


引 言
对抗攻击(也称为对抗样本生成)是近几年人工智能领域新兴的研究方向,最初是针对图像所提出,在计算机视觉领域取得了丰硕的研究成果,提出了很多实用的攻击算法。最近,研究人员在不断寻找新的应用场景,积极探索对抗攻击在其他领域的应用,针对文本的对抗攻击已取得一些进展。
基本概念
对抗样本的概念最初是在2014年提出的,指的是一类人为构造的样本,通过对原始的样本数据添加针对性的微小扰动所得到,其不会影响人类的感知,但会使深度学习模型产生错误的判断[1]。对抗攻击即指构造对抗样本的过程。
图1展示了文本领域内实现对抗攻击的一个例子。语句(1)为原始样本,语句(2)为经过几个字符变换后得到的对抗样本。深度学习模型能正确地将原始样本判为正面评论,而将对抗样本误判为负面评论。而显然,这种微小扰动并不会影响人类的判断。
关于对抗样本存在的原因,有学者认为是由于模型的高度非线性和过拟合,有学者认为是由于特征维度过高和模型的线性性质,至今还未达成共识,研究人员一般都会根据自己的研究成果来进行解释,每个人提出的观点往往仅适用于局部现象。但不管是线性解释还是非线性解释,究其本质是由于模型没有学到完美的判别规则,模型的判断边界与真实的决策边界不一致。深度学习模型由于能够自动学习特征的能力而得到广泛应用,但是这种由数据出发进行自主学习,所得到的特征并不一定就是我们所希望的特征,模型对数据的理解与人的理解有着很大的差异。因而模型学习到的特征,极有可能并非是人理解事物的特征,即对抗样本的存在是深度学习模型的固有缺陷。

图1 文本领域的对抗攻击举例
文本数据VS图像数据
文本数据与图像数据的不同,为文本领域的对抗攻击研究带来了巨大挑战。[2]
1. 离散VS连续(Discrete VS Continucous)
图像数据是连续的,易编码为数值向量,预处理操作线性、可微,通常使用lp范数来度量原始样本与对抗样本间的距离;而文本数据是符号化的数据,是离散的,预处理操作非线性、不可微,很难定义文本上的扰动及度量文本序列改变前后的差异。
2. 易感知VS不易感知(Preceivable VS Unperceivable)
人类通常不容易察觉到图像像素的微小变化,因此图像的对抗样本不会改变人类的判断力,只会影响深度学习模型的判别结果;而文本上的变化则很容易影响文本可读性,在将文本数据输入DNN模型之前通过拼写检查和语法检查来识别或纠正更改,极有可能导致攻击失败。
3. 富有语义VS无语义(Semanic VS Semanic-less)
像素的微小变化不会改变图像的语义,但对文本的扰动可轻易改变单词和句子的语义。例如,干扰单个像素不会将图像从猫变为另一种动物,而删除否定词将改变句子的情感。更改样本的语义有悖于对抗样本的定义,文本领域的对抗样本应在使深度学习模型发生误判的同时保持数据样本的真实标签不变。
针对以上挑战,有些学者首先将文本数据映射为连续数据,然后借鉴计算机视觉领域的一些对抗攻击算法生成对抗样本,有些学者针对文本数据的特性直接通过插入、删除、替换等文本编辑操作生成对抗样本。
算法分类
如图2所示,对抗攻击算法可以从不同的角度进行分类。
根据模型访问权限可以分为白盒攻击和黑盒攻击,白盒攻击需要获取模型的结构和参数等详细信息;而黑盒攻击不需要模型知识,只需访问模型获取输入的对应输出即可。
根据攻击目标设定可以分为有目标攻击和无目标攻击,无目标攻击旨在使模型的输出为偏离正确结果的任意错误预测;而有目标攻击旨在使模型的输出为某一特定结果。
根据添加扰动时所操作的文本粒度可以分为字符级、单词级和语句级攻击。字符级攻击通过插入、删除或替换字符,以及交换字符顺序实现;单词级攻击主要通过替换单词实现,基于近义词、形近词、错误拼写等建立候选词库;语句级攻击主要通过文本复述或插入句子实现。
根据攻击策略可以分为Image-to-Text(借鉴图像领域的经典算法)、基于优化的攻击、基于重要性的攻击以及基于神经网络的攻击。部分学者通过将文本数据映射到连续空间,然后借鉴图像领域的一些经典算法如FGSM、JSMA等,生成对抗样本;基于优化的攻击将对抗攻击表述为带约束的优化问题,利用现有的优化技术求解,如梯度优化、遗传算法优化;基于重要性的攻击通常首先利用梯度或文本特性设计评分函数锁定关键词,然后通过文本编辑添加扰动;基于神经网络的攻击训练神经网络模型自动学习对抗样本的特征,从而实现对抗样本的自动化生成。
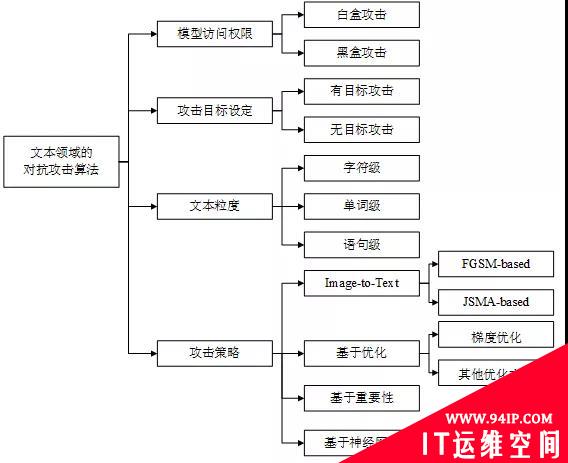
图2 文本领域的对抗攻击算法分类机制
代表性算法
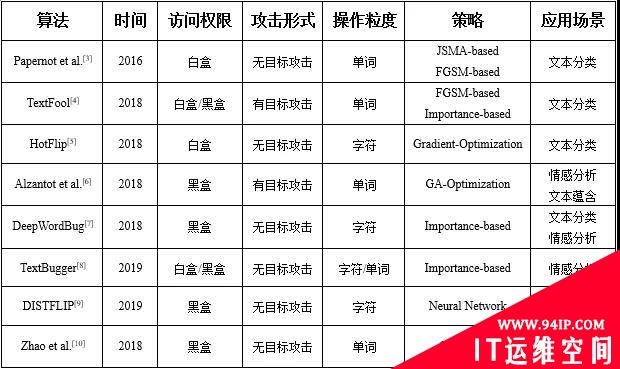
文本领域的常见任务有文本分类、情感分析、机器翻译、阅读理解、问答系统、对话生成、文本蕴含等,其中文本分类与情感分析任务使用分类器模型,其他任务使用seq2seq模型。针对分类任务的研究较多,下文介绍几种代表性算法,表1总结了其主要特点。
Papernot等人[3]最先研究了文本领域的对抗样本问题,提出了生成对抗性输入序列的概念。作者将图像对抗领域的JSMA算法迁移到文本领域,利用计算图展开技术来评估与单词序列的嵌入输入有关的前向导数,构建雅可比矩阵,并借鉴FGSM的思想计算对抗性扰动。由于词向量不能取任意实数值,作者建立了一个特定的词典来选择单词以替换原始序列中的随机词。
Liang等人[4]提出了TextFool方法,首先针对白盒模型和黑盒模型使用不同的策略识别出对分类具有重要贡献的文本项(HTP、HSP),然后对这些重要的文本项通过单一或混合使用插入、修改和删除三种扰动策略,生成对抗样本。对于白盒模型,作者借鉴FGSM的思想来估算文本项的重要度,但是通过损失函数的梯度大小而不是梯度符号来度量;对于黑盒模型,通过遮挡文本的策略来识别重要文本项。
Ebrahimi 等人[5]提出了HotFlip方法,基于one-hot表示的梯度来有效估计单个操作所造成的最大损失的变化,通过原子翻转操作(将一个字符替换为另一个字符)生成对抗样本,并通过一系列的字符翻转来支持插入和删除操作。考虑到梯度优化的局限性,Alzantot等人[6]提出使用最优化技术中的遗传算法(Genetic Algorithm, GA)来生成与原始样本具有相似语义和语法的对抗样本。
Gao等人[7]提出了DeepWordBug方法,将对抗样本的生成分为两个阶段。首先使用针对文本数据特性设计的评分函数来识别关键的Token,根据重要性进行排名;然后对排名最高的m个Token通过简单的字符级操作(交换、替换、删除和插入)进行扰动,改变分类结果。
Li等人[8]提出了TextBugger方法,首先针对白盒和黑盒模型通过不同策略识别影响模型分类结果的重要词,然后采取插入、删除、字符交换、字符替换、单词替换等五种扰动策略分别生成扰动从中选择一个最优扰动。在白盒场景下,通过计算分类器的雅可比矩阵来找到重要词;在黑盒场景下,首先根据分类置信度找到重要的句子,然后使用评分函数来找到重要单词。
Gil 等人[9]提出了HotFlip的派生方法DISTFLIP,该算法提取HotFlip优化过程中的知识训练神经网络模型来模拟攻击从而生成对抗样本,极大地节省了运行时间,并可以迁移到黑盒场景下进行攻击。
Zhao等人[10]设计的用于生成对抗样本的模型,首先使用一个逆变器将原始数据映射到向量空间,在数据对应的稠密向量空间中进行搜索添加扰动得到对抗样本;然后使用GAN作为生成器将向量空间中得到的对抗样本映射回原始数据类型。
表1 文本对抗领域的代表性算法
小 结
如今,深度神经网络(DNN)在计算机视觉、语音识别和自然语言处理等各类领域得到了广泛应用,涉及许多安全关键任务,对抗样本的存在给基于DNN模型部署的系统带来了潜在的安全威胁。例如攻击自动驾驶系统,可使其错误识别路标造成交通隐患;攻击恶意软件检测器,可使恶意软件逃过检测被识别为健康软件。
相较于图像领域,在文本领域生成对抗样本更具挑战性,在扰动离散数据的同时需要保留有效的句法、语法和语义。未来的研究可以考虑以下几点:
(1)提高不可感知性。许多研究工作是通过翻转字符或改变单词来实现对文本的扰动,这种扰动较为明显,错误拼写的单词和语法错误的句子很容易被人发现,也能被语法检查软件检测出来,因此这种扰动很难攻击实际的NLP系统。
(2)提高移植性。目前,文本对抗的研究主要集中在理论模型上,很少涉及到实际应用。对于现实世界中的NLP系统,模型访问受到限制,可移植性是实施攻击的关键因素。
(3)实现自动化。大多数研究工作在构造文本扰动时,需要依靠人工操作,效率较低。如通过将手动选择的无意义段落串联起来攻击阅读理解系统,人工挑选形近词等。
参考文献
[1]Szegedy C, Zaremba W, Sutskever I, et al. Intriguing Properties of Neural Networks[C] // Proceedings of the 2th International Conference on Learning Representations, 2014.
[2]Zhang W E, Sheng Q Z, Alhazmi A, et al. Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey[J]. ACM Transactions on Intelligent Systems and Technology (TIST). 2020, 11(3): 1-41.
[3]Papernot N, McDaniel P, Swami A, et al. Crafting Adversarial Input Sequences for Recurrent Neural Networks[C]// Proceedings of MILCOM 2016-2016 IEEE Military Communications Conference. IEEE, 2016: 49-54.
[4]Liang B, Li H, Su M, et al. Deep Text Classification Can be Fooled[C]// Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence(IJCAI). 2018: 4208-4215.
[5]Ebrahimi J, Rao A, Lowd D, et al. HotFlip: White-Box Adversarial Examples for Text Classification[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018: 31-36.
[6]Alzantot M, Sharma Y, Elgohary A, et al. Generating Natural Language Adversarial Examples[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2890-2896.
[7]Gao J, Lanchantin J, Soffa M L, et al. Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers[C]// Proceedings of 2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018: 50-56.
[8]Li J, Ji S, Du T, et al. TextBugger: Generating Adversarial Text Against Real-world Applications[C]// Proceedings of the 26th Annual Network and Distributed System Security Symposium. 2019.
[9]Gil Y, Chai Y, Gorodissky O, et al. White-to-Black: Efficient Distillation of Black-Box Adversarial Attacks[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 1373-1379.
[10]Zhao Z, Dua D, Singh S. Generating Natural Adversarial Examples[C]// Proceedings of the International Conference on Learning Representations. 2018.

转载请注明:IT运维空间 » 安全防护 » 文本领域的对抗攻击研究综述
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-
MySQL与Oracle之间互相拷贝数据的Java程序
-
MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-

mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-

如何在MySql中记录SQL日志(例如Sql Server Profiler)










发表评论