

文件的读写方式各有千秋,对于文件的 I/O 分类也非常多,常见的有
- 缓冲与非缓冲 I/O
- 直接与非直接 I/O
- 阻塞与非阻塞 I/O VS 同步与异步 I/O
接下来,分别对这些分类讨论讨论。
缓冲与非缓冲 I/O
文件操作的标准库是可以实现数据的缓存,那么根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O:
- 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
- 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
这里所说的「缓冲」特指标准库内部实现的缓冲。
比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数,毕竟系统调用是有 CPU 上下文切换的开销的。
直接与非直接 I/O
我们都知道磁盘 I/O 是非常慢的,所以 Linux 内核为了减少磁盘 I/O 次数,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是「页缓存」,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
那么,根据是「否利用操作系统的缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O:
- 直接 I/O,不会发生内核缓存和用户程序之间数据复制,而是直接经过文件系统访问磁盘。
- 非直接 I/O,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
如果你在使用文件操作类的系统调用函数时,指定了 O_DIRECT 标志,则表示使用直接 I/O。如果没有设置过,默认使用的是非直接 I/O。
如果用了非直接 I/O 进行写数据操作,内核什么情况下才会把缓存数据写入到磁盘?
以下几种场景会触发内核缓存的数据写入磁盘:
- 在调用 write 的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上;
- 用户主动调用 sync,内核缓存会刷到磁盘上;
- 当内存十分紧张,无法再分配页面时,也会把内核缓存的数据刷到磁盘上;
- 内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上;
阻塞与非阻塞 I/O VS 同步与异步 I/O
为什么把阻塞 / 非阻塞与同步与异步放一起说的呢?因为它们确实非常相似,也非常容易混淆,不过它们之间的关系还是有点微妙的。
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:
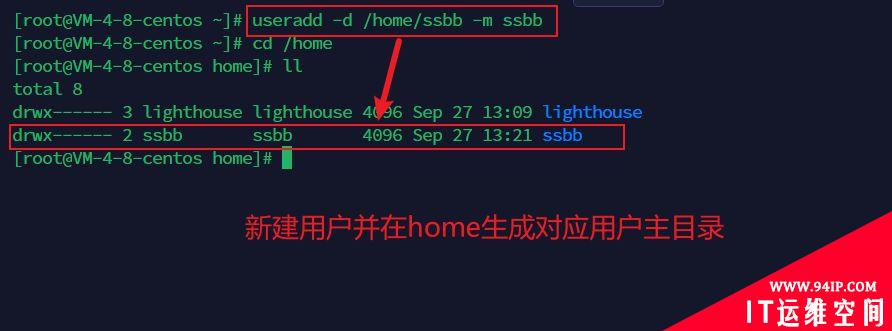
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
举个例子,访问管道或 socket 时,如果设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
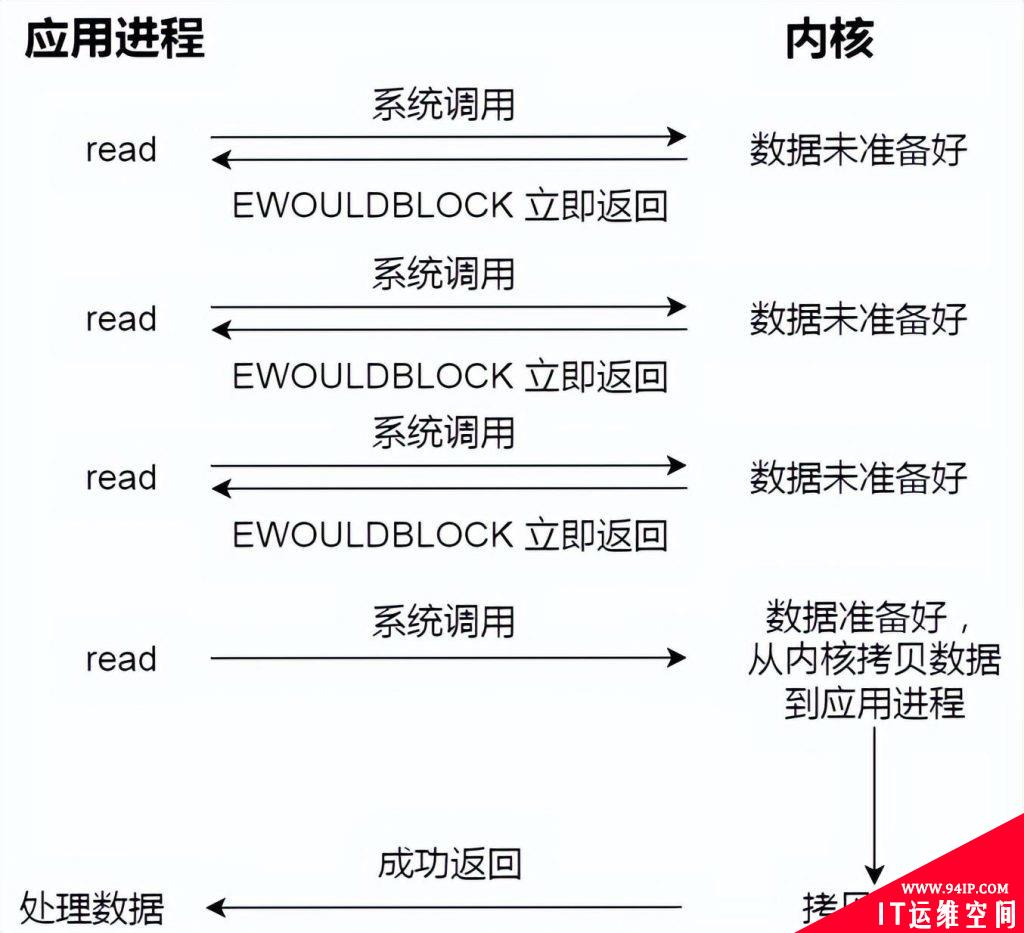
为了解决这种傻乎乎轮询方式,于是 I/O 多路复用技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
下图是使用 select I/O 多路复用过程。注意,read 获取数据的过程(数据从内核态拷贝到用户态的过程),也是一个同步的过程,需要等待:
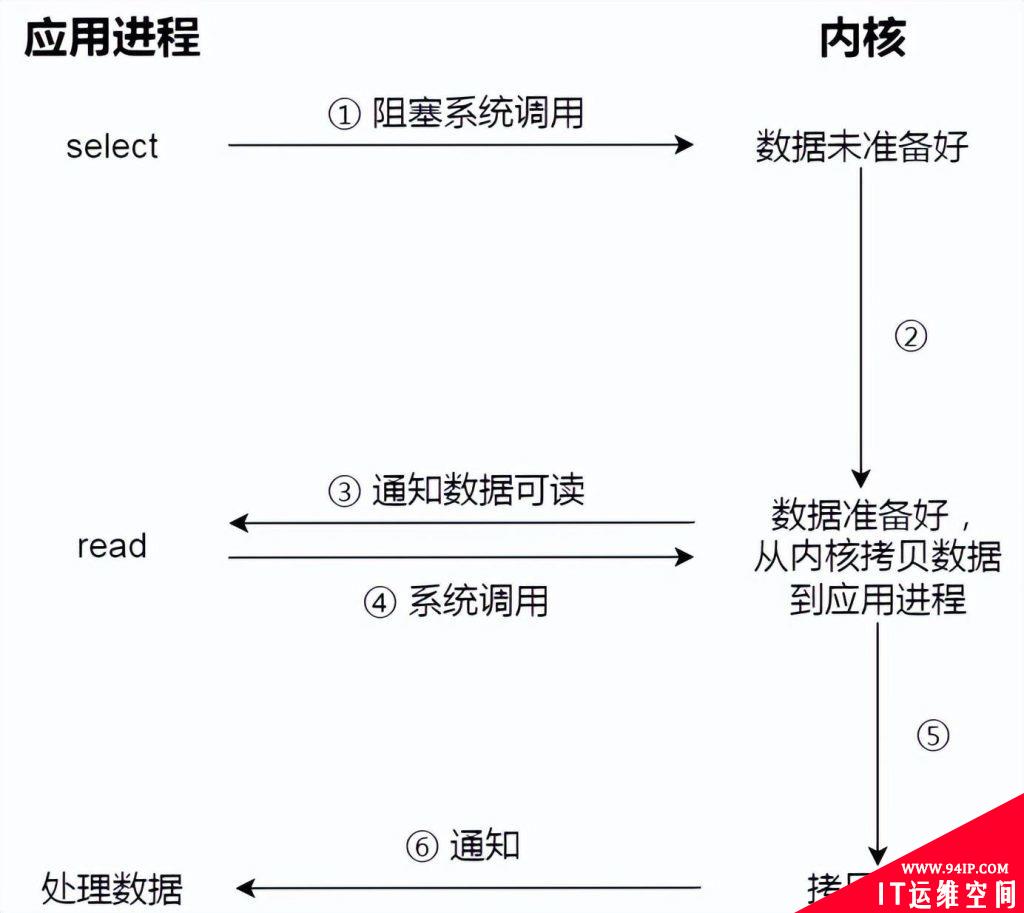
实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
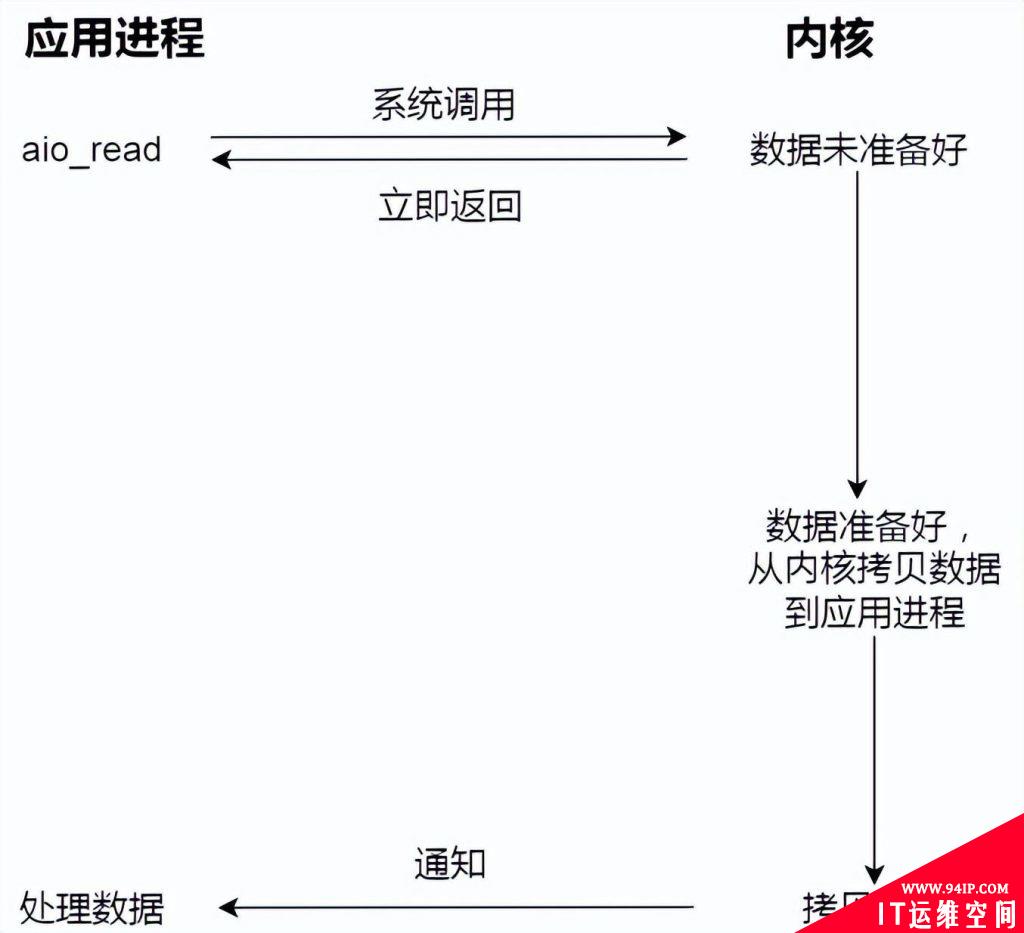
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
下面这张图,总结了以上几种 I/O 模型:
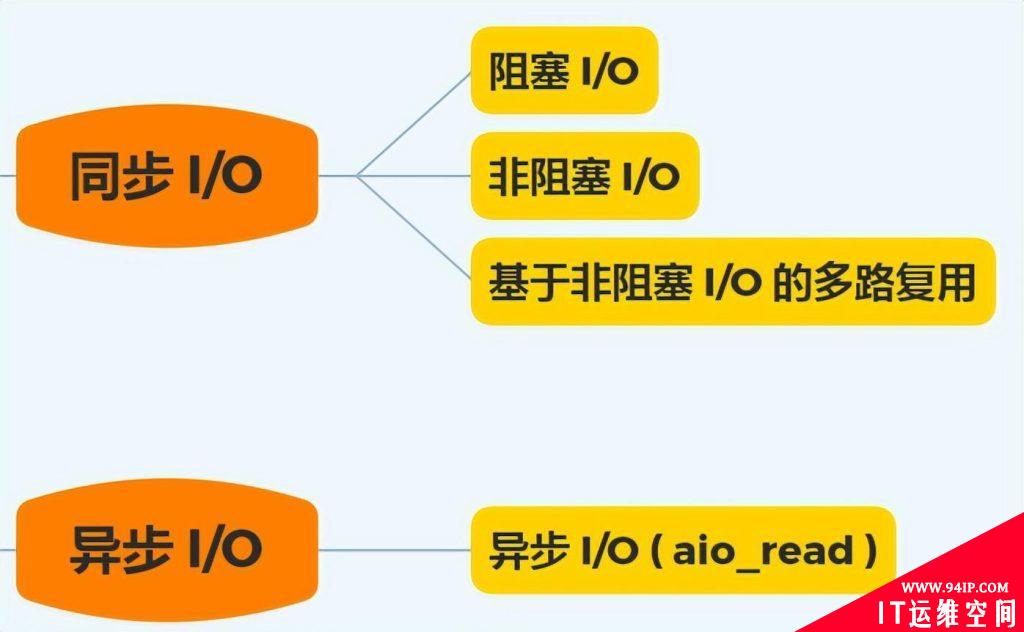
在前面我们知道了,I/O 是分为两个过程的:
- 数据准备的过程
- 数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。
异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。
用故事去理解这几种 I/O 模型
举个你去饭堂吃饭的例子,你好比用户程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
基于非阻塞的 I/O 多路复用好比,你去饭堂吃饭,发现有一排窗口,饭堂阿姨告诉你这些窗口都还没做好菜,等做好了再通知你,于是等啊等(select 调用中),过了一会阿姨通知你菜做好了,但是不知道哪个窗口的菜做好了,你自己看吧。于是你只能一个一个窗口去确认,后面发现 5 号窗口菜做好了,于是你让 5 号窗口的阿姨帮你打菜到饭盒里,这个打菜的过程你是要等待的,虽然时间不长。打完菜后,你自然就可以离开了。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
转载请注明:IT运维空间 » linux » Linux文件 I/O 分类详解
你可能喜欢:
-

MySQL与JDBC之间的SQL预编译技术讲解
-

详解MySQL Shell 运行 SQL 的两种内置方法
-

mysql错误:java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone.
-

ORACLE SQL TUNING ADVISOR 使用方法
-

通用的关于sql注入的绕过技巧(利用mysql的特性)
-
mysql 生成UUID() 即 ORACLE 中的guid()函数
-

执行多条SQL语句,实现数据库事务。(Oracle数据库)
-

Oracle DBA常用SQL
-

MySQL架构优化实战系列4:SQL优化步骤与常用管理命令
-

探究MySQL中SQL查询的成本











发表评论