


早在2018年,Chrome就默认启用了站点隔离功能,以缓解UXSS和Spectre等漏洞带来的影响。当时,我积极参加了Chrome漏洞奖励计划,并在站点隔离机制中发现了10多个漏洞,从而获得了3.2万美元的奖励。
在本系列文章中,我们不仅会为读者解释站点隔离和相关安全功能的运行机制,同时,还会介绍在该安全机制发现的安全漏洞,当然,目前这些漏洞已经得到了修复。
挖洞方法
当我在Chrome中挖掘安全漏洞的时候,通常会从手动测试开始下手,而不是先进行代码审查,因为Chrome团队更擅长代码审查。所以我认为,但凡从他们的代码审查中漏网逻辑漏洞,通常都很难通过代码审计找到。因此,当我开始研究站点隔离时,我遵循了相同的方法。
什么是站点隔离?
站点隔离是一种安全功能,它将每个站点的网页隔离到单独的进程中。通过站点隔离机制,站点的隔离与操作系统级别的进程隔离保持一致,而不是通过同源策略等在进程内实现逻辑隔离。
在这里,Site定义为Scheme和eTLD+1(也称为Schemeful same-site)。
https://www.microsoft.com:443/
因此,Site的定义比Origin更宽泛,Origin是通过Scheme、Host和Port来进行定义的。
https://www.microsoft.com:443/
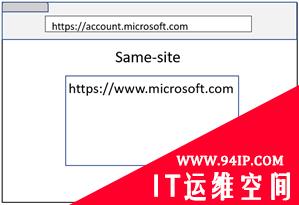
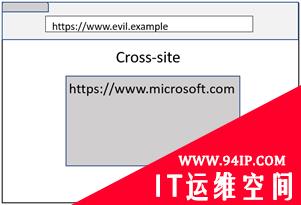
然而,并不是所有的情况都符合上述Site的定义。因此,我开始测试下面的边缘情况,看看站点隔离在每种情况下的表现如何。
不含域名的URL
实际上,URL并不需要包含域名(例如IP地址)。在这种情况下,站点隔离就变回了同源比较,以实现进程隔离。
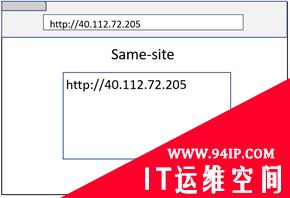
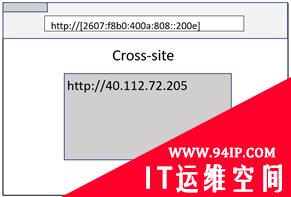
File URL
本地文件可以通过文件scheme呈现到浏览器选项卡中。目前,站点隔离将使用文件scheme的所有URL都视为源自同一站点。


Data URL
虽然加载在顶部frame上的Data URL始终与它自己的进程保持隔离,但加载在iframe内的Data URL将从导航发起方那里继承Site(尽管源仍然是opaque origin)。年龄较大的读者可能会记得类似的概念,iFrame中的Data URL使用的是继承自Firefox的源。
正如您在上面的图像中所看到的,即使两个示例都导致Microsoft.com嵌入数据URL iframe,但是跨站点的情况仍然是保持进程隔离的,因为导航发起方是evil.example。


Data URL站点继承中的漏洞
如果从本地缓存还原浏览器或选项卡,那么会发生什么情况?这时,站点隔离机制还会记得Data URL的导航发起方吗?
事实证明,还原浏览器或选项卡后,站点隔离无法记住导航启动方。从本地缓存还原选项卡时,站点隔离通常会盲目地将Data URL放在父frame的同一站点内。攻击者可以触发浏览器崩溃,然后还原浏览器,从而绕过站点隔离机制。

从本地缓存还原页面时,可以通过将Data URL隔离到另一个进程中来解决这个问题。
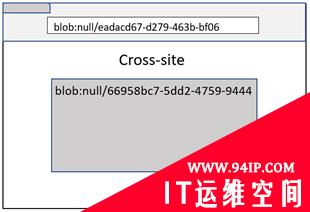
具有不透明源的Blob URL
从不透明的源(opaque origin)创建Blob URL(例如Data URL、沙箱iframe或File URL)时,Blob URL将采用“blob:null/[GUID]”这样的形式。
由于这是一个没有域名的URL,因此,站点隔离机制将退化为同源比较。但是,这是一个漏洞,因为攻击者可以通过其他站点创建具有不透明源的Blob URL。而且同源比较还远远不够,因为源始终是“blob:null”。因此,该URL需要同时对源和路径进行比较,以进行进程隔离。

测试进程隔离逻辑
借助于Chromium任务管理器(Windows中可以通过Shift + Esc组合键调出它)和FramesExplorer等工具,我们在站点隔离机制的进程隔离逻辑中发现了一些问题,这有助于识别哪些frame共享了同一个进程(此外,您还可以使用chrome://process-internals/#web-contents来完成同一任务)。
站点隔离如何缓解UXSS攻击?
从历史上看,大多数UXSS攻击都是通过绕过在渲染器进程中实现的同源策略检查来实现的。换句话说,一旦您可以绕过同源策略检查,所有跨站点数据就都可以在渲染器进程中使用。因此,JS代码能够获取窗口、文档或任何其他跨域对象引用。
站点隔离通过隔离进程从根本上改变了这一点。也就是说,即使您可以绕过同源策略检查,其他站点的数据也无法在同一进程中使用。
此外,将跨域窗口导航到JavaScript URL的UXSS手段也不是问题。我们知道,JavaScript URL导航要想成功,2个网页必须是同源的。因此,对JavaScript URL的导航可以在渲染器进程内处理(渲染器应该承载任何具有窗口引用的同源网页),这样,任何上传到浏览器进程的JavaScript URL导航请求都可以安全地被忽略。当然,如果您忘记了在浏览器进程中忽略JavaScript URL,那就是一个bug了。
只有进程隔离还远远不够
站点隔离有助于缓解UXSS,但是进程隔离还不足以防止所有跨站点数据泄漏。
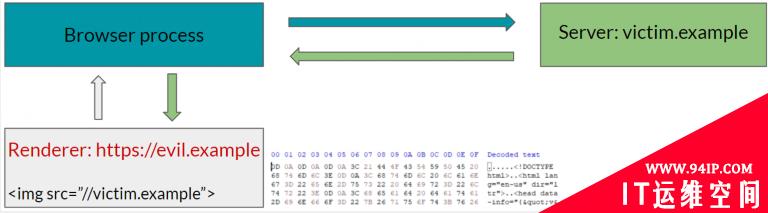
最简单的例子就是Spectre攻击。借助Spectre攻击,攻击者可以读取进程的整个地址空间。尽管进程隔离有助于隔离网页,但子资源(例如图像、音频、视频等)不是进程隔离的。
因此,在没有其他缓解措施的情况下,攻击者可以通过使用img标签嵌入该页面来读取任意跨站点页面。
跨源读取阻止
跨源读取阻止(Cross-Origin Read Blocking,CORB)通过检查跨源子资源中响应的MIME类型来减轻暴露敏感的跨域数据的风险。如果跨源子资源的MIME类型在拒绝列表中(例如HTML、XML、JSON等),则默认情况下不会将响应发送到渲染器进程,因此,使用Spectre攻击将无法读取该响应 。

绕过CORB
目前,已经有多种方法可以绕过CORB。
· CORB bypass in Workers by @_tsuro
· CORB bypass in WebSocket by @piochu
· CORB bypass in AppCache
从根本上说,如果使用URLLoader在禁用CORB的情况下获取了URL,并且响应被泄露给了跨站点的Web渲染器进程,那么就可以绕过CORB。
例如,我们能够使用AppCache来绕过CORB,因为用于下载缓存资源的URLLoader禁用了CORB。据我所知,AppCache曾经允许缓存跨源的HTML文件,所以,我想这可能会导致CORB被绕过,而且事实也确实如此。
同样需要注意的是,一些渲染器进程可以通过某些设计(例如扩展渲染器进程)来绕过CORB。
跨源资源策略
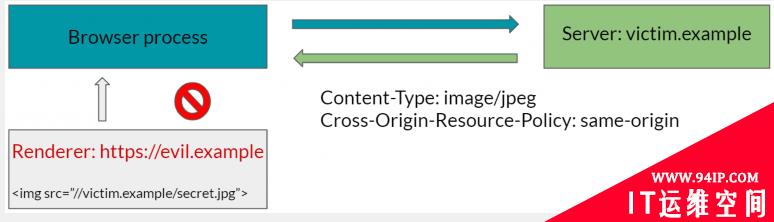
虽然CORB默认情况下可以保护很多敏感资源,但有些资源(如图片)可以嵌入Web上的多个站点中。因此,CORB默认情况下不能保护此类资源进入跨源页面。
跨源资源策略(CORP)允许开发人员规定某些资源是否可以嵌入到同源、同站点或跨源页面。浏览器可以利用这些规定来保护那些默认情况下无法受到CORB保护的资源。
通过CORP,网站可以保护敏感资源免受各种攻击,如Spectre攻击、XSSI、特定于子资源的SOP绕过等。换句话说,缺少CORP头部的敏感资源可以使用Spectre攻击来读取(除非资源受到CORB的保护)。
如何测试CORB
如果您想试验绕过CORB加载子资源(例如,通过上面的AppCache绕过CORB)的想法,请尝试使用以下响应头部来加载该子资源:
Content-Type:text/html X-Content-Type-Options:nosniff
正常情况下,CORB应该阻止此类跨域子资源,因此,如果正确加载了子资源,则表明存在CORB绕过漏洞。
如果您想知道在哪些地方不能加载子资源(例如,通过上面的WebSocket绕过CORB),请使用windbgs!address命令,通过在堆中搜索目标字符串,以确认它们是否已经进入渲染器进程。
!address/f:Heap/c:"s-a%1%2\"secret\""
这将在渲染器进程的堆内存中搜索字符串secret。如果要查找unicode字符串而非ascii字符串,则可以将-a更改为-u。
小结
借助站点隔离、CORB和CORP保护机制,不仅可以缓解从UXSS到Spectre等诸多攻击,同时,还能缓解允许攻击者读取跨站点信息的其他客户端漏洞带来的危害。但是,有些攻击可能会危及渲染器进程。在下一篇文章中,我们将集中讨论如何进一步加强站点隔离机制,以降低攻击者通过这种漏洞获取跨站点信息的风险。
本文翻
转载请注明:IT运维空间 » 安全防护 » 深度剖析站点隔离机制,Part 1
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-
Oracle PL/SQL如何动态调用存储过程 收藏
-
Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-
MySQL与Oracle之间互相拷贝数据的Java程序
-
MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-

Oracle:SQL语句–给用户赋权限
-

如何在MySql中记录SQL日志(例如Sql Server Profiler)








发表评论