

就复制功能来说,从远不能胜任,到功能完备种种包含在内,PG虽然脚步略迟,但很快地走完了这些路径,的确当得起一个“功能***大的开源数据库”的称呼。
原本我准备的下一个话题,是PostgreSQL的Redo的讨论,但就PG的实现看,对运维来说,redo的机制很少需要特别关注,所以就把redo话题下的复制主题,单独拉出来整理了一下,其中***部分,就是PG的复制这个特性的历史来由。
复制,曾经是PGer心中永远挥之不去的伤口,在PG 9.0之前的版本,如果想要做一个PG的数据库主从,只能人工(PG内置了归档文件的shell调度操作)不断地复制wal日志(并且只能复制到当前在写的wal的前一个WAL日志)到从库(姑且这么叫它),这个从库需要设置为恢复模式,不可对外提供服务。

从我个人的看法而言,PG在功能性上,的确是强于MySQL的。但是为什么在互联网业务早期不被看好并选用,主要原因之一,就是其无法进行读能力的扩展,而在互联网业务之外,对事务,数据安全讲究的人来说,PG对比Oracle,其差距也是肉眼可见的。
MySQL还是一个跑在文件的SQL执行器(其衍生出来的MyISAM真的最多只能说是一个带B树的文件访问器)的时候,就已经做出来复制这个关键特性,并用这个机制,终于等到InnoDB的引入,成为了一个“真正的数据库”。对于早年的互联网业务,MySQL这种快速扩容从库,扩展读能力的机制,对互联网业务这种先天读远多于写的形态,简直是天作之合。
而PG,在那个时代而言,的确是比较被动的,但终于随着时间推移,逐步实现了主从复制的种种特性。
9.0的异步redo复制实现
时间来到2010年(***波互联网大潮早已过去,第二波互联网大潮也将要过去,大创业时代即将来临),PG发布了版本9.0,其中最重要的特性之一,就是流复制机制的实现,解决了两个问题:一个是通过网络连接,从库直接去拉redo日志(redo复制,这个也是MySQLer心中痛点啊),而非从主库走操作系统命令复制过来,避免了对这个复制机制本身维护的复杂性;第二个,就是改造出来Hot Standby机制,也就是在从库应用redo的同时,也允许从库提供只读的select服务。
这里实现的复制,当然还只是异步复制,而且机制我认为很怪异:首先,把从主库走操作系统命令复制wal日志(不包含***的正在被写入的wal文件)全部执行recovery之后,再发起一个网络连接到主库读***的wal记录,主库的连接信息从recovery.conf文件中读取(MySQL是change master命令之后,直接存在masterinfo文件里面,或者每次start slave的时候,手工指定)。

而如果从库想要中断主从复制,不是执行一个stop slave(MySQL)命令,而是在操作系统设置一个trigger文件。
9.1的(半)同步复制实现
2011年,pg 9.1发布,其中引入的新复制机制,就是同步复制这个大杀器了。
在MySQL中,有个被称为“半同步复制”的机制,就是说当主库收到客户端的commit发出来之后,直到从库接受完成这个事务所有的event,并且确认flush到relay日志之后,这个commit才会返回给客户端,客户端收到commit的时候,就代表即便主库宕机,数据也必然已经存在于从库,也就是“没有数据丢失”。
简单概括来说,PG在9.1中实现的同步复制,也是这么一回事,把关键字event替换成redo,relay日志替换为从库wal日志就可以。
注:下图仅为相关流程的简化图,仅保留了与复制相关的逻辑,对于WAL子系统没有详细展开,后续其他图片一样,都是简化图.
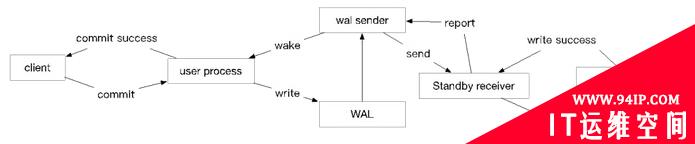
但实现的细节上,还是有很多区别的(MySQL的讨论基础版本一律为MySQL 8.0——好吧,我知道这个有些不公平)。
比如允许在回话或者单个事务级别控制,区分“重要”事务与“不重要”的事务,MySQL中,半同步会在遇到从库响应超时的时候,进行自动的全库降级(rpl_semi_sync_master_wait_no_slave控制)。
比如其设置哪些从库是半同步复制的时候,是通过逗号切割的方式指定一个或者多个(但只支持其中的某一个作为同步从库,首先选取***个作为同步节点,如果***个出问题,则选取第二个,以此类推),而MySQL的半同步复制,则是保障“只要有rpl_semi_sync_master_wait_for_slave_count个从库接收到”这个边界点。
比如由于rollback实现机制问题,PG的rollback不会受到同步复制阻塞,而MySQL在特定情况(可以参考https://my.oschina.net/llzx373/blog/282768 这篇文中,讨论的在rollback情况下,也会产生binlog的讨论)下,即便是rollback,也需要等待半同步响应。
比如事务可见性上,PG是直接通过事务id控制,而MySQL在5.7引入rpl_semi_sync_master_wait_point来处理(MySQL 半同步复制在5.7之前,主库的其他事务可以看到在等待半同步复制返回的事务的数据,即便这个事务尚未对客户端返回commit)
顺带一提,pg_basebackup这个命令也是这个版本中引入,主要用来搞从库和数据库备份。
PG的从库也可以通过报告查询所需要的最老事务点给主库的方式,避免主库的数据清理(vacuum)清理掉从库查询所需要的数据,当然,从库的长时间查询也会导致主库文件放大,具体使用决策上,值得考量。
而在控制复制启停的方式上,也提供了sql函数调用,而非只是纯粹依赖触发文件。(pg_wal_replay_pause(),pg_wal_replay_resume())
9.2的级联复制
级联复制,也就是A->B->C这种形态的复制,其***的意义,是降低主库的复制负载压力。
复制负载这个问题的来源,是类似互联网业务中,写少读多,一个主库,可能要承担几十个从库(记得有次春节时候,我们给一个主库扩出几十个从库)的日志发送行为,无论从磁盘压力还是网络带宽来说,级联复制都是有必要引入的。
当然,级联复制的C,就必然是异步复制了。

pg_basebackup也可以在从库执行备份了,可以避开备份对主库的性能影响。
而在同步复制上,新增了一个remote_write 级别,意思是,只要从库接收到wal日志就可以,不需要保障必须flush到磁盘的情况下,就可以确认commit成功了。

9.3的性能与易用性
这个版本没有本质性的特性变更,但在易用性和性能上,做了相当大的改进。
比如当多个从库中的某一个从库被提升为主库之后,其他从库可以直接切换过去,而在之前,必须重新同步。
比如pg_basebackup可以直接生成一个recovery.conf文件。
9.4逻辑日志导出与延迟备份
这个版本开始,xlog(wal日志)支持逻辑解析方式的导出,用于逻辑复制,或者跨数据库类型复制这种操作,甚至逻辑复制连同步复制都可以支持,唯一的限制,是逻辑复制只能作用于单库而非全局。
而replication slot的概念,也是这个版本开始引入。
之前提到过,为了避免主库清理掉从库尚需使用的数据,从库需要给主库报告所需要的事务点信息,在9.4开始,这个机制被单独提出来,称为replication slot,其主要的作用,是为物理复制,以及逻辑复制,提供维持事务点信息的视图,避免从库连接断开等原因导致的数据清理。
而在复制应用上,这个版本开始,PG增加了延迟复制这个特性,对于误删除操作等诸多问题,这个特性可以让数据恢复时间尽可能地缩短了。
9.5性能与易用性
这个版本没有大的变更,主要是以下一些内容:
允许WAL日志以压缩形态传输到从库,以主从库CPU换取较低的网络消耗。
recovery.conf的主库连接信息,可以以URI(postgres://)的形式来写。
新增了wal_retrieve_retry_interval 参数来控制从库失败后的重试。
9.6多个同步复制从库以及真-同步复制
说个题外话,PG在9.6开始,支持了并行查询,并在随后的版本中做到了很大的增强,这点也是我认为PG对比MySQL上,有绝对优势的一个特性。而PG的主要槽点之一vacuum冻结,也是在这个版本引入不再重复处理已经完全冻结的数据块这个重要特性的。
前文中提到,MySQL有个参数rpl_semi_sync_master_wait_for_slave_count控制同步的从库数量,而PG则是从设定的列表中选取某一个,在9.6开始,这个设计被变更为,可以等到wal被确认写入多个从库之后,再返回commit。
synchronous_standby_names参数也不仅仅是逗号切割的列表,变成了 n(s1,s2,s3)这种形态,让前n个数据库达到wal条件后确认commit。
在前面同步复制的讨论中,提到PG的同步复制,与MySQL半同步复制实现机理基本类似,但在9.6开始,新增了remote_apply 这个同步点,也就是,直到从库应用了对应的wal日志,主库才能返回commit成功,可以做到主库提交从库立即可见的效果。我相信不止我一个人被开发问到,说我主库写入的语句,到从库去查,为啥查不着的问题,而在当代的大型项目中,可能上层应用直接调用读写的假设,就是写入立即可读,下层如果贸然采用了传统的读写分离手段,可能就会导致上层应用无法马上看到数据的问题了,这个问题再掺和上主从延迟的种种纠结,是我在传统行业客户中,遇到最多的问题之一。
10 发布订阅式逻辑复制
逻辑复制在这个版本得到了极大的增强。
首先,是支持了逻辑复制这个特性本身。虽然9.4开始,xlog就已经可以解析并提供给逻辑复制使用,但PG在当时,并没有内置逻辑复制的相关组件,在10版本开始,支持了到表级别的逻辑复制,并且支持跨大版本,跨操作系统,跨机器架构之间的逻辑复制,灵活性上远胜物理复制(MySQL的binlog复制就是如此)。
synchronous_standby_names再次变更了语法,包括first和any两个语义,first指定的列表的话,会按照顺序优先级确认返回的从库响应达到指定数量(比如first 1(s1,s2)就类似旧的实现,选取***个作为同步点,如果***个s1失败了,再选取第二个s2作为同步点),而any语义的话,举个例子,类似any 2(s1,s2,s3)这种,则是允许三个从库中,任意两个从库只要返回同步成功,就可以确认commit了。any来说,更类似MySQL中半同步的确认语义。
recovery模式的恢复目标点,除了timestamp,事务id之外,也支持了LSN号,恢复的时候更加灵活了。
另外估计是由于slot维持wal,导致一些为临时会话维护的slot导致wal积累(比如pg_basebackup,每次备份都需要创建slot,备份完成后,slot还需要处理掉),这个版本开始,slot支持仅为当前会话提供的临时slot避免这个问题。
11 边角修补的复制特性
11大版本的主要功能变化,是分区表终于可以用了,而不是必须得采用第三方插件,包括hash分区,分区表上的主键,外键,全局索引,触发器这些,都终于支持了。
而在复制特性上,这个版本基本上没有什么大的变化,都是些边边角角的修补。
比方在做备份的时候,增加对数据块的校验。
比如pg_stat_wal_receiver 视图,增加了机器与端口信息。
乏陈可述,但就PG目前在复制上已经做的事情来看,的确也没有更强的需求来驱动这方面的进一步增强。
结语以及个人思考
从远不能胜任,到功能完备种种包含在内,PG虽然脚步略迟,但很快地走完了这些路径,就功能性而言,的确当得起一个“功能***大的开源数据库”的称呼。
佛门讲修行,其中一道障碍称为“知见障”,是说对一个东西认知越多,看其他东西的时候,成见也就越多,也就越难有一个清晰的认知(注:这个是知见障的一种解释,而且应该是佛教禅宗本土化后的顿宗解释,原始佛教中,这个词应该是类似六根不净的一个概念,不是我这里要表达的意思)。
的确,我自己的感觉也好,和其他人聊数据库时候的感觉也罢,每个人都有以自己熟悉的,认知的“数据库”来去看其他数据库的习惯。
以我自己来说。
比如我对pg的vacuum这么纠结,是因为这个问题上,在MySQL,Oracle这俩我熟知的数据库中,都是(相对)很好地解决了这个问题的,而PG非得别别扭扭地不处理——是的,是可以有很多人工策略可以搞,是有很多参数设置合适可以避开,但为什么非得我去管?它自个安安静静地处理好不就得了?哪怕是***限度的单表上的并行vacuum也可以啊(MySQL 5.6之前单线程purge也是一个大坑,后来就改多线程了)。
比如对于DB2,这个是我学校学习数据库时候的教材数据库,我的诸多知识都是从这个数据库上学会的,当我之后不久去看Oracle的时候,***个反应是,隔离级别到哪里去了?——Oracle的隔离级别,除了RC,Serializable之外,其他隔离级别都是通过变通方式实现的,而DB2,是有很齐全的4个隔离级别的(虽然各个隔离级别名字和SQL标准的名字不是很一致)——后来我给别人讲隔离级别课程的时候,都是用DB2讲课,而不是拉一个其他数据库出来(MySQL InnoDB在RR处理了幻读,那Serializable级别和RR的区别,解释起来就很费工夫,而PG的几个隔离级中,读未提交读不到脏读,可重复读读不到幻读就更不用说了),我不知道有多少人拿着Oracle这种讲隔离级别,但就我个人的感觉来说,哪怕到现在,依然感觉非常别扭。
如果说要打破成见,莫过于了解下其他的东西,切切实实地了解其优缺点,做到在“应该用的地方去用”,在技术成长上,相信会有更好地进步。
另外,由于不同数据库之间,虽然以外部视角看,都是SQL语言控制的数据库,但内部实现的种种细节却都是全然不同的,作为DBA来说,如果不想要让自己的职业生命,被迫维系在某一个数据库上的话(DB2前车之鉴,我当初差点入走了这条路),那么打开思路,去切实了解一下其他数据库的种种特点,也不失为一个很好的防御措施。
作者:刘伟,云和恩墨软件开发部研究院研究员;前微博DBA,主要研究方向为开源数据库,分布式数据库,擅长自动化运维以及数据库内核研究。
参考
http://mysql.taobao.org/monthly/2015/12/05/
https://www.postgresql.org/docs/11/release.html
https://dev.mysql.com/doc/refman/8.0/en/replication-semisync.html
https://my.oschina.net/llzx373/blog/282768 mysql复制对事务的处理
转载请注明:IT运维空间 » 运维技术 » PostgreSQL复制特性历史漫谈
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值















发表评论