

背景
Redis 作为目前使用最广泛的缓存,搭配MySQL的使用场景相信大家都不陌生。因为 Redis 是内存数据库,我们可以将数据库的数据缓存在 Redis 里,相当于数据缓存在内存,内存的读写速度比硬盘快好几个数量级,这样大大提高了系统性能。使用缓存并没有这么简单,引入了缓存层,就会有缓存异常的三个问题,分别是缓存雪崩、缓存击穿、缓存穿透。那什么是缓存雪崩,击穿,穿透呢?出现这些问题又怎么解决呢?
下面以常见的Redis缓存组件为例来讲解这三种场景及解决方案。带领大家逐一解答这些问题。
示例缓存架构
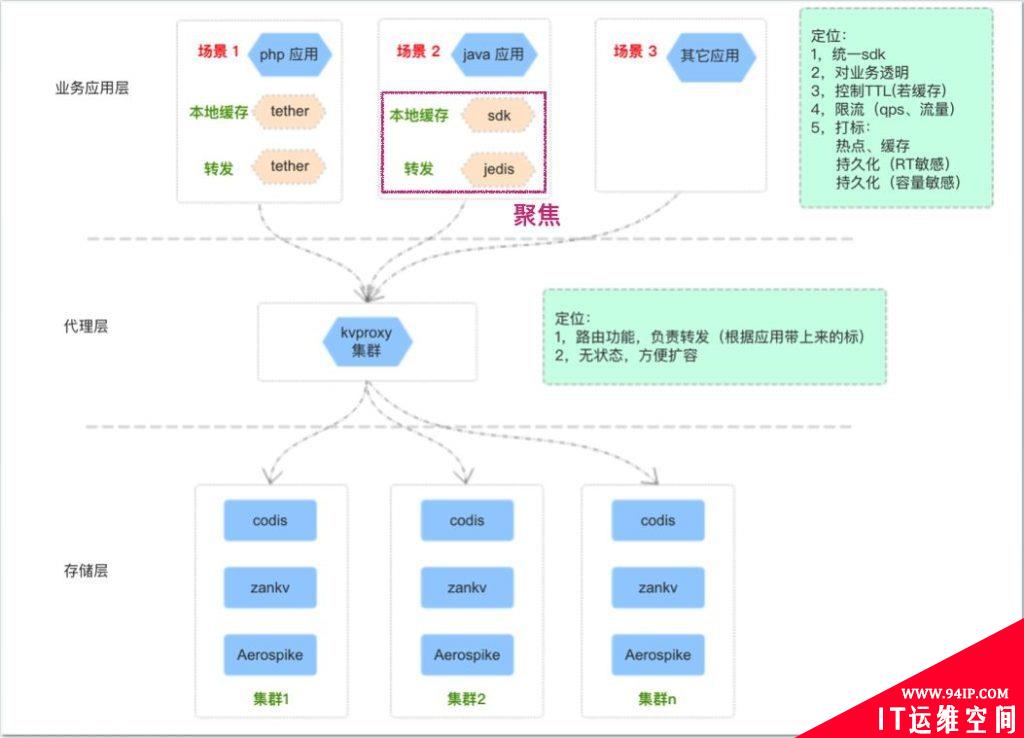
TMC,即“透明多级缓存(Transparent Multilevel Cache)”,是有赞 PaaS 团队给公司内应用提供的整体缓存解决方案。
TMC 整体架构如上图,共分为三层:
- 存储层:提供基础的 kv 数据存储能力,针对不同的业务场景选用不同的存储服务(codis/zankv/aerospike);
- 代理层:为应用层提供统一的缓存使用入口及通信协议,承担分布式数据水平切分后的路由功能转发工作;
- 应用层:提供统一客户端给应用服务使用,内置“热点探测”、“本地缓存”等功能,对业务透明;
当我们使用缓存时,目标通常有两个:第一,提升响应效率和并发量;第二,减轻数据库的压力。而本文中所提到的这三种场景:缓存穿透、缓存雪崩和缓存击穿的发生,都是因为在某些特殊情况下,缓存失去了预期的功能所致。
当缓存失效或没有抵挡住流量,流量直接涌入到数据库,在高并发的情况下,可能直接击垮数据库,导致整个系统崩溃。
这就是我们需要知道的大前提,而缓存穿透、缓存雪崩和缓存击穿,只不过是在这个大前提下的不同场景的细分场景而已。
缓存雪崩
大量的应用请求无法在Redis缓存中进行处理(比如:为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存),紧接着应用将大量请求发送到数据库层,导致数据库层的压力激增。
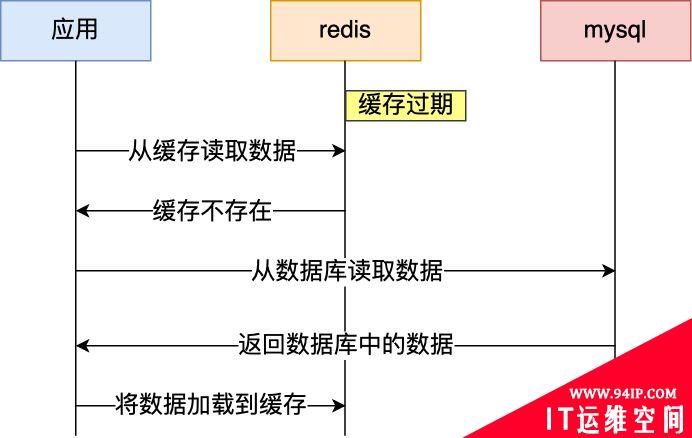
当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求进来,因为Redis不可服务,全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,这就是缓存雪崩。
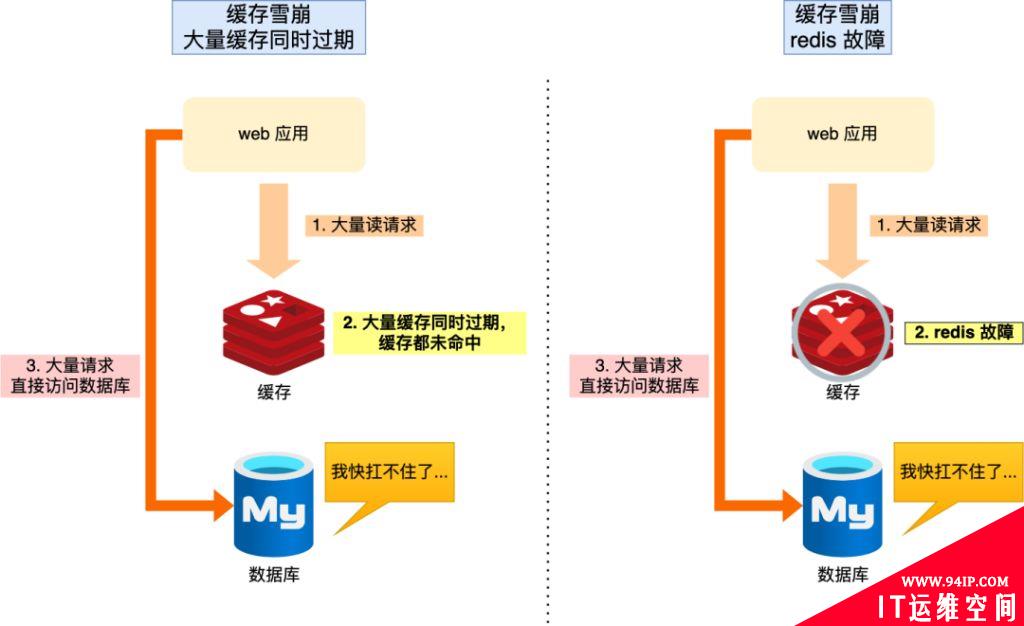
可以看到,发生缓存雪崩有多个原因:
原因一:缓存中有大量Key同时过期,导致大量请求无法得到处理,大量数据需要回源数据库
- 方案一 差异化设置过期时间:差异化缓存过期时间,不要让大量的 Key 在同一时间过期。比如,在初始化缓存的时候,给这些数据的过期时间增加一个较小的随机数,这样一来不同数据的过期时间有所差别又差别不大,即避免了大量数据同时过期又能保证这些数据在相近的时间失效
- 方案二服务降级:允许核心业务访问数据库,非核心业务直接返回预定义的信息
- 方案三后台更新缓存,不设置过期时间:初始化缓存数据的时候设置缓存永不过期,然后启动一个后台线程 30 秒一次定时把所有数据更新到缓存,而且通过适当的休眠,控制从数据库更新数据的频率,降低数据库压力。事实上,缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为当系统内存紧张的时候,有些缓存数据会被“淘汰”,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。解决上面的问题的方式有两种。第一种方式,后台线程不仅负责定时更新缓存,而且也负责频繁地检测缓存是否有效,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库读取数据,并更新到缓存。这种方式的检测时间间隔不能太长,太长也导致用户获取的数据是一个空值而不是真正的数据,所以检测的间隔最好是毫秒级的,但是总归是有个间隔时间,用户体验一般。第二种方式,在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。这种方式相比第一种方式缓存的更新会更及时,用户体验也比较好。在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,这就是所谓的缓存预热,后台更新缓存的机制刚好也适合干这个事情。
- 方案四互斥锁。当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。
- 方案四双key策略,主key设置过期时间,备key不设置过期时间,当主key失效时,直接返回备key值。
原因二:Redis实例发生故障宕机,无法处理请求,就会导致大量请求积压到数据库层
- 方案一 服务熔断:暂停业务应用对缓存服务的访问,从而降低对数据库的压力
- 方案二 请求限流:控制每秒进入应用程序的请求数,避免过多的请求被发到数据库
- 方案三 Redis构建高可靠集群:通过主从节点的方式构建Redis高可靠集群。可以保证在Redis主节点故障宕机时,从节点切换到主节点,继续提供服务,避免由于缓存实例宕机导致缓存雪崩
缓存击穿
缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db,属于常见的“热点”问题
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
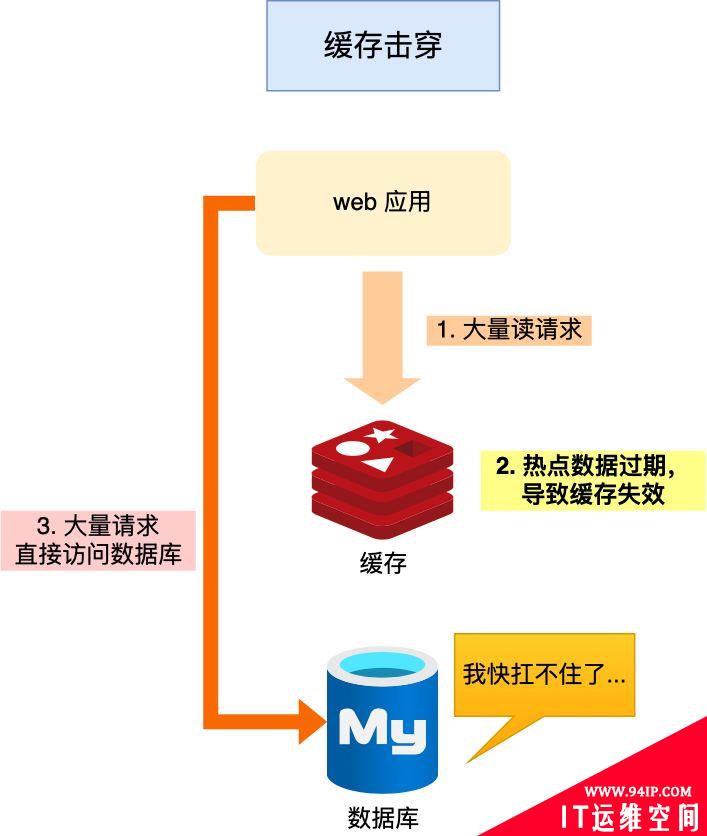
可以发现缓存击穿跟缓存雪崩很相似,你可以认为缓存击穿是缓存雪崩的一个子集。应对缓存击穿可以采取前面说到两种方案:
- 预先设置热门数据,提前存入缓存
- 实时监控热门数据,调整key过期时长
- 二级缓存:对于热点数据进行二级缓存,并对于不同级别的缓存设定不同的失效时间。
- 设置分布式锁:保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
缓存穿透
缓存穿透是指客户端请求的数据既不在缓存中,也不在数据库中,这样缓存永远不会生效,这些请求都会被打倒数据库上。
即这个数据根本不存在,如果黑客攻击时,启用很多个线程,一直对这个不存在的数据发送请求 ,那么请求就会一直被打到数据库上,很容易将数据库打崩。
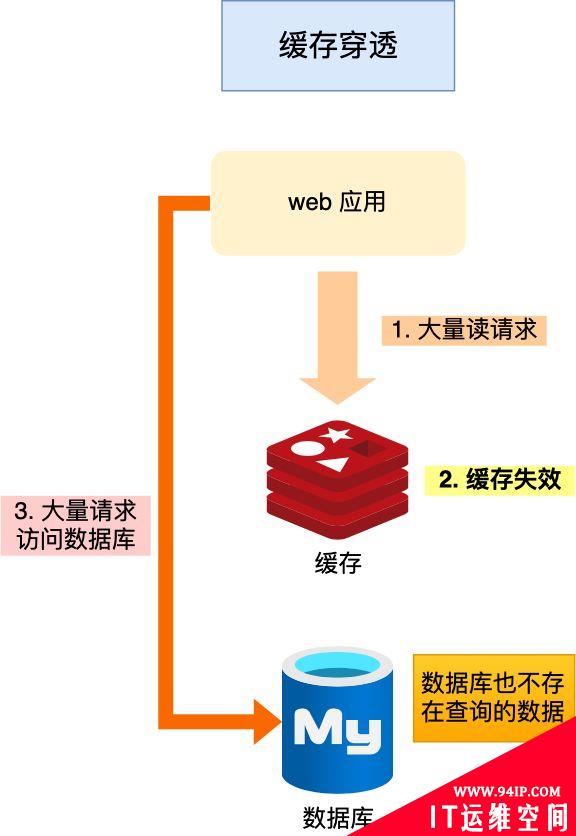
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
应对缓存穿透的方案,常见的方案有三种。
- 第一种方案非法请求的限制(使用bitmaps类型定义访问白名单,或进行实时监控,和运维人员配合排查访问对象和访问数据设置黑名单限制服务):当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
- 第二种方案缓存空值或者默认值;当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
- 第三种方案使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
布隆过滤器的原理:由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中,但是如果查到了,因为hash冲突也不能说明数据一定在数据库中。
一张图总结:
击穿与雪崩的区别即在于击穿是对于特定的热点数据来说,而雪崩是全部数据。
缓存异常会面临的三个问题:缓存雪崩、击穿和穿透。
其中,缓存雪崩和缓存击穿主要原因是数据不在缓存中,而导致大量请求访问了数据库,数据库压力骤增,容易引发一系列连锁反应,导致系统奔溃。不过,一旦数据被重新加载回缓存,应用又可以从缓存快速读取数据,不再继续访问数据库,数据库的压力也会瞬间降下来。因此,缓存雪崩和缓存击穿应对的方案比较类似。
而缓存穿透主要原因是数据既不在缓存也不在数据库中。因此,缓存穿透与缓存雪崩、击穿应对的方案不太一样。

转载请注明:IT运维空间 » linux » 缓存雪崩、缓存击穿、缓存穿透及其解决方案详细介绍
你可能喜欢:
-

MySQL与JDBC之间的SQL预编译技术讲解
-

详解MySQL Shell 运行 SQL 的两种内置方法
-

mysql错误:java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone.
-

ORACLE SQL TUNING ADVISOR 使用方法
-
通用的关于sql注入的绕过技巧(利用mysql的特性)
-

mysql 生成UUID() 即 ORACLE 中的guid()函数
-

执行多条SQL语句,实现数据库事务。(Oracle数据库)
-

Oracle DBA常用SQL
-

MySQL架构优化实战系列4:SQL优化步骤与常用管理命令
-

探究MySQL中SQL查询的成本













发表评论