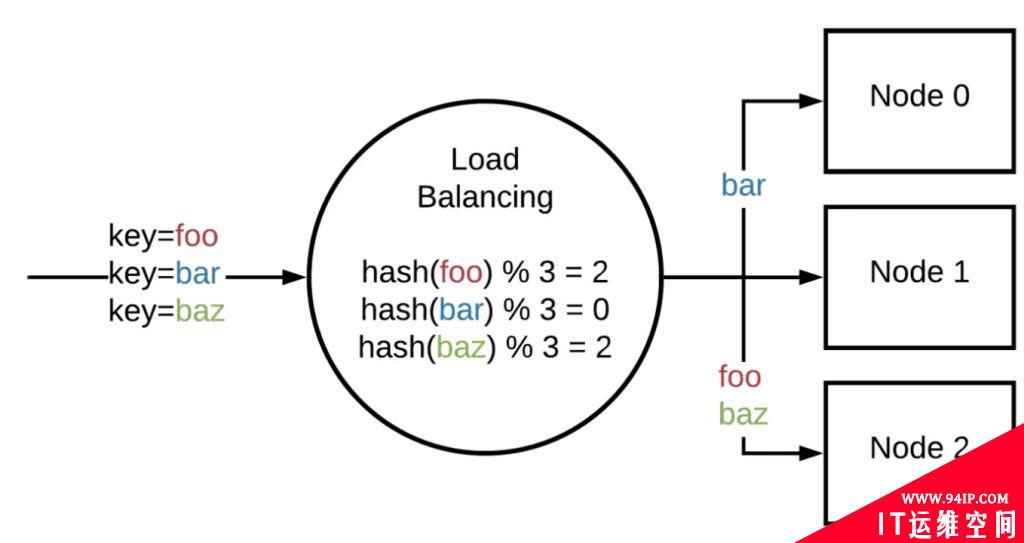
但这个方式不是很灵活,表现在对系统做扩容或者缩容时,必须迁移改变了映射关系的数据,否则会出现查询不到数据的问题。但对于分布式缓存这种的系统而言,映射规则失效就意味着之前缓存的失效,若同一时刻出现大量的缓存失效,则可能会出现 “缓存雪崩”,这将会造成灾难性的后果。
要解决此问题,我们必须在健康的节点上重新分配所有现有键,随着键的增长,数据迁移的代价将是非常昂贵的,并且可能对正在运行的系统产生不利影响。当然除了重新分配所有现有键的方案之外,还有另一种更好的方案即使用一致性哈希算法。
2. 经典一致性哈希算法的基本概念
1997年,Karger等人发布了论文 《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the WWW》 ,并提出了一致性哈希。在论文中还对一致性哈希的算法好坏定义给出了4个评判指标:
评判指标
- 平衡性(Balance):不同key的哈希结果分布均衡,尽可能的均衡地分布到各节点上。
- 单调性(Monotonicity):当可用存储桶的集合发生更改时,只有在必要时才移动项目以保持均匀的分布。
- 分散性(Spread):由于客户端可能看不到后端的所有服务,这种情况下对于固定的key,在两个客户端上可能被分散到不同的后端服务,从而降低后端存储的效率,所以算法应该尽量降低分散性。
- 服务器负载均衡(Load):负载主要是从服务器的角度来看,指各服务器的负载应该尽量均衡
Karger等人在后续的论文 《Web caching with consistent hashing》 中提出了一致性哈希的实现,也就是大家常称的环割法。
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
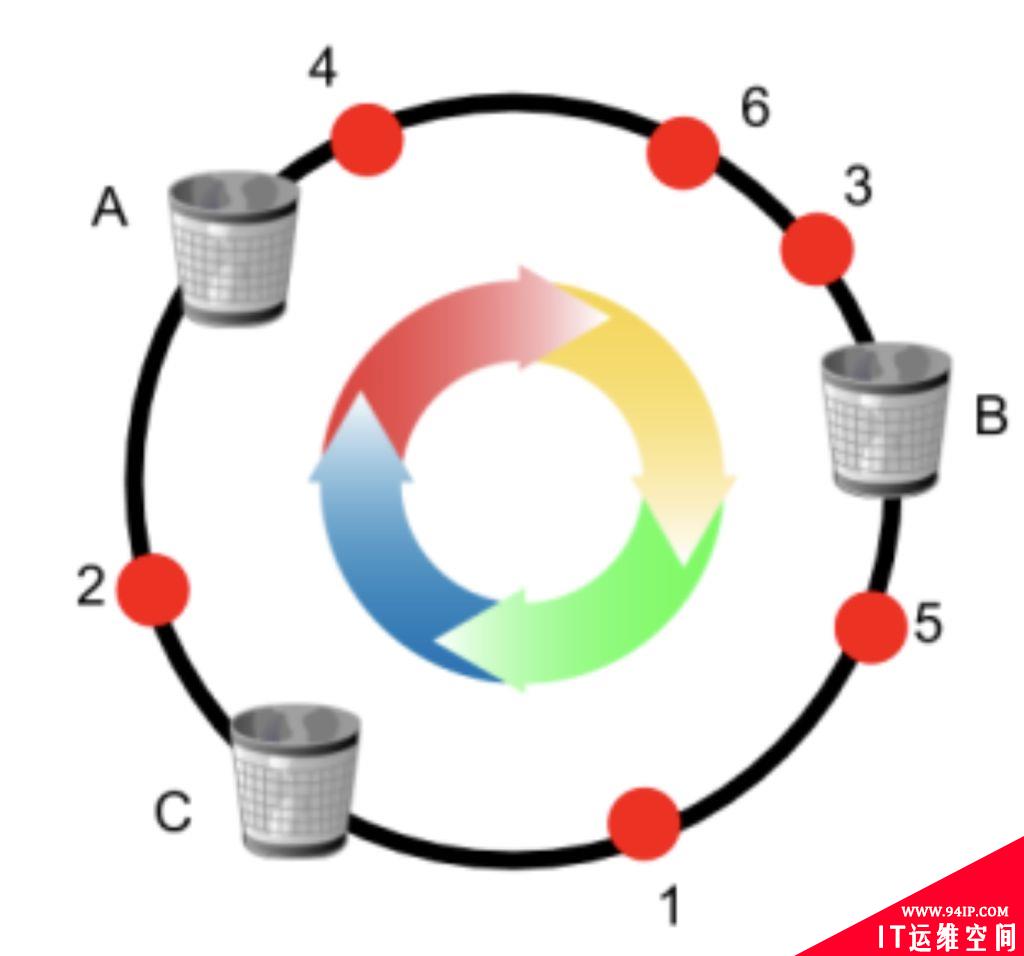
我们可以把一致哈希算法是对 2^32 进行取模运算的结果值组织成一个圆环,就像钟表一样,钟表的圆可以理解成由 60 个点组成的圆,而此处我们把这个圆想象成由 2^32 个点组成的圆,这个圆环被称为哈希环,如下图:
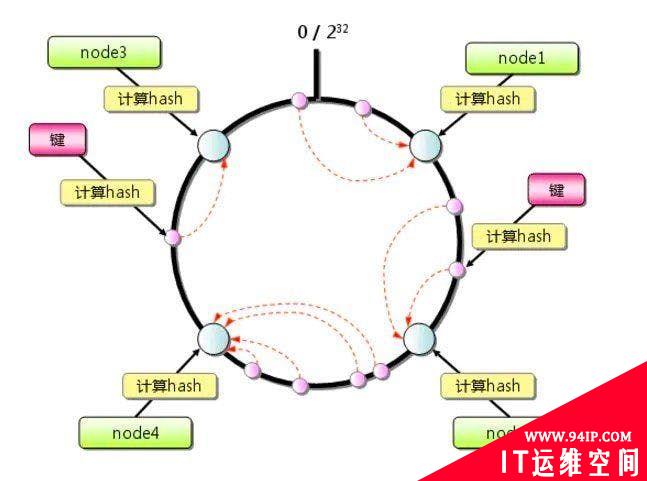
读取缓存的步骤:
- 计算 node 哈希值,将其映射到 0 ~ 2^32 范围内
- 读取缓存时,计算缓存键对应的哈希值,映射到同一个圆上
- 顺时针查找圆,遇到的第一个 node
- 其上读取缓存,如果没有,那么更新缓存
更新缓存步骤:类似「读取缓存」
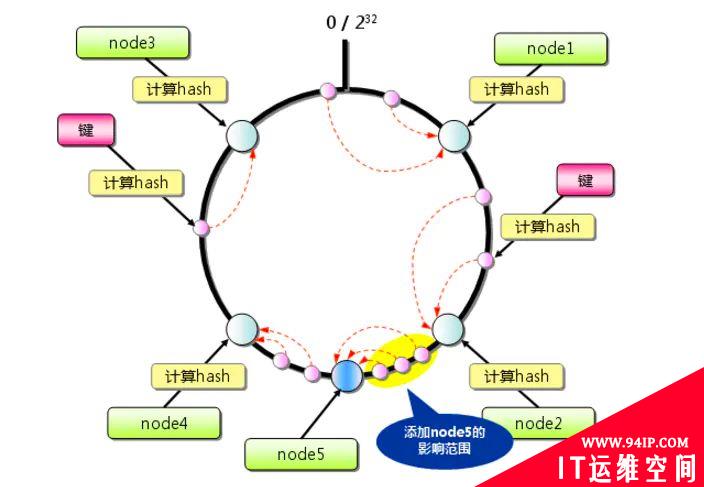
当 node 失效时,或者新加 node 时,只会有一部分缓存会变动,如上所示。
一致性hash解决了扩缩容的问题,随着数据量的增长,它还有个潜在风险,即:数据倾斜问题。我们应该怎样防止hash环的偏斜呢?我们继续聊。
虚拟节点
话接上文,由于我们只有3台服务器,当我们把服务器映射到hash环上的时候,很有可能出现hash环偏斜的情况,当hash环偏斜以后,缓存往往会极度不均衡的分布在各服务器上,如果想要均衡的将缓存分布到3台服务器上,最好能让这3台服务器尽量多的、均匀的出现在hash环上。但是,真实的服务器资源只有3台,我们怎样凭空的让它们多起来呢,没错,就是凭空的让服务器节点多起来,既然没有多余的真正的物理服务器节点,我们就只能将现有的物理节点通过虚拟的方法复制出来,这些由实际节点虚拟复制而来的节点被称为”虚拟节点”。加入虚拟节点以后的hash环如下。
“虚拟节点”是”实际节点”(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节点。
如果服务节点太少,假设上图中,只有 node1 和 node3,那么大多数的缓存会落到 node1。解决方法:每个 node,生成对应随机的 node 节点即可。例如 node1 生成 node1#1、node1#2;node2 生成 node2#1、node2#2。虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大。
3. 算法具体实现
3.1. ketama 算法
ketama 算法是最常用的一种实现,被广泛应用在存储及其他缓存场景中,如memcache、redis,nginx、envoy等。
算法核心思路
- 从配置文件中读取服务器节点列表,包括节点的地址及权重配置。
- 根据节点的权重为每个节点生成几个虚拟节点,默认的基准是每个节点160个虚拟节点,每个节点会生成IP:PORT-1、IP:PORT-2到IP:PORT-40共40个字符串,并以此算出40个16字节的hash值(其中hash算法采用的md5),每个hash值生成4个4字节的hash值,总共40*4=160个hash值,对应160个虚拟节点。
- 把所有的hash值及对应的节点地址存到一个continum存组中,并按hash值排序方便后续二分查找
优点:
- 满足单调性的指标
- 复杂度:算法复杂度为log(vn);其中n为节点数,v为每个节点的虚拟节点数(默认160)
- 实现简单广泛被使用
缺点:
- 占用内存较大:内存占用v*n
- 虚拟节点数少的情况下,平衡性较差
3.2. 集合哈希(Rendezvous hashing)
集合哈希,也称为最高随机权重哈希(HRW)。在1996年的论文 《A Name-Base Mapping Scheme for Rendezvous》 中发布,让多个客户端对各key映射到后端ñ个服务达成共识。
算法思路
这个算法比较简单,主要思路:给定一个Key,对每个节点都通过哈希函数hash()计算一个权重值wi,j = hash(Keyi, Nodej),然后在所有的权重值中选择最大一个S=Max{wi,j}。空间复杂度O(1),但算法的复杂度是O(n)。
特点:
- 负载均衡:由于散列函数随机化,并且可加权重。
- 高命中率:由于所有在客户端上对key映射是一样的。除非是替换hash算法等,否则总是会命中对应的S。
- 节点S变动导致的干扰小:当站点S发生故障时,只是需要重新映射到原映射到该站点的对象。
适合场景:
- 经典一致性哈希需要存储,HRW不需要预先存储
- 适合S个数少的情况,S比较多的时候耗时也较长,算法复杂度为O(n)
复杂度改良
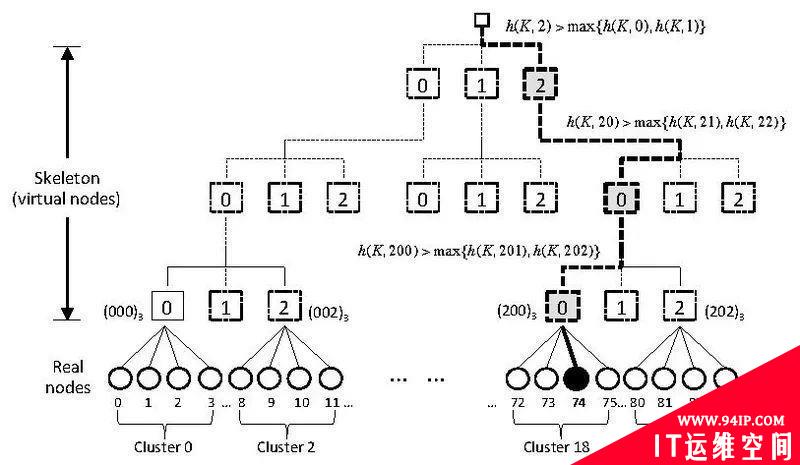
针对S较多的场景,有人提出了改进的方法:Skeleton-based variant
将S组织成tree的结构:假设我们有108个节点,选择一个常数m(图中是4),计算出c=108/4=27组节点,构成一个树
如图找到组节点后,再计算出真实节点的hash并选择最大的那个,即为访问结果。
优缺点:复杂度为O(logn),缺点是扩缩容后,在reblance的时候花费时间较长。
3.3. 跳转一致性哈希(Jump consistent hash)
Jch是Google于2014年的论文 《A Fast, Minimal Memory, Consistent Hash Algorithm》 提出的一种一致性哈希算法。它的特点是用内存小且速度很快,并且只有5行代码,比较适合用在分shard的分布式存储系统中,目前在Google的java库guava等有应用。
算法目标
平衡性:对象均匀分布。单调性:bucket的数量变化时,只需把少部分旧对象移到新桶。
算法思路
实例数从n变化到n+1后,change(k,n+1) 的结果中,应该有占比 n/(n+1) 的结果保持不变,而有 1/(n+1) 跳变为 n+1。通过[0,1]区间的key做随机种子取随机变量,来决定当次是否跳变,最终返回最后一次跳变的结果。
int change(int key, int num_buckets) {
random.seed(key) ;
int b = 0; // b will track ch(key, j +1) .
for (int j = 1; j < num_buckets; j ++) {
if (random.next() < 1.0/(j+1) ) b = j ;
}
return b;
}算法是O(n)的。随着j增大,随机数小于1/(j+1)的概率很小,所以作者引入了一个随机数r,通过r得到了j。将代码复杂度进行了改进:
int change(int key, int num_buckets) {
random. seed(key) ;
int b = -1; // bucket number before the previous jump
int j = 0; // bucket number before the current jump
while(j<num_buckets){
b=j;
double r=random.next(); // 0<r<1.0
j = floor( (b+1) /r);
}
return b;
}
算法复杂度:时间复杂度为O(log(n))。假设每次r都取0.5,则可以认为每次 j=2*j。
算法特点
优点:无需新增存储虚拟节点;结果分布的均匀性与key分布无关,由伪随机数生成器的均匀性保证,性能强复杂度为log(n)
缺点:对于中间和多个节点剔除的情况,数据仍会落到原节点,需要额外处理(主备、doublehash或管理好节点id)。由于算法特性,后台节点id需要是有序的int,或者管理好节点id。
3.4. 有界载荷一致性哈希 Consistent Hashing with Bounded Loads
当一致性hash的key本身不均匀时可能会导致服务器过载。Google在2017年发布论文《Consistent Hashing and Random Trees:Distributed Caching Protocols for Relieving Hot Spots on the www》,对一致性哈希做了改进,目的是当服务器伸缩后,最大程度地减少之后的移动次数,并且最大程度地减少任何服务器的最大负载。
算法思路
假设有m个请求和n个服务 定义c = 1+ε > 1,定义容量capacity = cm/n 如1.25。想象一个给定范围的数字,它覆盖在一个圆上。顺时针移动时,分配给第一个非满负载料箱(如果节点负载达到1.25会跳过该节点)。该算法略微降低了一致性(具体降低的程度与 ε 的设置有关),但后台服务的负载较均衡性得到了提高。
3.5. 悬浮一致性哈希 Maglev Hash
Maglev hash是Google于2016年发表的一篇论文中提出来的一种新的一致性哈希算法。
算法思路
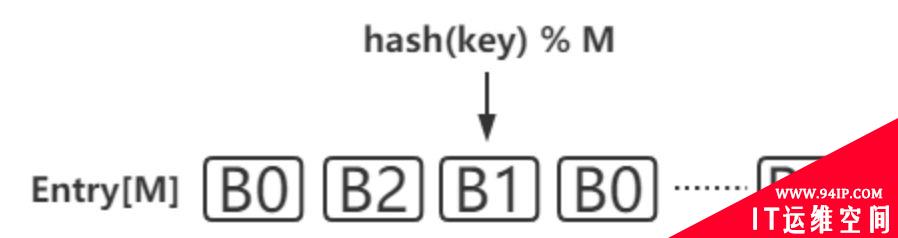
建立一张一维的查找表,如图所示,一个长度为M的列表,记录着每个位置所属的节点编号B0…BN,当需要判断某个key被分配到哪个节点的时候,只需对key计算hash,然后对M取模看所落到的位置属于哪个节点。
算法特点
Maglev hash虽然没有做到最小重新映射。但是实验测试表明随着后端节点故障百分比的增加,槽位映射结果发生变化的百分比也在增加,在查找表大小比较大的情况下,Maglev hash对后端节点的增删有更好的容忍性。
4. 总结
本文通过示例介绍了传统的哈希取模算法在分布式系统中的局限性,进而在针对该问题的解决方案中引出了一致性哈希算法。下面简单地以一个表格对以上四种一致性哈希算法进行对比总结:
| 算法 | 扩容 | 缩容 | 平衡性 | 单调性 | 稳定性 | 时间复杂度 |
| Ketama | 好 | 好 | 较好 | 好 | 较好 | O(log vn) |
| Rendezvous | 好 | 好 | 较好 | 好 | 较好 | O(n) |
| Jump consistent hash | 好 | 需要额外处理 | 好 | 好 | 好 | O(ln n) |
| Maglev hash | 较好 | 较好 | 好 | 较好 | 较好 | O(MlogM),最坏O(M*M) |
转载请注明:IT运维空间 » linux » 什么是一致性Hash,及其应用场景详解
你可能喜欢:
-

MySQL与JDBC之间的SQL预编译技术讲解
-

详解MySQL Shell 运行 SQL 的两种内置方法
-

mysql错误:java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone.
-

ORACLE SQL TUNING ADVISOR 使用方法
-

通用的关于sql注入的绕过技巧(利用mysql的特性)
-

mysql 生成UUID() 即 ORACLE 中的guid()函数
-

执行多条SQL语句,实现数据库事务。(Oracle数据库)
-

Oracle DBA常用SQL
-

MySQL架构优化实战系列4:SQL优化步骤与常用管理命令
-

探究MySQL中SQL查询的成本












发表评论