


引言
人工智能技术已融入到各行各业,从自动驾驶、人脸识别再到智能语音助手,人工智能就在身边。人工智能带来方便的同时,也引发了一定的安全问题。一方面攻击者利用低门槛的人工智能技术实施非法行为,造成安全问题;另一方面,由于人工智能,特别是深度神经网络本身的技术不成熟性,使应用人工智能技术的系统很容易受到黑客攻击。
深度神经网络的技术不成熟性主要在于模型的不可解释性,从模型的训练到测试阶段都存在安全问题。训练阶段主要是数据投毒问题,通过在训练数据中添加一些恶意的样本来误导模型的训练结果。测试阶段的安全问题主要是对抗样本,在原始样本中添加人眼不可察觉的微小扰动就能够成功骗过分类器造成错误分类。
对抗样本
自2013年起,深度学习模型在某些应用上已经达到甚至超过了人类水平。特别是人脸识别、手写数字识别等任务上。随着神经网络模型的广泛使用,其不可解释特性被逐步扩大,出现了对抗样本。类似于人类的「幻觉」,一张人眼看似旋转的风车实质上是一张静止的图像(图1a),一张马和青蛙的图片(图1b)。既然「幻觉」可以骗过人的大脑,同样地,对抗样本也能骗过神经网络。
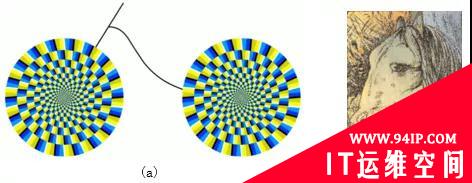
图1 视觉幻觉图
2014年,Szegedy等人[1]发现神经网络存在一些反直觉的特性,即对一张图像添加不可察觉的微小扰动后,就能使分类器误分类(图2),并将这种添加扰动的样本定义为对抗样本。理论上来说,使用深度神经网络的模型,都存在对抗样本。从此AI对抗开始成为了人工智能的一个热点研究。

图2 对抗样本实例
应用场景
自对抗样本被提出后,神经网络的安全性问题受到研究人员的格外重视。深度神经网络已经在各个领域取得了令人瞩目的成果,如果因神经网络本身的安全性给应用和系统带来安全威胁,将造成巨大的损失。例如,在自动驾驶领域,车载模型被攻击后将停车路标误识别为限速标志,可能造成人身安全;垃圾邮件检测模型被攻击后,垃圾邮件或者恶意邮件将不会被拦截。目前对抗样本的研究已经存在于图像、文本、音频、推荐系统等领域。
1.计算机视觉
(1)图像分类/识别
Szegedy首次发现深度神经网络存在对抗样本是在图像分类的背景下,对原始图片添加微小的像素扰动,就能导致图像分类器误分类,且该微小扰动对人眼是不可察觉的。目前对抗攻击在图像分类领域已较为成熟,不仅提出了针对单一图像的攻击算法,还提出针对任意图像的通用扰动方法,并且针对攻击的防御方法也大量涌现。
L-BFGS:2013年,Szegedy等人[1]提出了L-BFGS简单有界约束算法,寻找一个与原始样本扰动距离最小又能够使分类器误分类的对抗样本。
FGSM(Fast Gradient Sign Method)[2]:该算法是由Goodfellow等人提出的,一种经典的对抗样本生成方法,在预知模型本身参数的前提下,在原始图片的梯度下降方向添加扰动以生成对抗样本。
JSMA(Jacobian-based saliency map attack)[3]:该算法是由Papernot等人提出的,建立在攻击者已知模型相关信息的前提下,根据分类器的结果反馈只修改输入图片中对输出影响最大的关键像素,以欺骗神经网络。
One Pixel Attack[4]:该方法于2017年被提出,只需要修改输入图像的一个像素点就能够成功欺骗深度神经网络,One Pixel攻击不仅简单,而且不需要访问模型的参数和梯度信息。
C&W算法[5]:是一种基于优化的攻击方法,生成的对抗样本和原始样本之间的距离最短,且攻击强度最大。算法在迭代过程中,将原始样本和对抗样本之间的可区分性相结合作为新的优化目标。
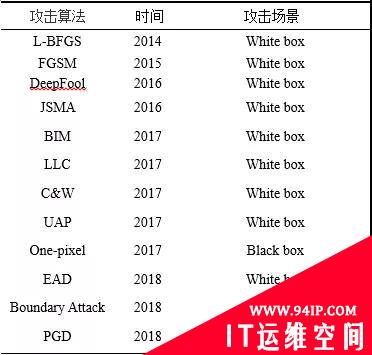
其他的攻击算法包括DeepFool、UAP、BIM、PGD等,如表1所示。
表1图像攻击算法
(2)人脸识别
人脸识别系统越来越广泛,其应用领域多数涉及隐私,因此人脸识别模型的安全性至关重要。2018年,Rozsa等人[6]探索了人脸识别中的深度学习模型在对抗样本中的稳定性,通过“Fast Flipping Attribute”方法生成的对抗样本攻击深度神经网络分类器,发现对抗攻击有效地改变了人脸图片中目标属性标签。如图3所示,添加微小扰动的“女性”图片被人脸识别模型判别为“男性”。
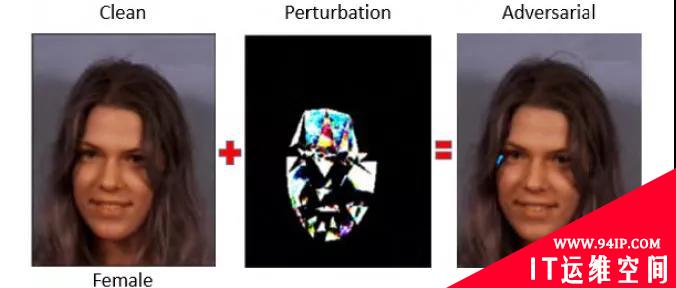
图3 人脸识别对抗样本实例
(3)图像语义分割
图像语义分割是建立在图像目标分类的基础上,对目标区域或者像素进行分类。语义分割的对抗攻击考虑是否能够在一组像素的基础上优化损失函数,从而生成对抗样本。Xie等人[11]基于每个目标都需要经历一个单独的分类过程而提出了一种密度对抗生成网络DAG,是一种经典的语义分割和目标检测的攻击方法。该方法同时考虑所有目标并优化整体损失函数,只需要为每个目标指定一个对抗性标签,并迭代执行梯度反向传播获取累积扰动。
(4)目标检测
目标检测作为计算机视觉的核心任务也受到了对抗攻击[7]-[10]。目前,目标检测模型主要分为两类:基于提议的和基于回归的模型,这种机制使目标检测的对抗攻击相比于图像分类更复杂。文献[7]提出了一种针对两种模型可迁移且高效的目标检测的对抗样本生成方法UEA(图4),该方法利用条件GAN来生成对抗样本,并在其上多加几个损失函数来监督生成器的生成效果。
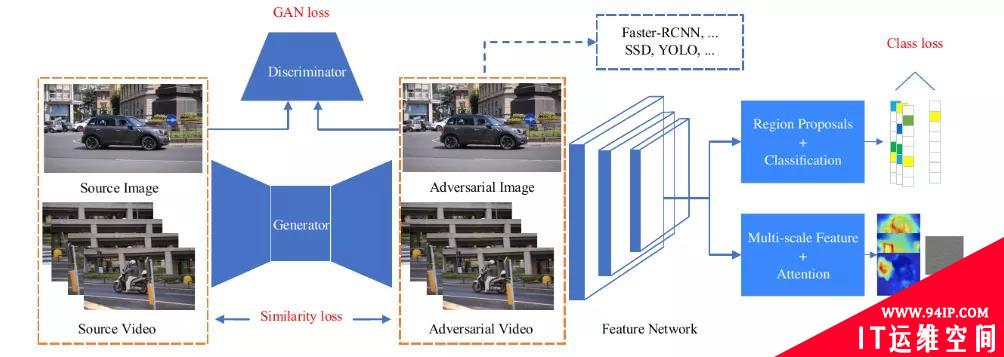
图4 UEA对抗攻击训练框架
(5)自动驾驶
自动驾驶汽车由多个子系统构成,包括负责场景识别、根据场景预测汽车运动以及控制发动机完成汽车驾驶的子系统。而目前,这三方面都逐渐使用深度学习模型搭建,给出较优决策结果的同时也引发了物理场景的对抗攻击问题。Evtimov等人[21]提出了一种物理场景的对抗攻击算法RF2,使各种路标识别器识别失败。在原始路标图像上添加涂鸦或黑白块, “STOP”路标就能识别成限速路标,右转路标误识别为“STOP”路标或添加车道路标。

图5 路标对抗样本
2.自然语言处理
自然语言处理是除计算机视觉外人工智能应用最为广泛的领域之一,因此人工智能本身的脆弱性也将导致自然语言处理任务出现安全隐患。但又不同于计算机视觉中对图像的攻击方式,自然语言处理领域操作的是文本序列数据,主要难点在于:①图像是连续数据,通过扰动一些像素仍然能够维持图片的完整性,而文本数据是离散的,任意添加字符或单词将导致句子缺失语义信息;②图像像素的微小扰动对人眼是不可察觉的,而文本的细微变化很容易引起察觉。目前,自然语言处理在情感分类、垃圾邮件分类、机器翻译等领域都发现了对抗样本的攻击[12]-[15],攻击方法除了改进计算机视觉中的攻击算法,还有一部分针对文本领域新提出的攻击算法。
(1)文本分类
在情感分析任务中,分类模型根据每条影评中的词判别语句是积极或消极。但若在消极语句中扰动某些词将会使情感分类模型误分类为积极情感。Papernot等人[13]将计算机视觉领域的JSMA算法迁移到文本领域,利用计算图展开技术来评估与单词序列的嵌入输入有关的前向导数,构建雅可比矩阵,并借鉴FGSM的思想计算对抗扰动。
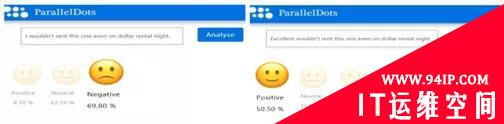
图6 情感分析任务中的对抗样本
在垃圾邮件分类任务中,如果模型受到对抗样本的攻击,垃圾邮件发布者就可以绕过模型的拦截。文献[16]提出了一种基于GAN式的对抗样本生成方法,为了解决GAN不能直接应用到离散的文本数据上的问题,提出采用增强学习任务(REINFORCE)奖励能够同时满足使目标判别器误分类和具有相似语义的对抗样本。
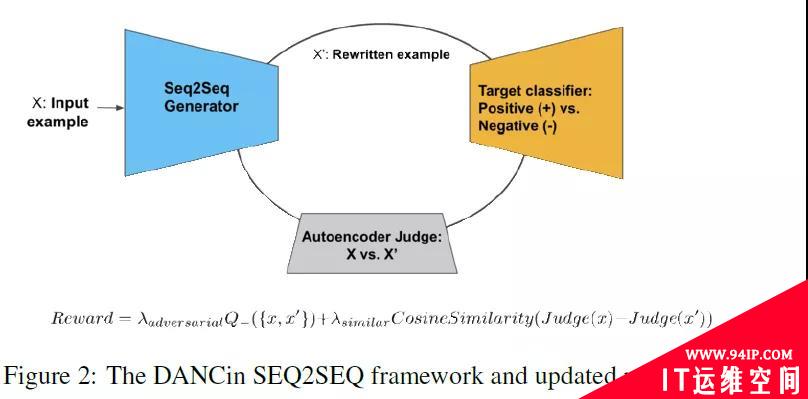
图7 基于增强学习的GAN
(2)机器翻译/文本摘要
不同于文本分类任务输出空间是有限的类别结果,机器翻译任务的输出空间是无限的。Cheng等人[15]提出了一种针对seq2seq模型的对抗样本生成方法,对于离散输入空间带来的问题,提出使用一种结合group lasso和梯度正则化的投影梯度法,针对输出空间是序列数据的问题,设计了新颖的损失函数来实现无重叠和目标关键词攻击。
3.网络安全
网络安全领域已广泛使用深度学习模型自动检测威胁情报,如果将对抗攻击转移到对安全更加敏感的应用,如恶意软件探测方面,这可能在样本生成上提出重大的挑战。同时,失败可能给网络遗留严重漏洞。目前,对抗攻击在恶意软件检测、入侵检测等方向已展开对抗研究[16]-[18]。
(1)恶意软件检测
相较于之前的计算机视觉问题,恶意软件应用场景有如下限制:①输入不是连续可微的,而是离散的,且通常是二分数据;②不受约束的视觉不变性需要用同等的函数替代。Grosse等人[16]验证了对抗攻击在恶意软件识别领域的可行性,将恶意软件用二进制特征向量表示,并借鉴Papernot等人[13]采用的JSMA算法实施攻击,实验证明了对抗攻击在恶意软件探测领域确实存在。
(2)恶意域名检测
恶意域名中的DGA家族因频繁变换和善伪装等特点,使机器学习模型在识别阶段鲁棒性不高。Hyrum等人[17]提出了一种基于GAN的恶意域名样本生成方法DeepDGA,利用生成的恶意域名进行对抗性训练来增强机器模型来提高DGA域名家族的识别准确度,结果表明,由GAN生成的恶意域名能够成功地躲避随机森林分类器的识别,并且加入对抗样本训练后的随机森林对DGA家族的识别准确度明显高于对抗训练的结果。

图8 DeepDGA生成的恶意域名
(3)DDoS攻击
在DDoS攻击领域,Peng等人[18]提出了改进的边界攻击方法生成DDoS攻击的对抗样本,通过迭代地修改输入样本来逼近目标模型的决策边界。
4.语音识别
目前,语音识别技术的落地场景较多,如智能音箱、智能语音助手等。虽然语音识别技术发展良好,但因深度学习模型本身的脆弱性,语音识别系统也不可避免地受到对抗样本的攻击。2018年,伯克利人工智能研究员Carlini 和Wagner发明了一种针对语音识别的新型攻击方法,该方法也是首次针对语音识别系统的攻击,通过生成原始音频的基线失真噪音来构造对抗音频样本,能够欺骗语音识别系统使它产生任何攻击者想要的输出[19]。
5.推荐系统
在推荐系统领域,如果推荐模型被攻击,下一个推荐的item将是人为设定的广告。基于协同过滤(CF)的潜在因素模型,由于其良好的性能和推荐因素,在现代推荐系统中得到了广泛的应用。但事实表明,这些方法易受到对抗攻击的影响,从而导致不可预测的危害推荐结果。目前,推荐系统常用的攻击方法是基于计算机视觉的攻击算法FGSM、C&W、GAN等[20]。目前该领域的对抗攻击仍存在挑战:①由于推荐系统的预测是依赖一组实例而非单个实例,导致对抗攻击可能出现瀑布效应,对某个单一用户的攻击可能影响到相邻用户;②相比于图像的连续数据,推荐系统的原始数据是离散的用户/项目ID和等级,直接扰动离散的实体将导致输入数据的语义信息发生改变。并且如何保持推荐系统对抗样本的视觉不可见性依然有待解决。
小 结
目前该领域的研究方向和攻击算法众多,一种攻击算法被提出后就会出现一种应对的防御方法,接着针对该防御方法再提出新的攻击方法,但在类似的攻防循环中还缺乏评判攻击是否有效的评估方法,此外有一些领域存在对抗攻击的情况但目前仍未被研究和发现。
参考文献…
[1] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
[2] I. Goodfellow, J. Shlens, C. Szegedy. Explaining and Harnessing Adversarial Examples[C]. ICLR, 2015.
[3] N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, A. Swami. The Limitations of Deep Learning in Adversarial Settings[C]// Proceedings of IEEE European Symposium on Security and Privacy. IEEE, 2016.
[4] J. Su, D. V. Vargas, S. Kouichi. One pixel attack for fooling deep neural networks[J]. IEEE Transactions on Evolutionary Computation, 2017.
[5] N. Carlini, D. Wagner. Towards Evaluating the Robustness of Neural Networks [C]// Proceedings of IEEE Symposium on Security and Privacy (SP). IEEE, 2017: 39-57.
[6] Rozsa A, Günther M, Rudd E M, et al. Facial attributes: Accuracy and adversarial robustness[J]. Pattern Recognition Letters, 2019, 124: 100-108.
[7] Wei X, Liang S, Chen N, et al. Transferable adversarial attacks for image and video object detection[J]. arXiv preprint arXiv:1811.12641, 2018.
[8] Cihang Xie, Jianyu Wang, Zhishuai Zhang, Yuyin Zhou, Lingxi Xie, and Alan Yuille. Adversarial examples for semantic segmentation and object detection.
[9] Shang-Tse Chen, Cory Cornelius, Jason Martin, and Duen Horng Chau. Robust physical adversarial attack on faster r-cnn object detector. arXiv preprint arXiv:1804.05810, 2018.
[10] Yuezun Li, Daniel Tian, Xiao Bian, Siwei Lyu, et al. Robust adversarial perturbation on deep proposal-based models. arXiv preprint arXiv:1809.05962, 2018.
[11] Xie C, Wang J, Zhang Z, et al. Adversarial examples for semantic segmentation and object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1369-1378.
[12] J. Li, S. Ji, T. Du, B. Li, and T. Wang, “Textbugger: Generating adversarial text against real-world applications,” in the Network and Distributed System Security Symposium, 2019.
[13] Nicolas Papernot, Patrick McDaniel, Ananthram Swami, and Richard Harang. 2016. Crafting Adversarial Input Sequences for Recurrent Neural Networks. In Military Communications Conference(MILCOM). IEEE, 2016: 49–54
[14] Wong C. Dancin seq2seq: Fooling text classifiers with adversarial text example generation[J]. arXiv preprint arXiv:1712.05419, 2017.
[15] Cheng M, Yi J, Chen P Y, et al. Seq2Sick: Evaluating the Robustness of Sequence-to-Sequence Models with Adversarial Examples[C]//AAAI. 2020: 3601-3608.
[16] Grosse K, Papernot N, Manoharan P, et al. Adversarial perturbations against deep neural networks for malware classification[J]. arXiv preprint arXiv:1606.04435, 2016.
[17] Anderson H S, Woodbridge J, Filar B. DeepDGA: Adversarially-tuned domain generation and detection[C]//Proceedings of the 2016 ACM Workshop on Artificial Intelligence and Security. 2016: 13-21.
[18] Peng X, Huang W, Shi Z. Adversarial Attack Against DoS Intrusion Detection: An Improved Boundary-Based Method[C]//2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019: 1288-1295.
[19] Carlini N, Wagner D. Audio adversarial examples: Targeted attacks on speech-to-text[C]//2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018: 1-7.
[20] Deldjoo Y, Di Noia T, Merra F A. Adversarial Machine Learning in Recommender Systems: State of the art and Challenges[J]. arXiv preprint arXiv:2005.10322, 2020.
[21] Eykholt K, Evtimov I, Fernandes E, et al. Robust physical-world attacks on deep learning visual classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1625-1634.

转载请注明:IT运维空间 » 安全防护 » 人工智能对抗的场景探究
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-
MySQL导入sql文件的三种方法小结
-
MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)












发表评论