

笔者自2016年加入WiFi***钥匙,现任WiFi***钥匙高级架构师,拥有10年互联网研发经验,喜欢折腾技术。主要专注于:分布式监控平台、调用链跟踪平台、统一日志平台、应用性能管理、稳定性保障体系建设等领域。
在本文中,笔者将与大家分享一下在实时监控领域的一些实战经验,介绍WiFi***钥匙是如何构建APM端到端的全链路监控平台,从而实现提升故障发现率、缩短故障处理周期、减少用户投诉率、树立公司良好品牌形象等目标。
WiFi***钥匙开发运维团队的困扰
始于盛大创新院的WiFi***钥匙,截至到2016年底,我们总用户量已突破9亿、月活跃达5.2亿,用户分布在全球223个国家和地区,在全球可连接热点4亿,日均连接次数超过40亿次。
随着日活跃用户大规模的增长,WiFi***钥匙各产品线服务端团队正进行着一场无硝烟的战争。越来越多的应用服务面临着流量激增、架构扩展、性能瓶颈等问题。为了应对并支撑业务的高速发展,我们迈入了SOA、Microservice、API Gateway等组件化及服务化的时代。
伴随着各系统微服务化的演进,服务数量、机器规模不断增长,线上环境也变得日益复杂,工程师们每天都会面临着诸多苦恼。例如:线上应用出现故障问题时无法***时间感知;面对线上应用产生的海量日志,排查故障问题时一筹莫展;应用系统内部及系统间的调用链路产生故障问题时难以定位等等。
综上所述,线上应用的性能问题和异常错误已经成为困扰开发人员和运维人员***的挑战,而排查这类问题往往需要几个小时甚至几天的时间,严重影响了效率和业务发展。WiFi***钥匙亟需完善监控体系,帮助开发运维人员摆脱烦恼,提升应用性能。依据公司的产品形态及业务发展,我们发现监控体系需要解决一系列问题:
◆面对全球多地域海量用户的WiFi连接请求,如何保障用户连接体验?
◆如何通过全链路监控提升用户连接WiFi的成功率?
◆随着微服务大规模推广实施,钥WiFi***钥匙产品服务端系统越来越复杂,线上故障的发现、定位、处理难度也随之增长,如何通过全链路监控提升故障处理速度?
◆移动出海已经进入深入化发展的下半场,全链路监控如何应对公司全球化的业务发展?
◆……
全链路监控
早期为了快速支撑业务发展,我们主要使用了开源的监控方案保障线上系统的稳定性:Cat、Zabbix,随着业务发展的需要,开源的解决方案已经不能满足我们的业务需求,我们迫切需要构建一套满足我们现状的全链路监控体系:
◆多维度监控(系统监控、业务监控、应用监控、日志搜索、调用链跟踪等)
◆多实例支撑(满足线上应用在单台物理机上部署多个应用实例场景需求等)
◆多语言支撑(满足各团队多开发语言场景的监控支撑,Go、C++、PHP等)
◆多机房支撑(满足国内外多个机房内应用的监控支撑,机房间数据同步等)
◆多渠道报警(满足多渠道报警支撑、内部系统对接,邮件、掌信、短信等)
◆调用链跟踪(满足应用内、应用间调用链跟踪需求,内部中间件升级改造等)
◆统一日志搜索(实现线上应用日志、Nginx日志等集中化日志搜索与管控等)
◆……
监控目标
从“应用”角度我们把监控体系划分为:应用外、应用内、应用间。如下图所示:

应用外:主要是从应用所处的运行时环境进行监控(硬件、网络、操作系统等)
应用内:主要从用户请求至应用内部的不同方面(JVM、URL、Method、SQL等)
应用间:主要是从分布式调用链跟踪的视角进行监控(依赖分析、容量规划等)
罗马监控体系的诞生
根据自身的实际需求,WiFi***钥匙研发团队构建了罗马(Roma)监控体系。之所以将监控体系命名为罗马,原因在于:
1、罗马不是一天成炼的(线上监控目标相关指标需要逐步完善);
2、条条大路通罗马(罗马通过多种数据采集方式收集各监控目标的数据);
3、据神话记载特洛伊之战后部分特洛伊人的后代铸造了古代罗马帝国(一个故事的延续、一个新项目的诞生)。
一个***的监控体系会涵盖IT领域内方方面面的监控目标,从目前国内外各互联网公司的监控发展来看,很多公司把不同的监控目标划分了不同的研发团队进行处理,但这样做会带来一些问题:人力资源浪费、系统重复建设、数据资产不统一、全链路监控实施困难。目前,各公司在监控领域采用的各解决方案,如下图所示:
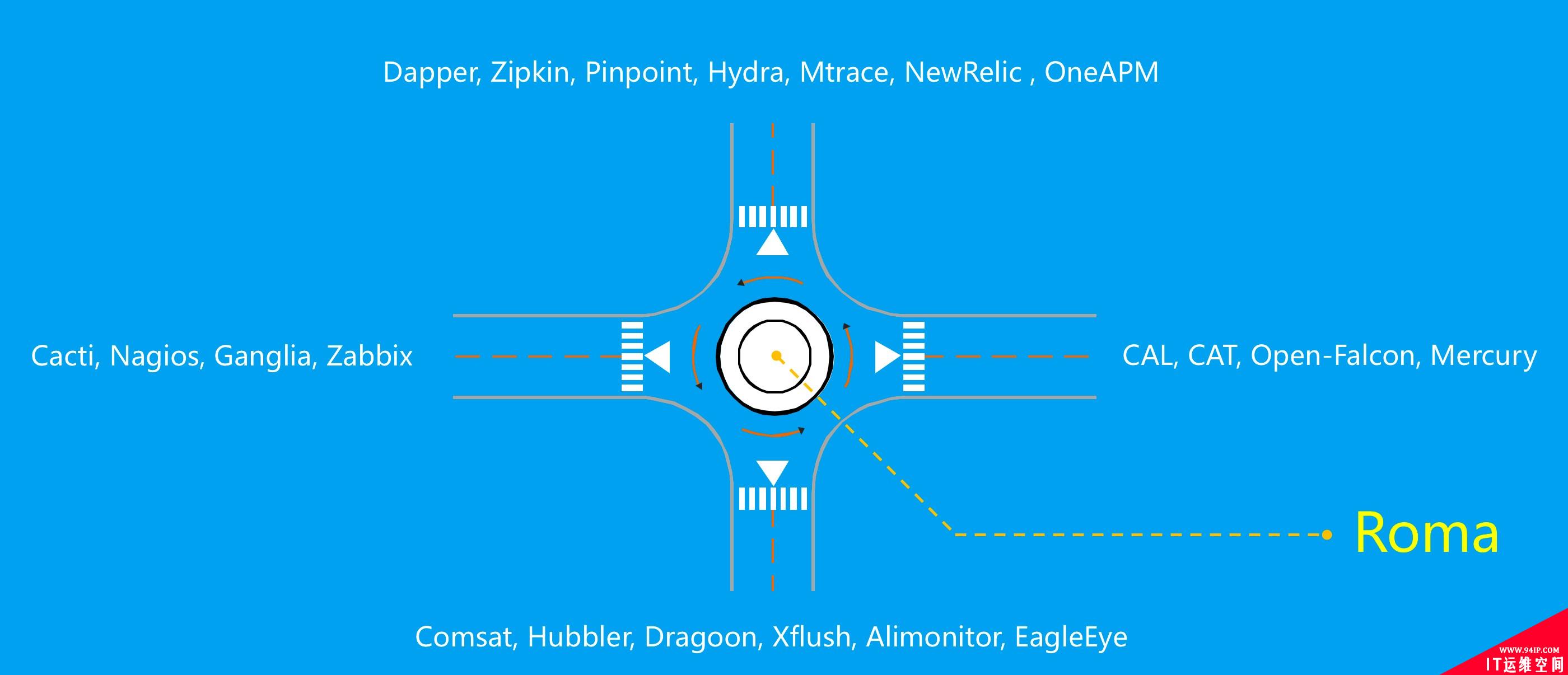
正如图中所示,罗马监控体系希望能够汲取各方优秀的架构设计理念,融合不同的监控维度实现监控体系的“一体化”、“全链路”等。
高可用架构之道
面对每天40多亿次的WiFi连接请求,每次请求都会经历内部数十个微服务系统,每个微服务的监控维度又都会涉及应用外、应用内、应用间等多个监控指标,目前罗马监控体系每天需要处理近千亿次指标数据、近百TB日志数据。面对海量的监控数据罗马(Roma)如何应对处理?接下来,笔者带大家从系统架构设计的角度逐一进行剖析。
架构原则
一个监控系统对于接入使用方应用而言,需要满足如下图中所示的五点:
• 性能影响:对业务系统的性能影响最小化(CPU、Load、Memory、IO等)
• 低侵入性:方便业务系统接入使用(无需编码或极少编码即可实现系统接入)
• 无内部依赖:不依赖公司内部核心系统(避免被依赖系统故障导致相互依赖)
• 单元化部署:监控系统需要支撑单元化部署(支持多机房单元化部署)
• 数据集中化:监控数据集中化处理、分析、存储等(便于数据统计等)
整体架构
Roma系统架构如下图所示:
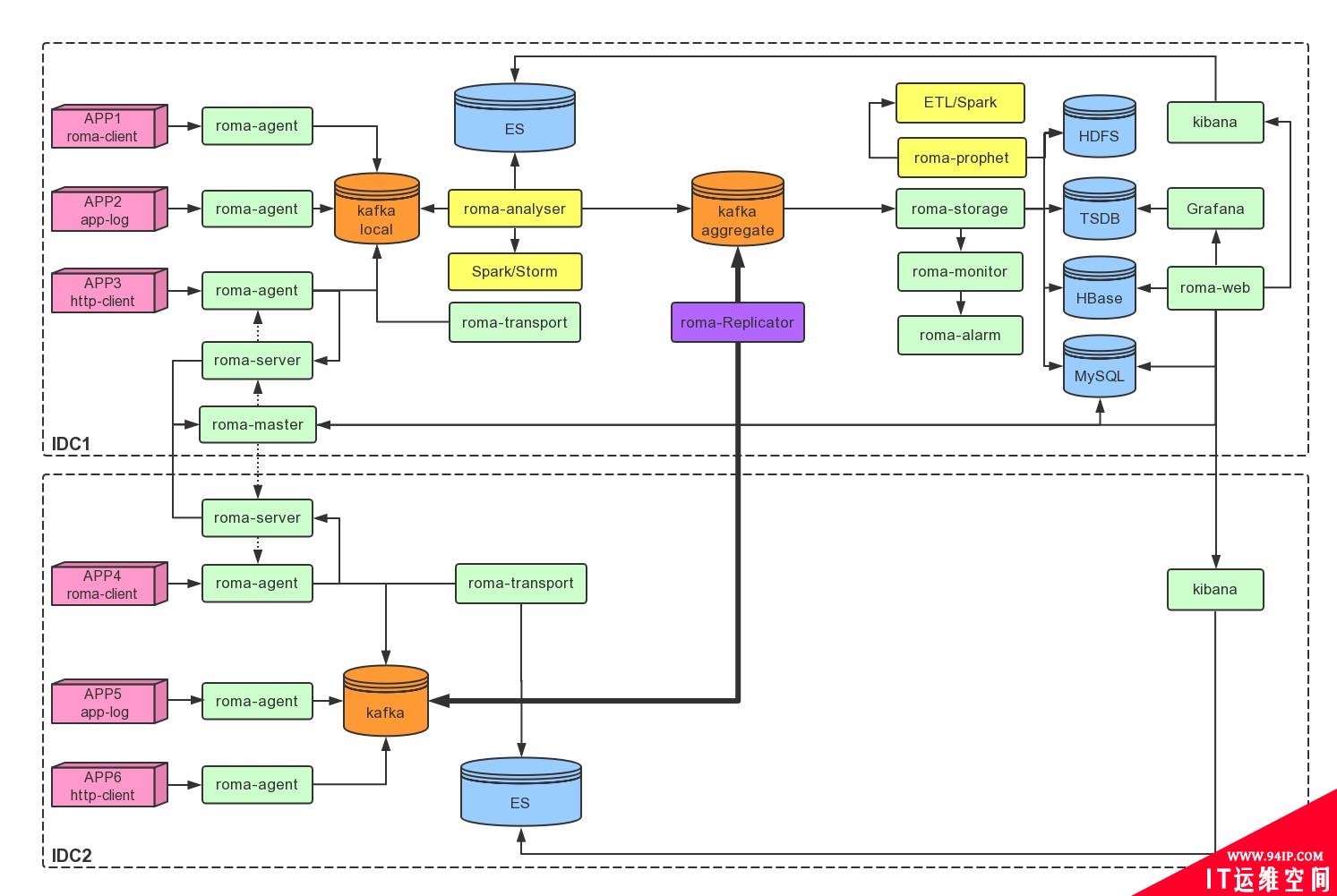
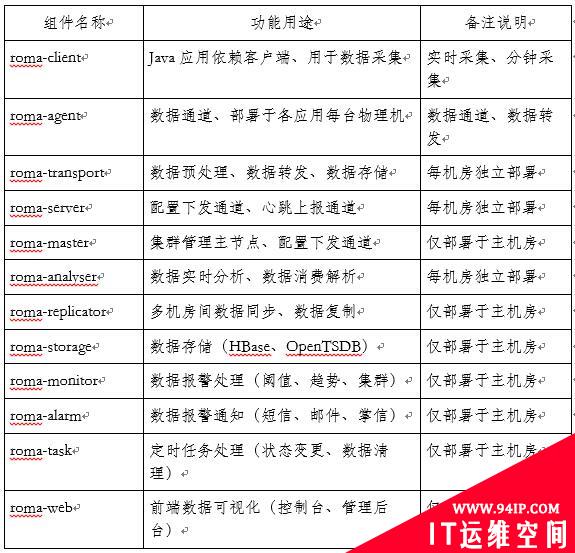
Roma架构中各个组件的功能职责、用途说明如下:
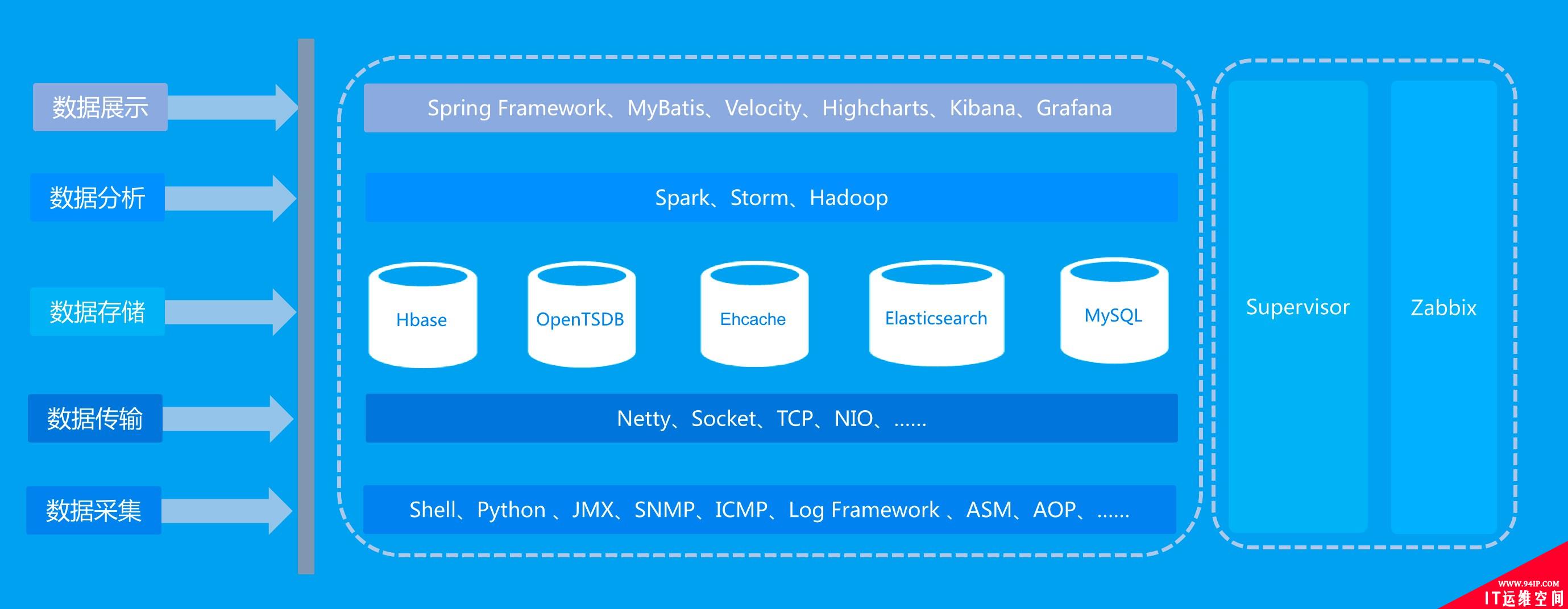
Roma整体架构中划分了不同的处理环节:数据采集、数据传输、数据同步、数据分析、数据存储、数据质量、数据展示等,数据流处理的不同阶段主要使用到的技术栈如下图所示:
数据采集
对于应用内监控主要是通过client客户端同所在机器上的agent建立TCP长连接的方式处理,agent同时也需要具备通过脚本调度的方式获取系统性能指标数据。
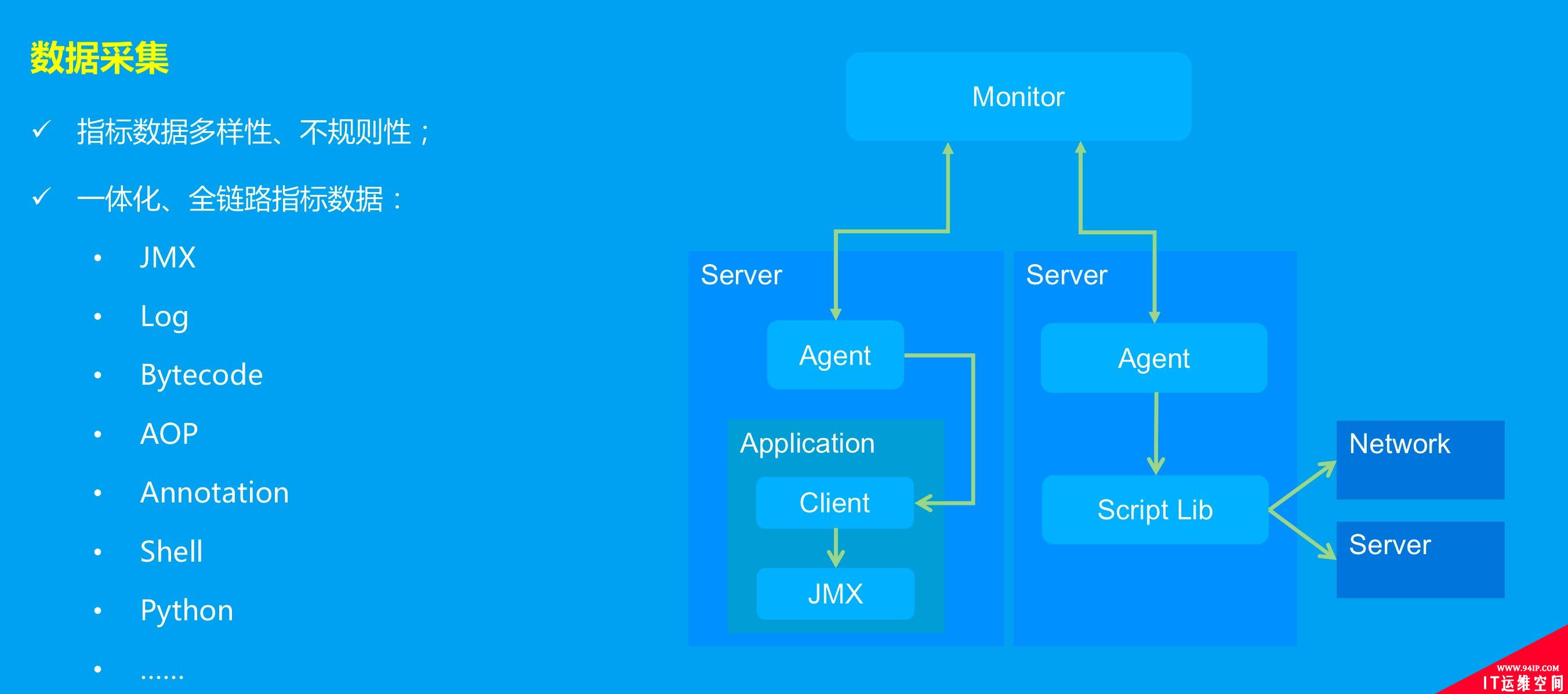
面对海量的监控指标数据,罗马监控通过在各层中预聚合的方式进行汇总计算,比如在客户端中相同URL请求的指标数据在一分钟内汇总计算后统计结果为一条记录(分钟内相同请求进行累加计算,通过占用极少内存、减少数据传输量),对于一个接入并使用罗马的系统,完全可以根据其实例数、指标维度、采集频率等进行监控数据规模的统计计算。通过各层分级预聚合,减少了海量数据在网络中的数据传输,减少了数据存储成本,节省了网络带宽资源和磁盘存储空间等。
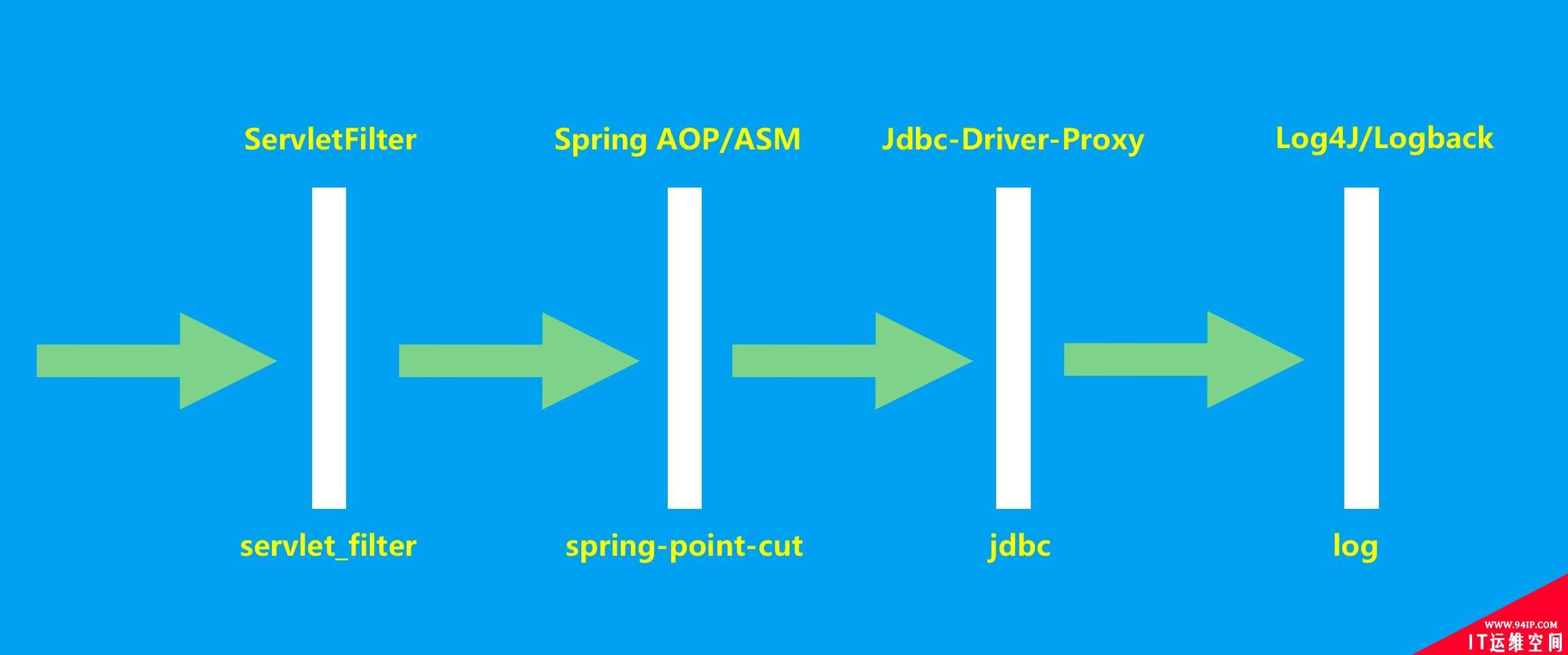
应用内监控的实现原理(如下图所示):主要是通过客户端采集,在应用内部的各个层面进行拦截统计: URL、Method、Exception、SQL等不同维度的指标数据。
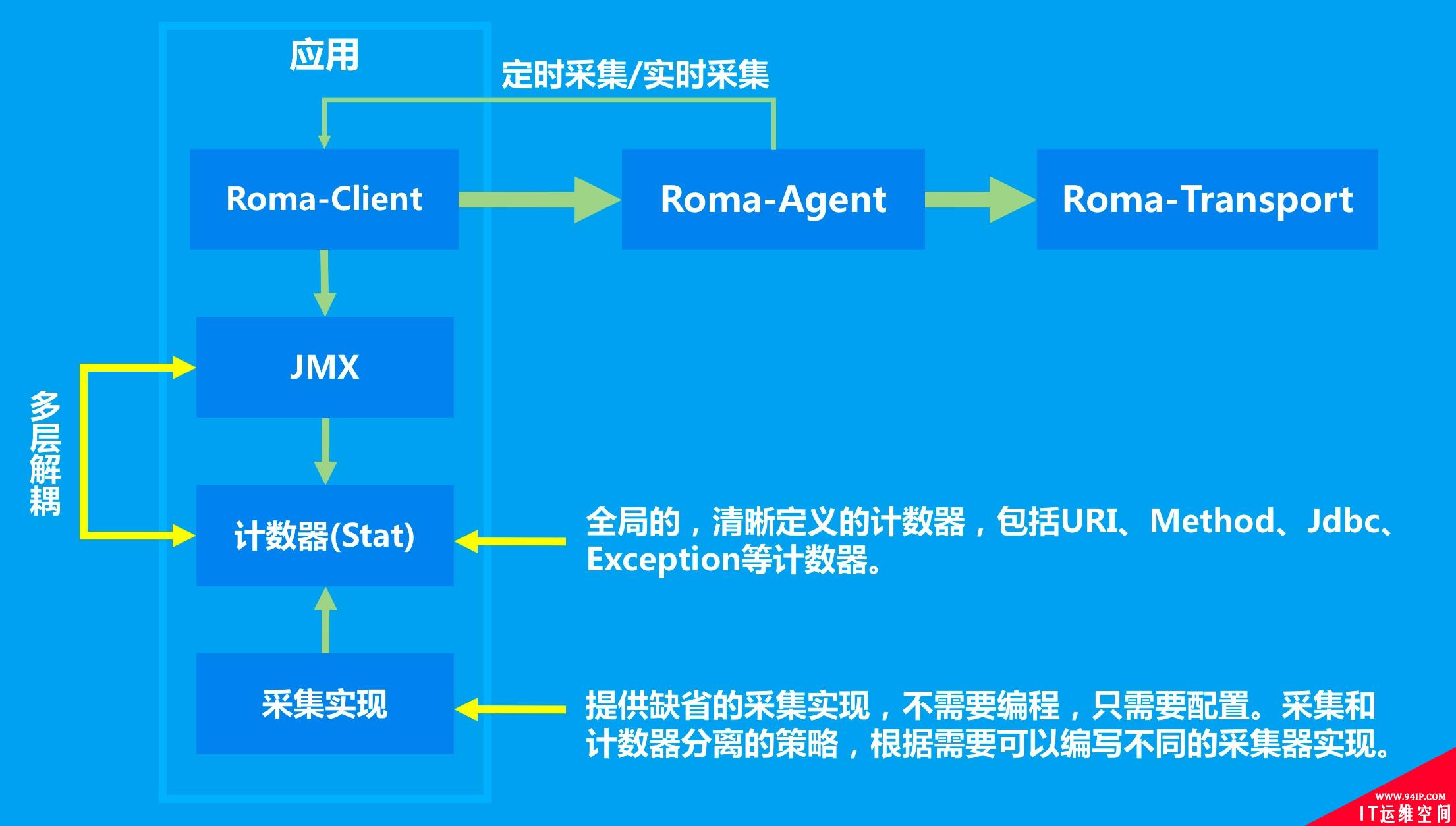
应用内监控各维度指标数据采集过程如下图所示:针对不同的监控维度定义了不同的计数器,最终通过JMX规范进行数据采集。
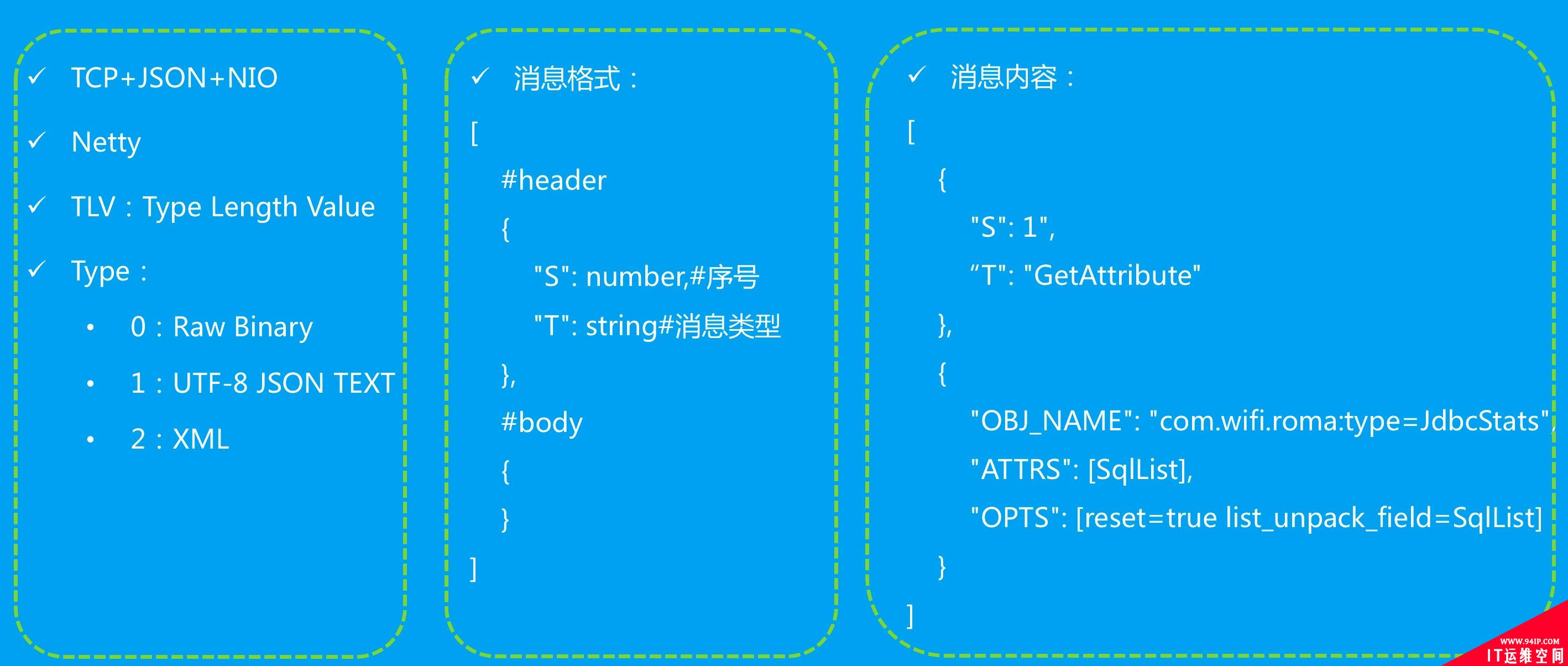
数据传输
数据传输TLV协议,支持二进制、JSON、XML等多种类型。
每台机器上都会部署agent(同客户端建立TCP长连接),agent的主要职责是数据转发、数据采集(日志文件读取、系统监控指标获取等),agent在获取到性能指标数据后会发送至kafka集群,在每个机房都会独立部署kafka集群用于监控指标数据的发送缓冲,便于后端的节点进行数据消费、数据存储等。
为了实现数据的高效传输,我们对比分析了消息处理的压缩方式,最终选择了高压缩比的GZIP方式,主要是为了节省网络带宽、避免由于监控的海量数据占用机房内的网络带宽。针对各个节点间数据通信的时序图如下图所示:建立连接->读取配置->采集调度->上报数据等。
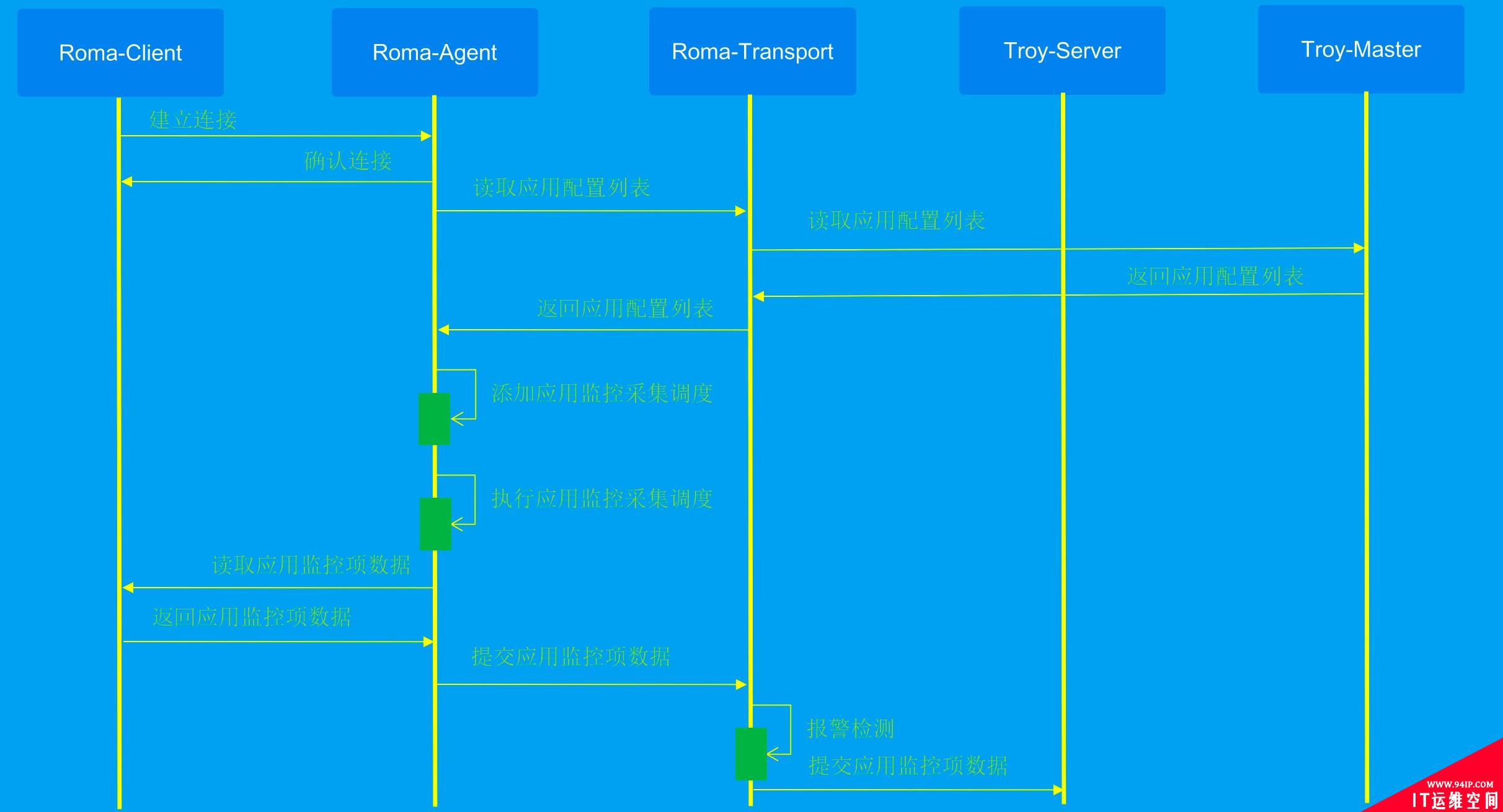
数据同步
海外运营商众多,公网覆盖质量参差不齐,再加上运营商互联策略的不同,付出的代价将是高时延、高丢包的网络质量,钥匙产品走向海外过程中,首先会对整体网络质量情况有正确的预期,比如如果需要对于海外机房内的应用进行监控则依赖于在海外建立站点(主机房)、海外主站同国内主站进行互联互通,另外需要对监控指标数据分级处理,比如对于实时、准实时、离线等不同需求的指标数据采集时进行归类划分(控制不同需求、不同数据规模等指标数据进行采样策略的调整)
由于各产品线应用部署在多个机房,为了满足各个应用在多个机房内都可以被监控的需求,罗马监控平台需要支持多机房内应用监控的场景,为了避免罗马各组件在各个机房内重复部署,同时便于监控指标数据的统一存储、统一分析等,各个机房内的监控指标数据最终会同步至主机房内,最终在主机房内进行数据分析、数据存储等。
为了实现多机房间数据同步,我们主要是利用kafka跨数据中心部署的高可用方案,整体部署示意图如下图所示:
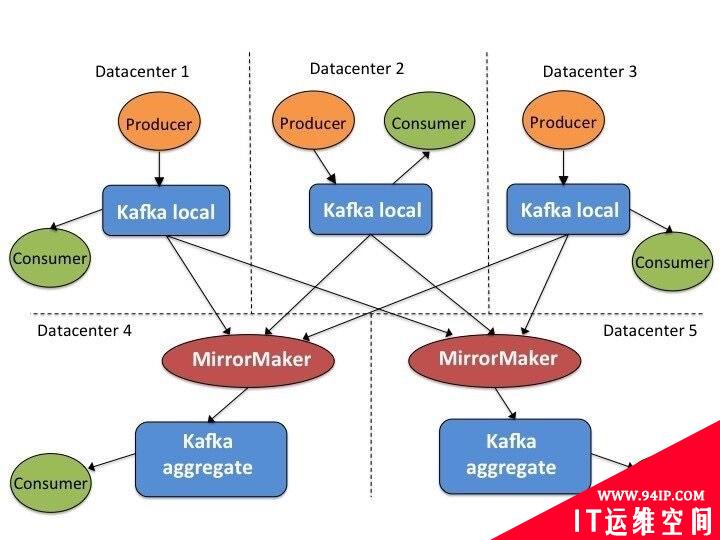
在对比分析了MirrorMaker、uReplicator后,我们决定基于uReplicator进行二次开发,主要是因为当MirrorMaker节点发生故障时,数据复制延迟较大,对于动态添加topic则需要重启进程,黑白名单管理完全静态等。虽然uReplicator针对MirrorMaker进行了大量优化,但在我们的大量测试之后仍遇到众多问题,我们需要具备动态管理MirrorMaker进程的能力,同时我们也不希望每次都重启MirrorMaker进程。
数据存储
为了应对不同监控指标数据的存储需求,我们主要使用了HBase、OpenTSDB、Elasticsearch等数据存储框架。
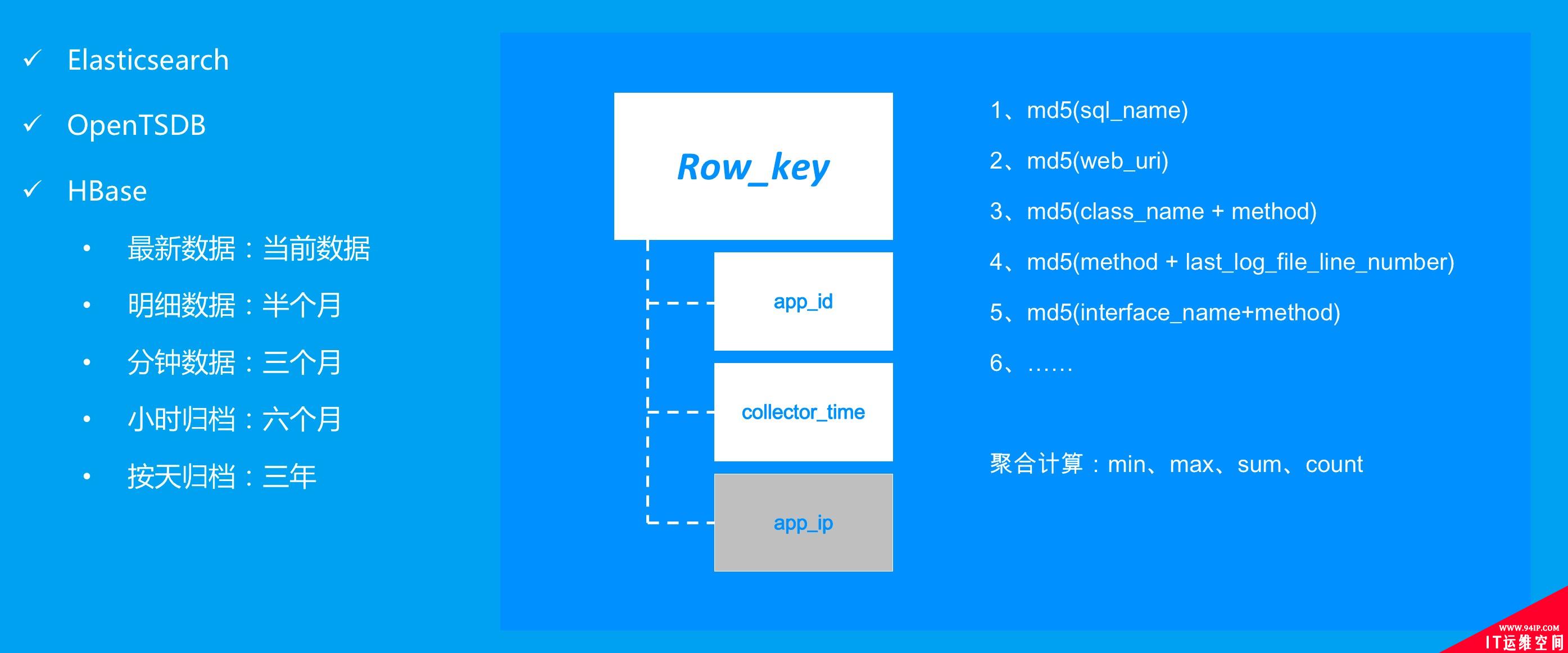
数据存储我们踩过了很多的坑,总结下来主要有以下几点:
• 集群划分:依据各产品线应用的数据规模,合理划分线上存储资源,比如我们的ES集群是按照产品线、核心系统、数据大小等进行规划切分;
• 性能优化:Linux系统层优化、TCP优化、存储参数优化等;
• 数据操作:数据批量入库(避免单条记录保存),例如针对HBase数据存储可以通过在客户端进行数据缓存、批量提交、避免客户端同RegionServer频繁建立连接(减少RPC请求次数)
数据质量
我们的系统在持续不断地产生非常多的事件、服务间的链路消息和应用日志,这些数据在得到处理之前需要经过Kafka。那么,我们的平台是如何实时地对这些数据进行审计呢?
为了监控Kafka数据管道的健康状况并对流经Kafka的每个消息进行审计,我们调研并分析了Uber开源的审计系统Chaperone,在经过各种测试之后,我们决定自研来实现需求,主要是因为我们希望具备任意节点任意代码块内的数据审计需求,同时需要结合我们自己的数据管道特点,设计和实现达成一系列目标:数据完整性与时延;数据质量监控需要近实时;数据产生问题时便于快速定位(提供诊断信息帮助解决问题);监控与审计本身高度可信;监控平台服务高可用、超稳定等;
为了满足以上目标,数据质量审计系统的实现原理:把审计数据按照时间窗口聚合,统计一定时间段内的数据量,并尽早准确地检测出数据的丢失、延迟和重复情况。同时有相应的逻辑处理去重,晚到以及非顺序到来的数据,同时做各种容错处理保证高可用。
数据展示
为了实现监控指标的数据可视化,我们自研了前端数据可视化项目,同时我们也整合了外部第三方开源的数据可视化组件(grafana、kibana),在整合的过程中我们遇到的问题:权限控制问题(内部系统SSO整合)主要是通过自研的权限代理系统解决、去除kibana官方提供的相关插件、完善并自研了ES集群监控插件等。
核心功能及落地实践
系统监控
我们的系统监控主要使用了OpenTSDB作为数据存储、Grafana作为数据展示,TSDB数据存储层我们通过读写分离的方式减轻存储层的压力,TSDB同Grafana整合的过程中我们也遇到了数据分组展示的问题(海量指标数据下查询出分组字段值,通过建立独立的指标项进行数据查询),如下图某机器系统监控效果:
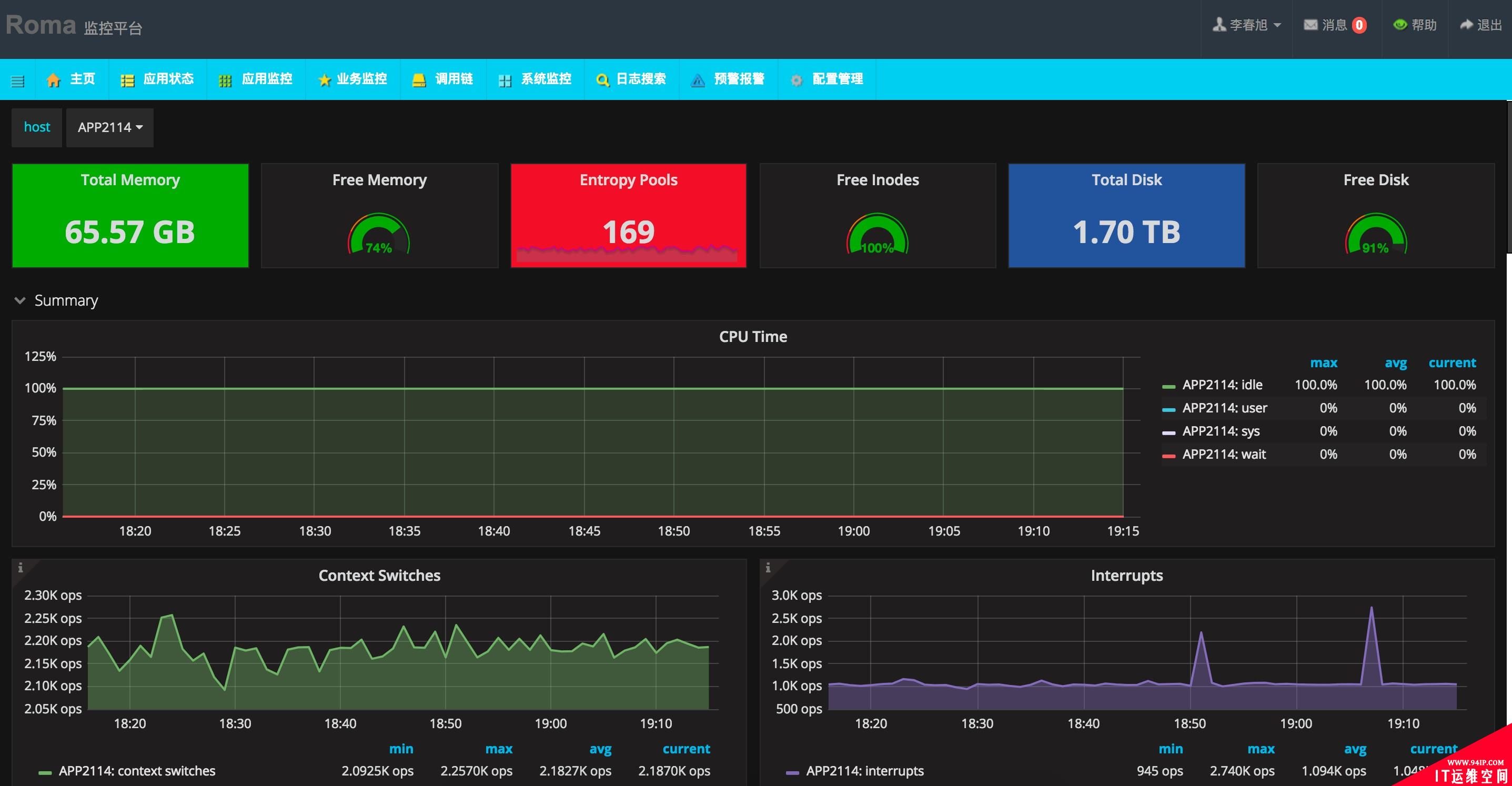
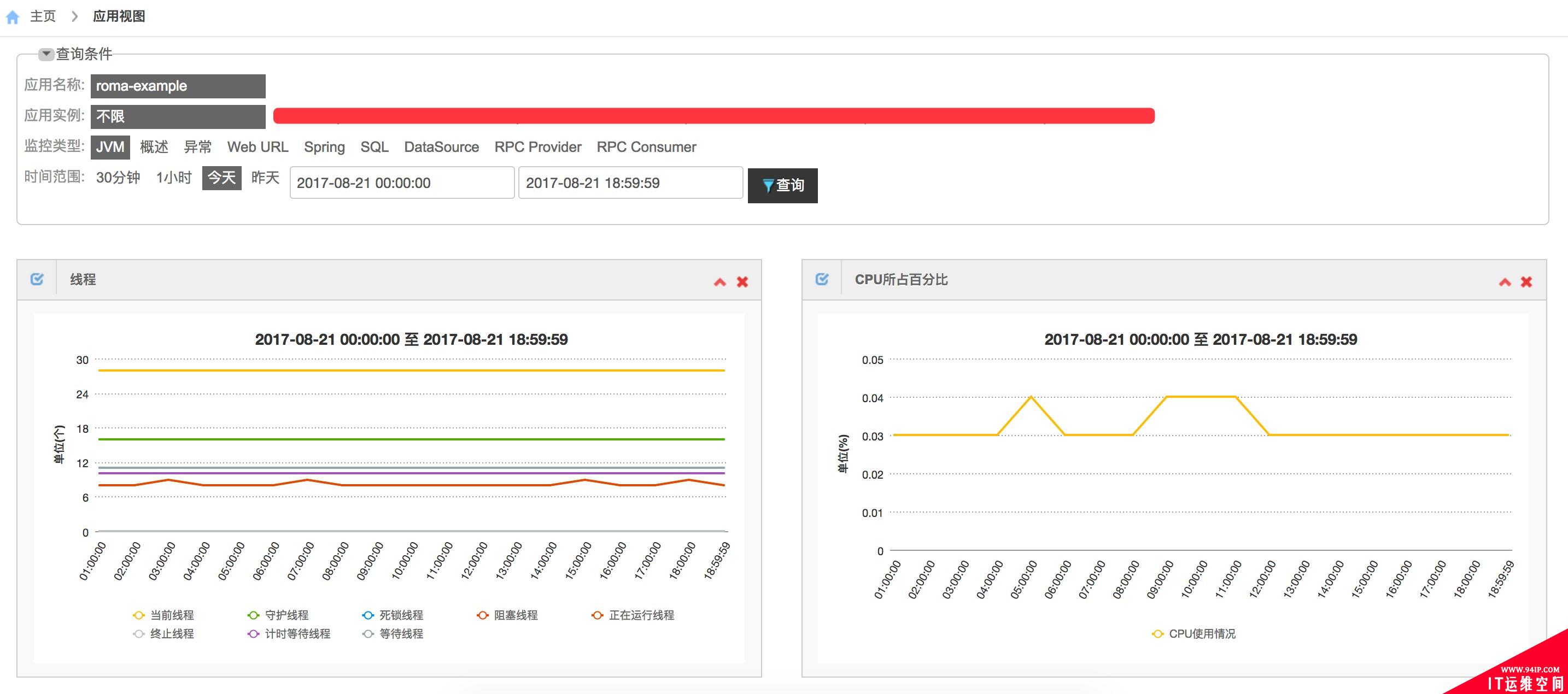
应用监控
针对各个Java应用,我们提供了不同的监控类型用于应用内指标数据的度量。
业务监控
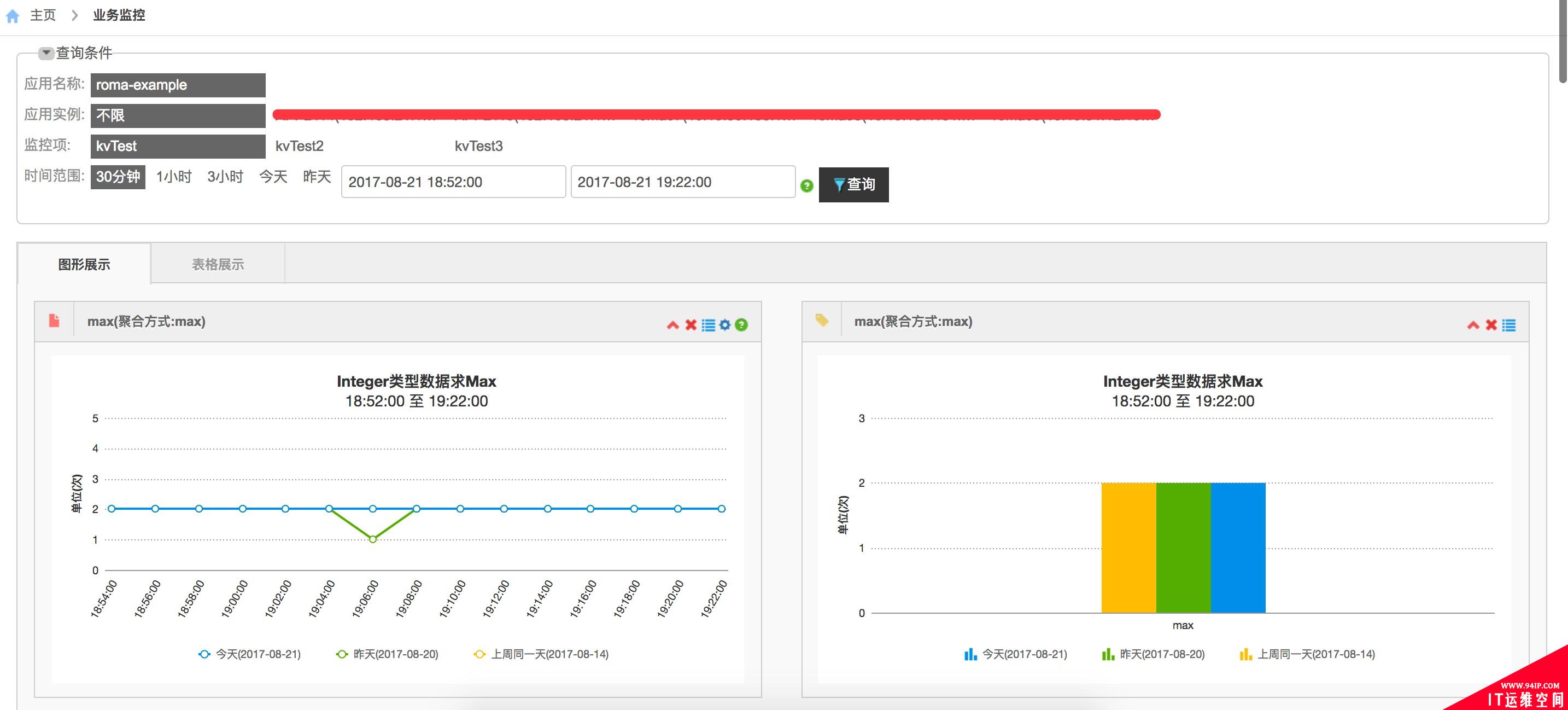
针对业务监控,我们可以通过编码埋点、日志输出、HTTP接口等不同的方式进行业务监控指标采集,同时支持多维度数据报表展示,如下图所示:
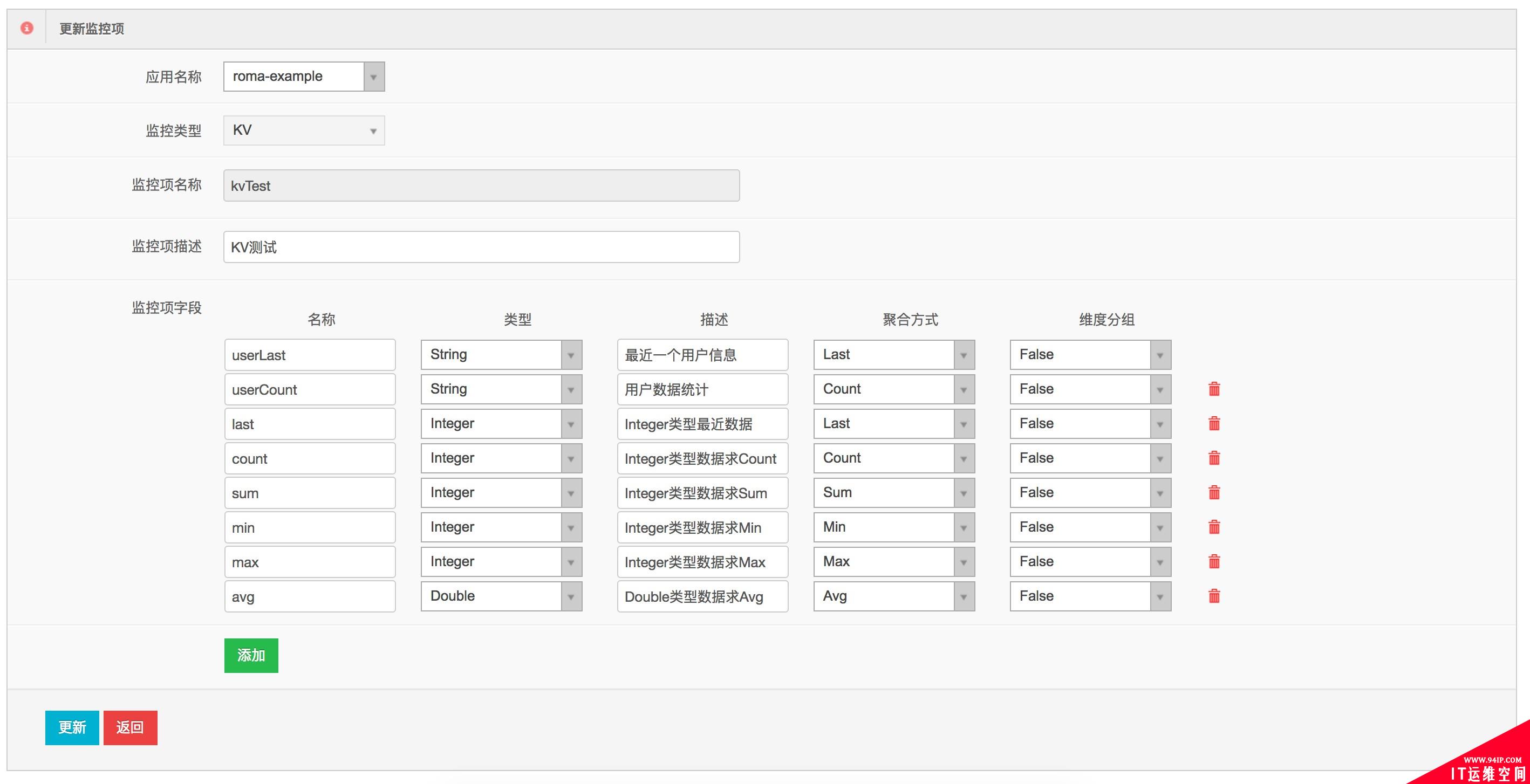
我们的业务监控通过自助化的方式让各应用方便捷的接入,如下图监控项定义:
日志搜索
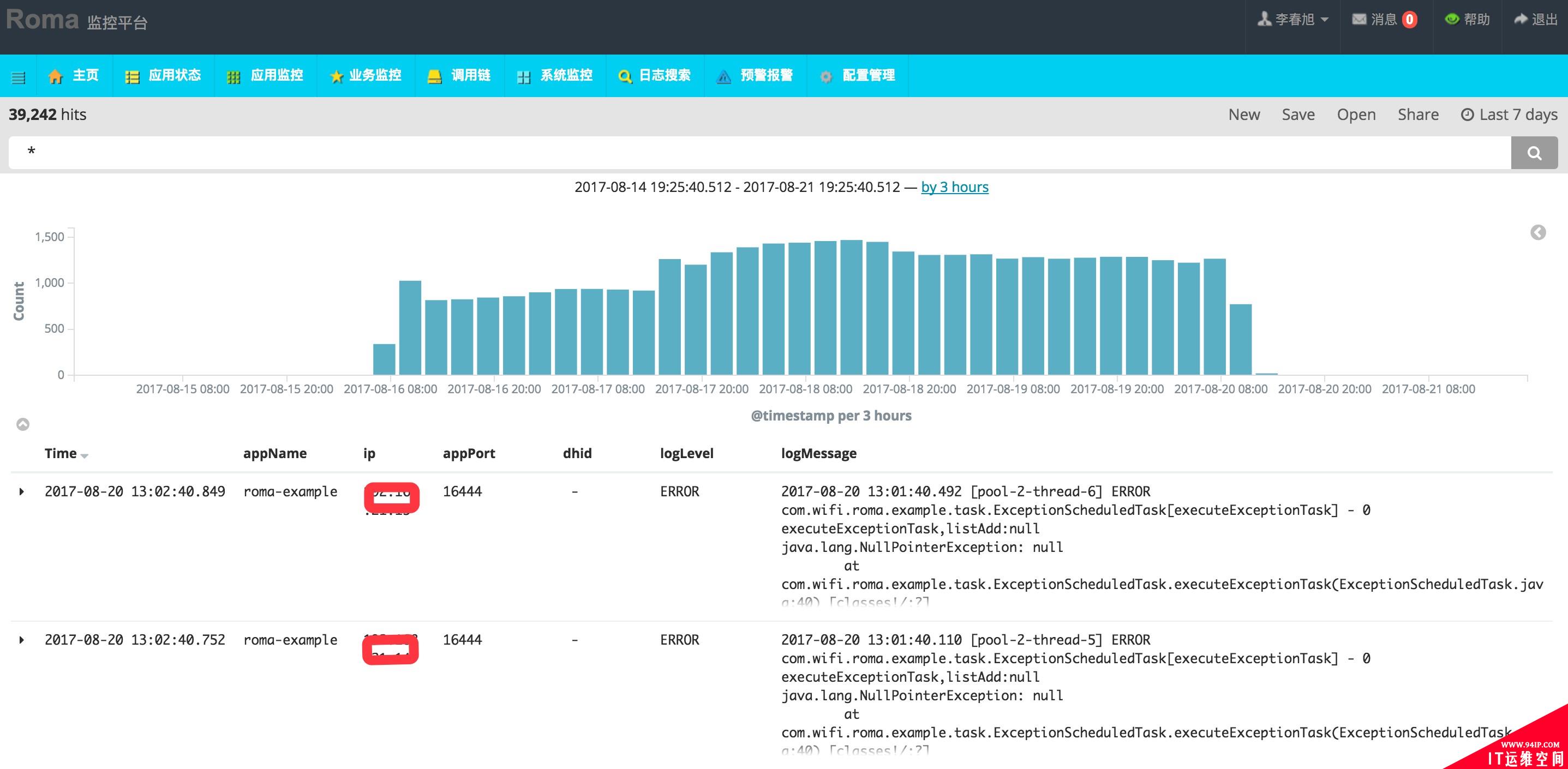
为了支撑好研发人员线上排查故障,我们开发了统一日志搜索平台,便于研发人员在海量日志中定位问题。
未来展望
随着IT新兴技术的迅猛发展,罗马监控体系未来的演进之路:
• 多语言支撑:满足多语言的监控需求(性能监控、业务监控、日志搜索等)
• 智能化监控:提高报警及时性、准确性等避免报警风暴(ITOA、AIOps)
• 容器化监控:随着容器化技术的验证落地实施,容器化监控开启布局;
总结
罗马(Roma)是一个能够对应用进行深度监控的全链路监控平台,主要涵盖了应用外、应用内、应用间等不同维度的监控目标,例如应用监控、业务监控、系统监控、中间件监控、统一日志搜索、调用链跟踪等。能够帮助开发者进行快速故障诊断、性能瓶颈定位、架构梳理、依赖分析、容量评估等工作。
转载请注明:IT运维空间 » 运维技术 » 百亿级访问量的实时监控系统如何实现?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/2.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值















发表评论