

前言
近年来,随着社会服务信息化的高速发展,在互联网、物联网、金融、物流、电磁等各方面数据都呈现指数级的增长。大数据的传输是大数据处理基本流程的重要一环,高性能的数据传输可以为后续数据分析特别是实时分析提供保障。本文简要介绍了主流的大数据传输方法和多源异构数据传输的设计方案,为大家提供参考。

1、大数据传输相关背景
2003年起,Google公司相继发表了Google FS、MapReduce、BigTable等3个系统(框架)的论文,说明了这3个产品的详细设计方法,为后来全球的大数据发展奠定了基础。由于数据量和效率的问题,传统的单机存储与计算已经不适应时代的发展,多节点的分布式存储逐渐取而代之,这种方法可以在多个廉价的节点上同时存储和并行计算,并且提供了很好的容错能力。
随着大数据技术的不断发展,更多高性能的处理框架走上了历史舞台,形成了大数据生态系统。例如分布式存储有HDFS、Hbase、hive等,分布式计算有MapReduce、Spark、Storm等,而作为该生态系统的重要组成部分,数据传输模块必不可少,现在比较流行的有Kafka、Logstash、Sqoop等。
在数据传输的过程中,不论是类似将文件导入数据库的离线数据传输,还是类似实时采集数据传输到数据库进行计算的实时传输,我们都希望具有高速优质的传输效率,同时,还要求数据传输达到良好的安全性、稳定性、可靠性。另一方面,对于实时性要求比较高的,例如金融股票、数据可视化等方面需要获得快速的响应,而对于传入数据仓库保存的可以有一定延迟。
基于最基本的用户需求,大数据传输机制应当遵循以下原则:
(1)模型安全性。大数据计算一般是由几十个甚至上百个节点组成的,在获取数据的时候,节点与数据源之间,节点与节点之间,都会有占有较大的I/O使用率,数据传输之间必须满足必要的安全性。对于保密要求较高的数据,更要建立全面的数据保护措施,以防数据泄露。
(2)传输可靠性。随着计算存储设备和数据传输通道的不断升级,数据的传输速度和效率逐渐提高。在获取数据源的时候,数据管道必须提供一个可靠的传输,以达到至少交付一次的保证。
(3)网络自适应性。用户和分析设备可以根据自身的需求,适应数据传输的服务,最大化对接数据格式,达到良好的对接效果。
2、主流传输方法
目前在大数据的广泛应用中,Kafka、Logstash、Sqoop等都是传输数据的重要途径,这里简要介绍传输原理。
2.1Kafka
Kafka最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统,常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年将该系统贡献给了Apache基金会并成为顶级开源项目。
Kafka主要设计特点如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个part内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
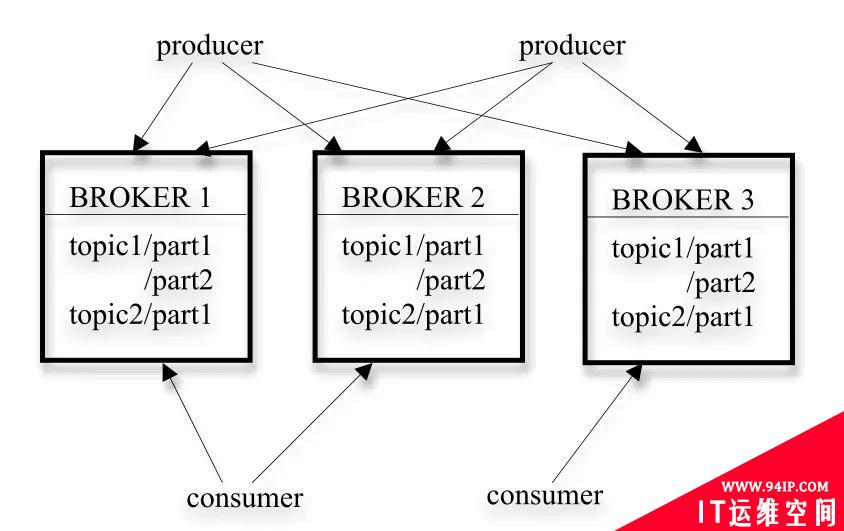
图1 kafka的架构
图1展示了一个典型的kafka集群的架构,每个集群中都包含若干个生产者(producer),这些生产者可以是来自数据采集设备的硬件数据源,亦可以是服务器产生的日志信息等等;每个集群中都有若干的服务代理(broker),每个服务代理一般安装在一个节点服务器上,kafka支持平行扩展,集群中服务代理的数量越多,吞吐量也会越高。生产者生产的数据可以向一个指定的topic中写入,消费者可以根据自己的需求,向指定的topic中拉取数据。
为了进一步提高数据传输的吞吐率,kafka将每个topic分为若干个part,每个part下面都会存储对应的数据和索引文件。当创建topic时,可以指定part的数量,part数量越多,系统的吞吐量就会越大,但是也会占用更多的资源。kafka收到生产者发送的数据后,就跟根据一定的均衡策略,将数据存放到某一个part下,等待消费者来消费数据。
除此之外,kafka还为数据建立了副本,当数据节点发生意外时,其他的副本通过一定的机制担起主part的作用,从而使系统具有高可用性。kafka提供了至少一次的交付保证,生产者发送数据到节点,节点会反馈该消息是否存储,若未收到确认信息,生产者则会重复发送该信息;同样的,消费者消费数据发送收到的反馈,节点记录被消费的位置,下次消费则从该位置开始。这些机制都保证了至少一次的可靠交付。
在安全性方面,kafka使用了SSL或者SASL验证来自客户端(生产者和消费者)以及其他broker和工具到broker的链接身份,在传输的过程中也可以选择对数据进行加密,对客户端的读写授权,虽然可能会导致集群性能下降,但对于保密性较高的数据来说,是可以接受的。
2.2Logstash
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,与此同时这根管道还可以让你根据自己的需求在中间加上滤网转换过滤数据,然后将数据发送到用户指定的数据库中。
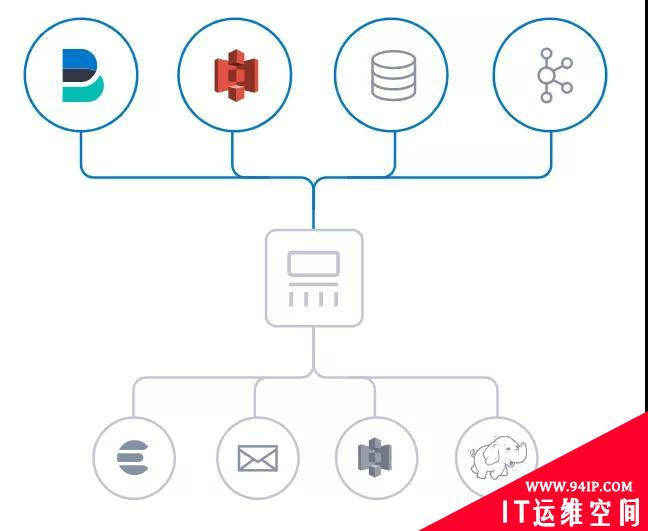
图2 Logstash数据传输
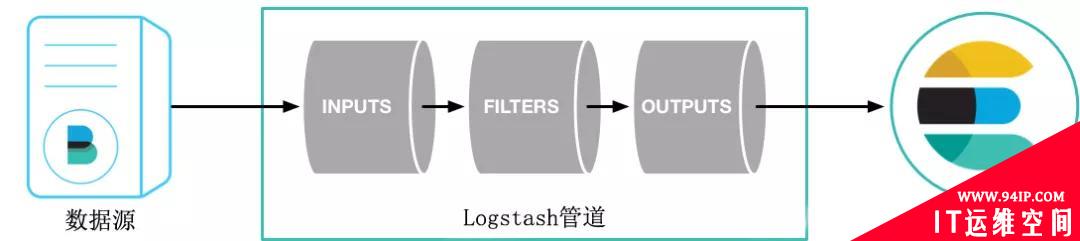
图3 Logstash 结构
Logstash将数据流中每一条数据称之为一个event,处理流水线有三个主要角色完成:inputs –> filters –> outputs,原始数据进入logstash后在内部流转并不是以原始数据的形式流转,在input处被转换为event,在output event处被转换为目标格式的数据。
当有一个输入数据时,input会从文件中取出数据,然后通过json codec将数据转换成logstash event。这条event会通过queue流入某一条pipline处理线程中,首先会存放在batcher中。当batcher达到处理数据的条件(如一定时间或event一定规模)后,batcher会把数据发送到filter中,filter对event数据进行处理后转到output,output就把数据输出到指定的输出位置。输出后还会返回ACK给queue,包含已经处理的event,queue会将已处理的event进行标记。
假如 Logstash 节点发生故障,Logstash 会通过持久化队列来保证至少将运行中的事件送达一次。那些未被正常处理的消息会被送往死信队列 (dead letter queue) 以便做进一步处理。由于具备了这种吸收吞吐量的能力,无需采用额外的队列层,Logstash 就能平稳度过高峰期。此外,还能充分确保采集管道的安全性。
3、多源异构数据传输设计
在数据不断壮大的过程中,我们往往会根据自身的需求,收集不同类型的数据,存储在不同的数据库中,使用数据时也会从不同的数据源读取数据进行分析和处理。这些不同的存储方式、不同的采集的系统、不同的数据格式,从简单的文件数据库到复杂的网络数据库,共同构成了异构数据源。为了将数据统一处理,根据可视化等现实需求,就需要将各个异构数据源通过一个引擎衔接起来,为数据的大批量处理和展示提供更为标准化的读取方式。
目前,以异构数据批处理为目标的应用有springbatch、kettle、datax等,他们各自有各自的特点:
Springbatch是spring提供的一个轻量级、全面的批处理数据处理框架,无需用户交互即可最有效地处理大量信息的自动化,复杂处理,并且提供了可重用的功能,这些功能对于处理大量的数据至关重要。
Kettle是一款国外开源的ETL工具,他可以通过Spoon来允许你运行或者转换任务,支持从不同的数据源读取、操作和写入数据,在规定的时间间隔内用批处理的模式自动运行。
Datax一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
下面介绍一种轻量级的ETL工具,主要作用就是从不同源获取数据,然后做统一的处理,最后再写入各种目标源。它基本特性是:
基于Springboot开发,轻量级别、快速、简单,入门门槛低
扩展性强,各个模块均是独立的,可以以插件的形式进行开发
可以通过UI界面来构建任务并操作,总体监控平台的数据实时情况
基于Disruptor做缓冲,同时使用redis等内存缓存,保证高速处理任务
该ETL工具将整个系统分为如下模块:Input、Reader、Transport、Convert、Writer和Output,在系统上层已经定义好各个模块的接口,开发者根据自己的需要个性化定义自己的模块,只需继承上层接口即可实现模块的嵌入。系统运行的简化基本流程如图4所示。
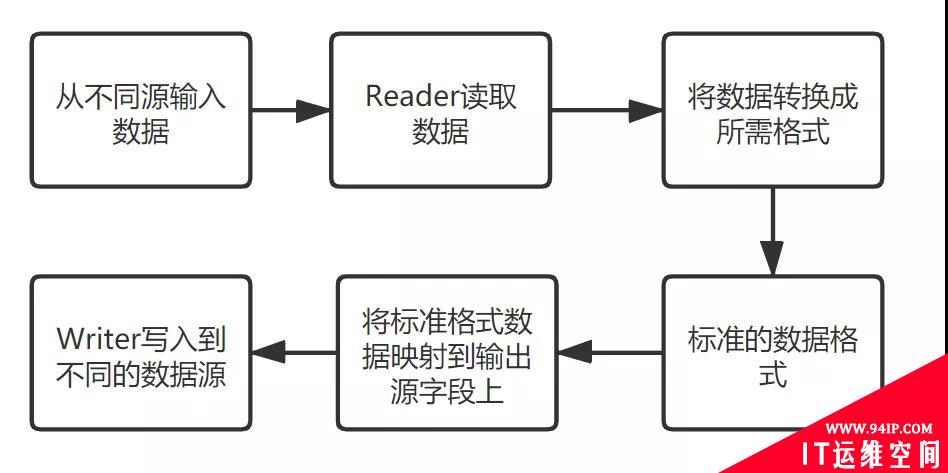
图4 ETL工具运行简化流程
这里所有的模块都有一定的标准来接入系统,然后使用各数据源提供的API来读写数据,例如输入可以从文件读取、mysql、hbase、hdfs、kafka、http等,输出同样支持这些数据源,最终解决异构数据源相互传输数据不兼容的问题。
系统在应对缓冲和读写速度上均设置可选的策略,可以基于java的调度器,综合当前输入输出的任务数量,来调整输入输出线程池以及线程的数量,以使数据的传输达到最大的性能。
4、总 结
现在数据采集的设备无处不在,在各种格式的数据汇入不同数据仓库、数据仓库之间互相接入数据都需要一个高效、可靠、安全的数据通道,本文介绍了大数据传输的一些背景知识,同时简要描述了当前主流数据传输工具的应用和个性化异构数据引擎的设计问题。本文参考了一些文献和网络资源,对他们的观点和技术对本文的贡献表示感谢。
参考文献[1] https://www.cnblogs.com/qingyunzong/p/9004509.html
[2] https://blog.csdn.net/chenleiking/article/details/73563930[3]https://gitee.com/starblues/rope/wikis/pages?sort_id=1863419&doc_id=507971
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-
Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-
MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)















发表评论