

在Hadoop运算集群架构中,先分解任务,分工处理再汇总结果这些服务器依据用途可分成Master节点和Worker节点,Master负责分配任务,而Worker负责执行任务,如负责分派任务的操作,角色就像是Master节点。
Hadoop架构服务器角色分工
Hadoop运算集群中的服务器依用途分成Master节点和Worker节点。Master节点中安装了JobTracker、NameNode、TaskTracker和DataNode程序,但Worker节点只安装TaskTracker和DataNode。
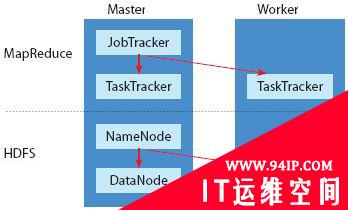
另外在系统的运行架构上,最简单的Hadoop架构,可以分成上层的MapReduce运算层以及下层的HDFS数据层。
在Master节点的服务器中会执行两套程序,一个是负责安排MapReduce运算层任务的JobTracker,以及负责管理HDFS数据层的NameNode程序。而在Worker节点的服务器中也有两套程序,接受JobTracker指挥,负责执行运算层任务的是TaskTracker程序,而与NameNode对应的则是DataNode程序,负责执行数据读写动作,以及执行NameNode的副本策略。
在MapReduce运算层上,担任Master节点的服务器负责分配运算任务, Master节点上的JobTracker程序会将 Map和Reduce程序的执行工作,指派给Worker服务器上的TaskTracker程序,由TaskTracker负责执行Map和Reduce工作,并将运算结果回复给Master节点上的JobTracker。
在HDFS数据层上,NameNode负责管理和维护HDFS的名称空间、并且控制文件的任何读写操作,同时NameNode会将要处理的数据切割成一个个文件区块(Block),每个区块是64MB,例如1GB的数据就会切割成16个文件区块。NameNode还会决定每一份文件区块要建立几个副本,一般来说,一个文件区块总共会复制成3份,并且会分散储存到3个不同Worker服务器的DataNode程序中管理,只要其中任何一份文件区块遗失或损坏,NameNode会自动寻找位于其他DataNode上的副本来回复,维持3份的副本策略。
在一套Hadoop集群中,分配MapReduce任务的JobTracker只有1个,而TaskTracker可以有很多个。同样地,负责管理HDFS文件系统的NameNode也只有一个,和JobTracker同样位于Master节点中,而DataNode可以有很多个。
不过,Master节点中除了有JobTracker和NameNode以外,也会有TaskTracker和DataNode程序,也就是说Master节点的服务器,也可以在本地端扮演Worker角色的工作。
在部署上,因为Hadoop采用Java开发,所以Master服务器除了安装操作系统如Linux之外,还要安装Java运行环境,然后再安装Master需要的程序,包括了NameNode、JobTracker和DataNode与TaskTracker。而在Worker服务器上,则只需安装Linux、Java环境、DataNode和TaskTracker。
转载请注明:IT运维空间 » 运维技术 » 分散处理 Hadoop架构服务器角色
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/10.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论