

作者 | 郑智献
背景
行为序列模型相对于传统机器学习的主要优势在于不依赖行为画像特征,无需强专家经验挖掘高效特征来提升模型性能,缩短了特征工程的周期,能快速响应黑产攻击。 黑产通过刷接口、群控、真人众包等作弊手段在关注、点赞、评论等核心场景进行攻击。不同作弊方式在行为序列上有不同的特点。刷接口、群控作弊属于机器作弊,行为序列呈现团伙相似性、序列周期性 / 密集性。真人众包主要通过线下软件分发任务真人账号执行,行为链路具有比较固定模式以上作弊方式在行为序列上具有显著性,所以在风控业务上序列模型有很好的落地能力。
序列相似性检测
目的
在反作弊场景,经常会发现黑产的行为序列经常会出现重复的片段比如 11332221133222 ( 数字表示 api 接口埋点映射的数字编号),其中 1133222 为重复片段 或者会发现不同黑账号行为序列的相似度很高比如账户 A 行为序列 135555566 账户 B 的行为序列为 13555666。这是因为黑产利用脚本批量控制账号进行动作周期的重复或者非周期动作账户之间的重复,导致了黑产的行为序列度呈现一定的相似性、周期性。所以利用序列相似检测算法对黑产进行识别,相似性检测序列大都为单序列。
如何定义单序列?
单行为序列是指用户仅只有单个动作构成了序列,可抽象表达为 X=(x_1, x_2..x_i..x_n) 其中 x_i 表示具体的行为动作
技术方案
以上背景可归纳为以下两种作弊类 作弊序列特征:
-
机刷性:同一作弊用户行为序列片段相似
团伙性:不同作弊用户之间行为序列相似
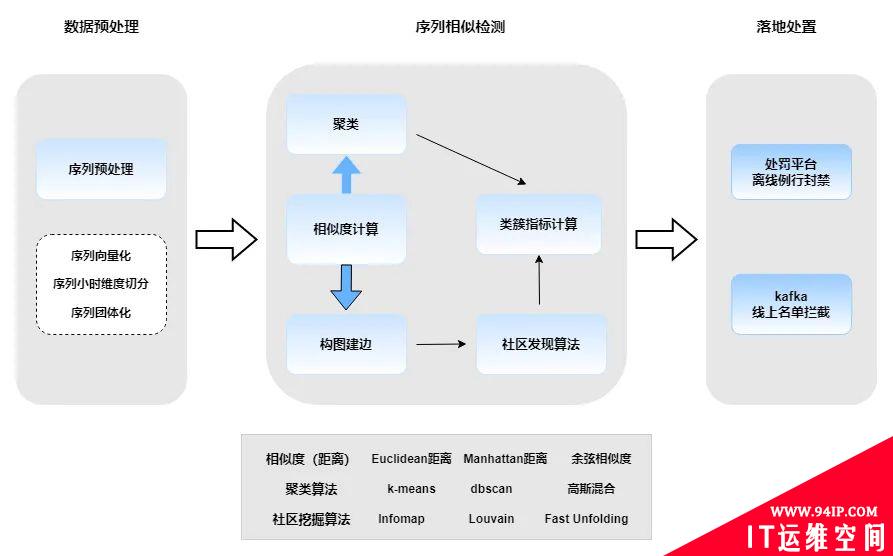
序列相似检测流程分为数据预处理、序列相似检测、落地处置三部分。机刷性和团伙性的作弊序识别的区别在于序列预处理阶段是否进行切割,在后续相似检及落地处置保持一致。序列相似检测算法有以下两种流程:
-
聚类:对向量化后的序列使用聚类算法,筛选序列高聚集团伙。
社区发现:对向量化序列进行建图(序列相似度计算小于阈值建边),建图后用社区发现序列高聚集团伙 。
序列深度模型
目的
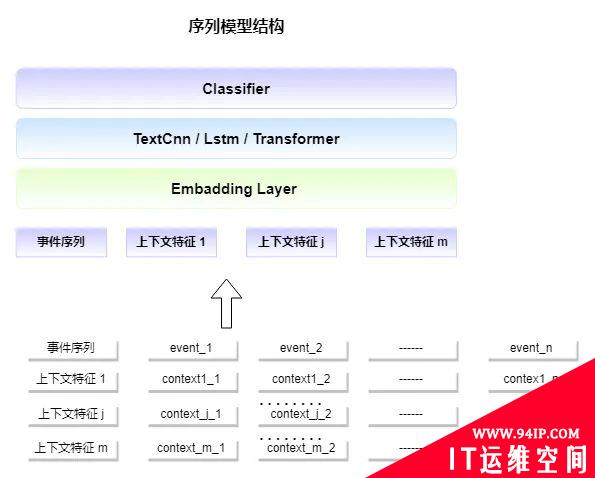
随着平台反作弊方案的深化,黑产作弊难以在单一场景完成,需要在多个动作链路上规避场景的拦截手段,单序列动作建模只考虑了动作本身,动作上下文信息没有被充分利用。例如 A 用户两次点赞的时间隔相差 1min,而 B 用户两次点赞之间仅相差 0.01s,在单序列动作建模中是没有区分,但是如果将点赞时间间隔作为特征融入单序列就能有效识别 A/B 用户行为的区别。用户发生一个动作的时,该动作伴的附属特征比如设备信息,软件信息,ip 信息等也都是非常有意义。基于上述分析,希望构建一种结合用户上下文信息的多维混合行为序列,来完成对黑产作弊更具针对性的建模。
如何从单序列衍生为上下文信息多维混合序列?

如何利用动作上下文信息?
为了充分利用动作的上下文信息对不同用户的识别,可以将动作发生的时间戳作为其特征的一部分,而后通过前后时间戳的差值来描述动作的上下文;在动作发生时,采集发生动作时刻的设备,软件,ip 等信息,对其特征处理后作为上下文。
上下文特征序列处理
1)离散值特征处理 若想描述离散特征序列相邻变化,则处理为离散值相邻变化序列,前后一致处理为 0 不一致为。这种处理适合枚举种类较多且强调变化对作弊有识别作用的序列特征,比如设备(device_id)序列。 2)续值特征处理 附加属性都是离散的类别值,但诸如用户设备电量,用户投稿数等特征却是连续的,对这类连续特征,采取幂次分桶来进行离散化,强化桶间的特征显著性。 3)时间戳特征处理 时间戳虽然属于连续值可直接进行分桶操作,但是时间间隔差值对作弊用户显著性更大,所以采取前后节点的时间戳差值后再分桶的方式进行特征处理
技术方案
技术架构
基于以上技术方案构建了一套可离线一键训练、离线例行预测(天级别 / 小时级别)、在线实时预测一体化的系统。该系统界面化操作,高可配置化参数,能实现 20min 内训练并上线上下文序列模型。
-
数据:支持自定义特征序列输入,配置化特征处理模块
参数:支持自定义模型及模型参数输入
功能:支持例行离线预测写线上名单
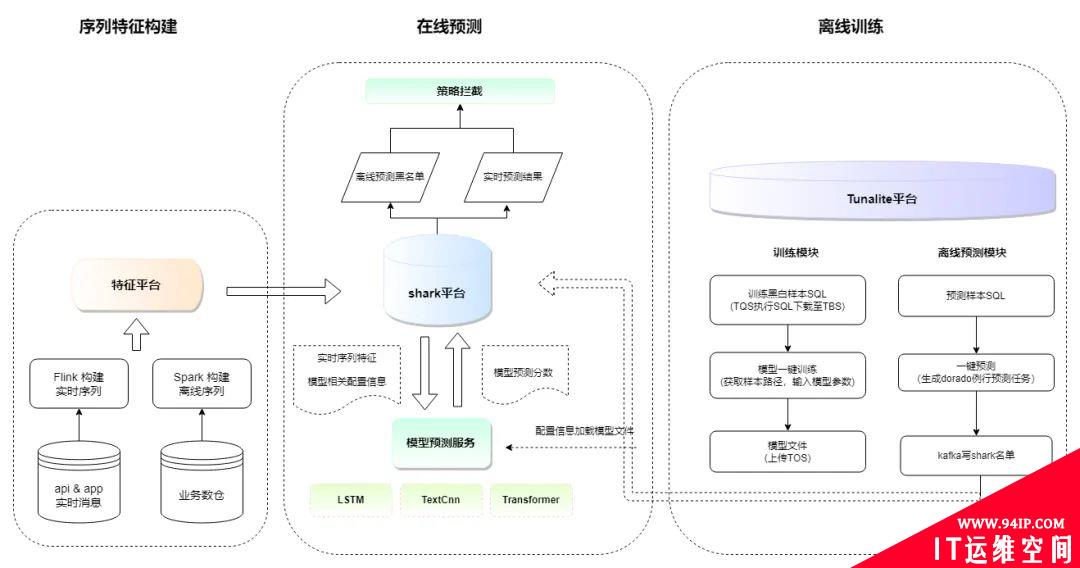 系统主要可分为特征构建、在线预测、离线训练三大部分:
系统主要可分为特征构建、在线预测、离线训练三大部分:
-
特征构建:通过特征平台构建 Flink 实时序列及 spark 离线序列作为线上序列数据的输入
离线训练:TunaLite 平台 SQL 化输入训练黑白样本且自定义选择特征处理函数、模型选型及模型参数进行一键离线训练,训练完成模型文件上传至 TOS。
在线预测:shark 决策中心调用预测服务并传入模型、特征相关参数后返回模型预测结果。
除了以上实时预测链路,提供了例行离线预测链路。方式为 SQL 化输入例行预测样本,自动生成 Dorado 例行预测任务,将预测结果通过 kafka 写入线上名单进行拦截。当业务场景调用 QPS 过大时可使用该方式进行模型落地。
历史长序列模型
目的
短时序列建模已有不少较成熟模型方案及落地实时服务,以上涉及的上下文序列模型属于短时序列方案。从用户行为画像角度,短时行为序列缺陷为只能限定步长进行序列建模,只能刻画近期局部序列信息无法刻画全局,从而使部分信息缺失。所以为了更完备序列信息就考虑到了长序列建模。从业务治理角度,短时序列方案倾向于解决行为短链路特征显著或者作弊周短的黑产,对于长链路行为比如真人众包或者长作弊周期黑产无法捕捉。
技术方案
采用的模型主要参考阿里妈妈 CTR 预估模型 MIMN,根据风控场景特性对模型精简后再迁移。模型输入为带有上下文信息行为序列,模型核心模块有 MIU(Memory Induction Unit)和 NTM(Neural Turing Machine)两部分,分别产出了记忆信息相关的 M (下图绿色矩阵)和 S (下图蓝色矩阵) 记忆矩阵来存储历史行为序列信息。
模型结构
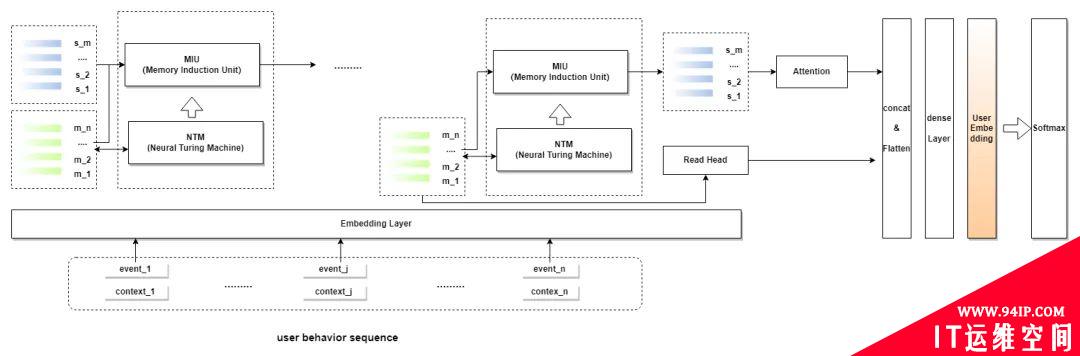
技术架构
如何进行序列增量更新?
记忆矩阵可理解为对用户行为序列 Encoder 过程的中间产物并,且浓缩了目前为止用户行为序列的所有信息。序列增量更新的过程为根据 t 步产出的记忆矩阵 和 t+1 步的行为序列 更新得到 t+1 步记忆矩阵和 t+1 步用户 Embdding,以此循环就可以得到表征历史行为序列的用户 Embdding。产出的用户 Embedding 下游可用于分类和检索。
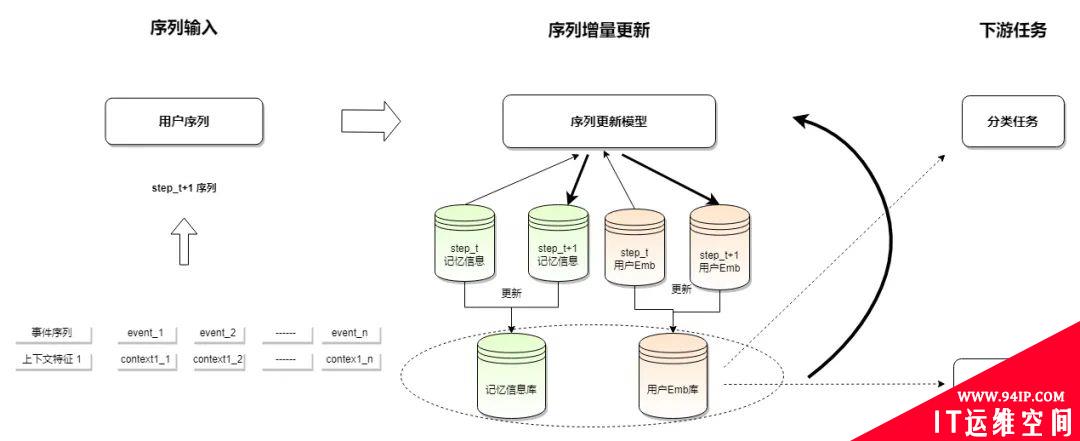
下游分类任务
类 Session 行为分布特征 + 行为序列 Embedding 作为 tunalite 平台 XGboost 算法的特征输入,并且增量召回样本特性为持续性作弊且没有被短时行为序列模型召回。
下游黑库检索任务
行为相似的用户的行为序列 Embedding 距离比较相近。检索任务就是以黑种子为中心计算黑用户行为 序列 Embedding 与其他用户行为序列 Embedding 的索引距离,选择近似 Top N 或者阈值范围内的用 户作为黑样本扩召。
转载请注明:IT运维空间 » 安全防护 » 行为序列模型在抖音风控中的应用
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-
Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-
MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-

mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-

如何在MySql中记录SQL日志(例如Sql Server Profiler)












发表评论