


导语
近年来,随着人工智能的蓬勃发展,机器学习技术在网络入侵检测领域得到了广泛的应用。然而,机器学习模型存在着对抗样本的安全威胁,导致该类网络入侵检测器在对抗环境中呈现出特定的脆弱性。本文主要概述由对抗样本造成的逃逸攻击,分为上下两篇。上篇从基本概念出发介绍逃逸攻击的工作机理,下篇则介绍一些针对逃逸攻击的防御措施。希望能让读者更清晰的认知基于机器学习的网络入侵检测器所存在的安全风险。
当网络入侵检测器遇到机器学习
网络入侵检测系统(Network Intrusion Detection System,NIDS)通过采集网络流量等信息,发现被监控网络中违背安全策略、危及系统安全的行为,是一种重要的安全防护手段。面对日益复杂的网络环境,传统NIDS所存在的缺点日益突出,例如系统占用资源过多、对未知攻击检测能力差、需要人工干预等。在此背景下,研究人员迫切地探寻新的解决方案,并将目光投向了发展迅速的机器学习技术。基于机器学习的网络入侵检测器是将网络入侵检测的问题建模成一个针对网络流量的分类问题,从而使用一些机器学习的方法精练出分类模型进行分类预测。目前,多种机器学习算法,例如决策树、支持向量机、深度神经网络等,被用于区分入侵流量和良性流量,并取得了良好的实验结果。
什么是对抗样本
2013年,Szegedy等人首次在深度神经网络(Deep Neural Network,DNN)中发现了对抗样本,并引起了机器学习社区的广泛讨论。对抗样本是指通过对原始的输入样本添加轻微的扰动所产生的输入样本,该样本与原始样本相近,却能够在不改变机器学习分类模型的情况下,导致目标模型输出错误的分类结果。事实上,从传统的机器学习模型到深度学习模型,再到强化学习模型,都存在对抗样本的问题。鉴于目前机器学习技术已渗透到图像识别、自然语言处理、恶意软件检测等多个领域,对抗样本的发现为狂热的机器学习应用浪潮带来了一定的冲击。
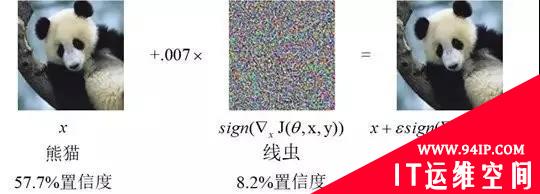
图1 一种对抗样本示意图
逃逸攻击
针对基于机器学习的NIDS,攻击者可利用对抗样本来逃逸NIDS对入侵流量的检测,这种攻击被称为逃逸攻击(或对抗样本攻击、对抗攻击等)。图2展示了一种经典的逃逸攻击流程。NIDS部署在被保护网络的边界,通过提取数据包或网络流的特征形成输入样本,然后利用机器学习分类模型来识别该样本是否属于入侵流量。在发动逃逸攻击时,攻击者首先捕获入侵流量所形成的输入样本,通过一定的手段来生成对抗样本,然后回放依据对抗样本产生的入侵流量。由于机器学习分类模型的脆弱性,该流量被NIDS错误分类成良性流量,从而到达受害网络。
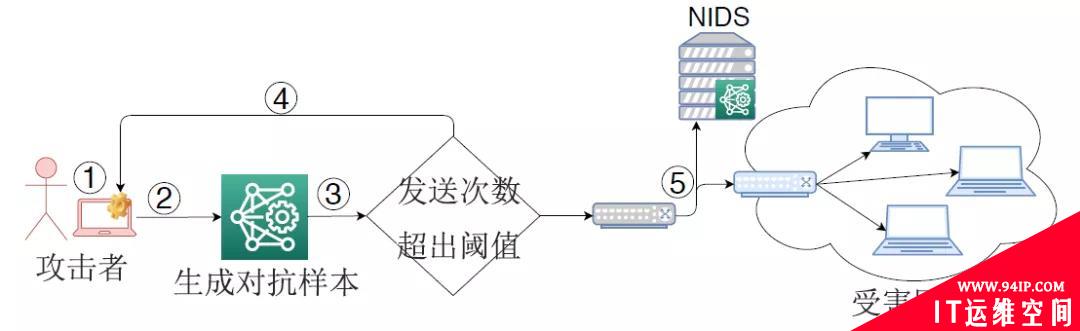
图2 一种逃逸攻击示意图
威胁模型
由攻击者发起的逃逸攻击可以从四个维度来刻画,分别是敌手知识、敌手能力、敌手目标、攻击策略。其中敌手知识是指攻击者掌握目标机器学习模型的背景信息量,包括模型的训练数据、特征集合、模型结构及参数、学习算法及决策函数、目标模型中可用的反馈信息等。根据敌手知识,可将逃逸攻击分为以下两类:
(1)白盒攻击。攻击者在完全了解目标模型的情况下发起攻击。在此情况下,目标模型的网络架构及参数值、为样本提取的特征集合、使用的训练方法等信息都暴露给了攻击者,另外在某些情况下还包括目标模型所使用的训练数据集。
(2)黑盒攻击。发起攻击时,攻击者仅对目标模型具有有限的知识,例如攻击者可获取模型的输入和输出的格式和数值范围,但是不知道机器学习模型的网络架构、训练参数和训练算法等。在此情况下,攻击者一般通过传入输入数据来观察输出、判断输出与目标模型进行交互。
对逃逸攻击而言,攻击者可不具备操纵目标模型、操纵目标模型的训练数据的能力。但是敌手能力必须包括可操纵目标模型的测试数据,即攻击者能够对用于测试模型的网络流量进行修改,这种修改可以在网络流(Flow)层进行也可以在数据包(Packet)层。对于逃逸攻击,敌手目的是影响目标机器学习模型的完整性(Integrity)。具体地讲,逃逸攻击的敌手目标包括以下几类:
(1)减小置信度:减小输入分类的置信度,从而引起歧义。
(2)无目标误分类:将输出分类更改为与原始类不同的任何类。
(3)有目标的误分类:强制将输出分类为特定的目标类。
(4)源到目的误分类:强制将特定的输入的输出分类为特定的目标类。
根据敌手知识和敌手目的将逃逸攻击的威胁模型进行整合,结果如图3所示。可以看出,黑盒模式下的有目标攻击将会极大地增加攻击难度。
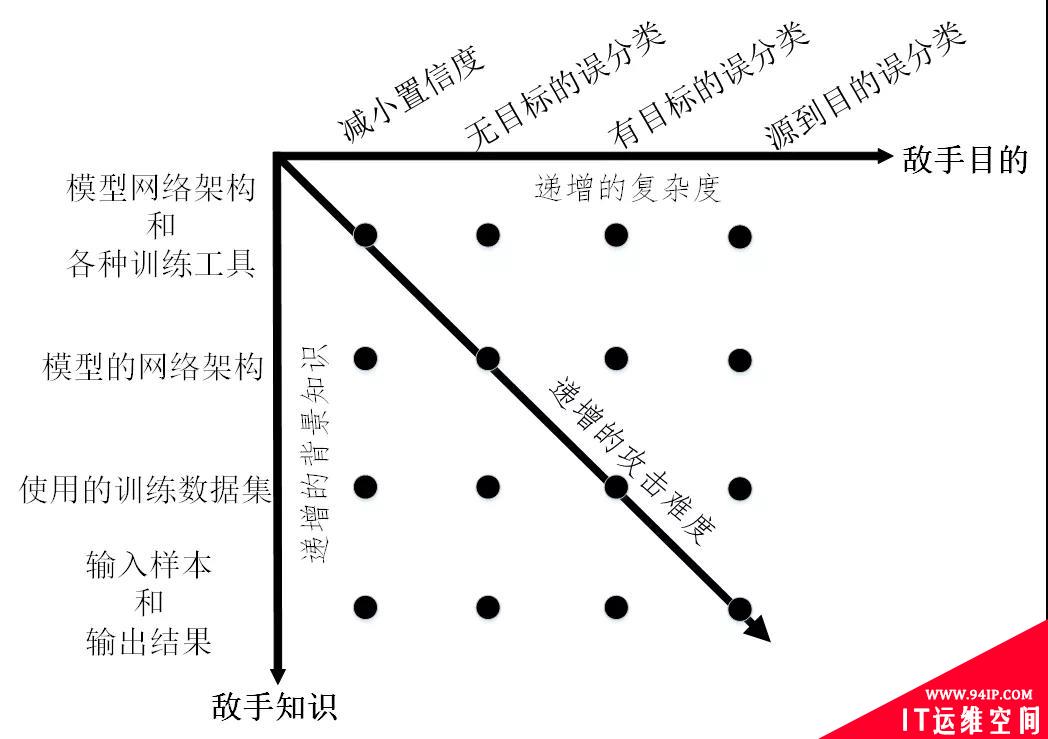
图3 逃逸攻击的威胁模型分类
常见的攻击策略
逃逸攻击的核心在于如何构造能够使机器学习模型产生误分类的对抗样本。针对基于机器学习的网络入侵检测器,目前研究人员已提出多种生成对抗样本的方法,主要包括以下几类:
(1)基于梯度的方法。该类方法仅适用于白盒攻击。在图像识别领域,Goodfellow等人[15]提出了快速梯度符号(FGSM)法,该方法假设攻击者完全了解目标模型,通过在梯度的反方向上添加扰动增大样本与原始样本的决策距离,从而快速生成对抗样本。随后,改进的方法例如PGD、BIM、JSMA等相继被提出。在此基础上,研究工作[1]-[6]都采用了这类方法来对修改网络流层上特征,进而生成针对网络入侵检测器的对抗样本。
(2)基于优化的方法。该类方法即存在于白盒攻击又存在于黑盒攻击。Szegedy等人[16]首次将寻找最小可能的攻击扰动转化为一个优化问题,并提出使用L-BFGS来解决这个分析。这种方法攻击成功率高,但计算成本也高。Carlini等人[17]对其进行了改进,提出了攻击效果更好的目标函数,并通过改变变量解决边界约束问题,被称为C&W攻击。研究工作[4]-[6]都采用了这种方法来生成攻击NIDS的对抗样本。此外,文献[12][13]研究在黑盒模式下生成对抗样本的问题,同样将其转化为一种优化问题,并分别采用遗传算法和粒子群算法来解决,从而快速搜索出对抗样本。
(3)基于生成对抗网络的方法。该类方法常见于发动黑盒攻击。研究工作[7]-[9]均建立生成对抗网络(Generative Adversarial Network,GAN)来生成对抗样本。一般地,目标NIDS作为GAN的检测器,GAN的生成器则用于产生对抗扰动,并且GAN检测器对输入样本的预测得分将用来训练GAN的生成器。特别地,生成网络一旦训练完毕,就可以有效地为任何样本生成扰动而不需要向目标NIDS发送任何问询。
(3)基于决策的方法。该类方法适用于在黑盒模式下发动攻击。在真实的逃逸攻击中,攻击者很少能够获取目标模型的预测值,针对目标模型仅给出类别标签的情况,Peng等人[14]提出了改进的边界攻击方法来生成DDoS攻击的对抗样本。该方法的主要思想是通过迭代地修改输入样本来逼近目标模型的决策边界。此外,研究工作[10]同样采用基于决策的思想,借助有限的目标NIDS的反馈,不断的在数据包层次上或网络流层次上修改NIDS的原始输入样本,从而生成逃逸的变异样本。与其它方法相比,该类方法需要的模型信息更少、实用性更高,但是需要向目标NIDS发送大量的问询,需要更高的攻击代价。
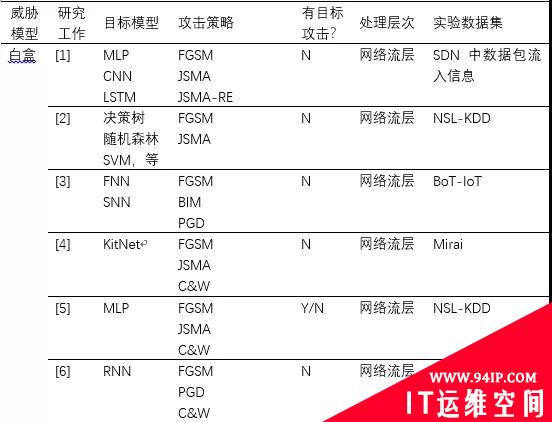
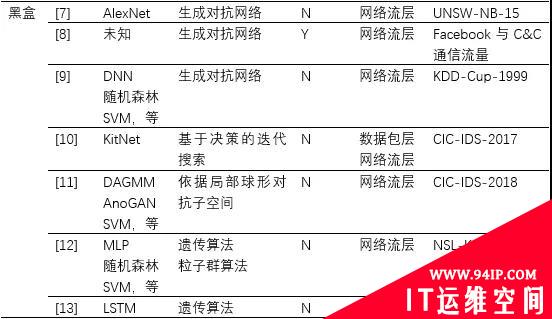
表1 逃逸攻击的相关研究工作
小结:
机器学习为网络入侵检测提供了新的解决思路,同时也带来了新的安全隐患。在机器学习成为网络安全利器的道路上,攻击与防御之间博弈不断升级,“机器学习+网络安全”的研究依然任重道远。
参考文献
[1] Chi-Hsuan Huang, Tsung-Han Lee, Lin-huang Chang,等. Adversarial Attacks on SDN-Based Deep Learning IDS System[C]. International Conference on Mobile & Wireless Technology. Springer, Singapore, 2018.
[2] M. Rigaki. Adversarial Deep Learning Against Intrusion Detection Classifiers. Dissertation, 2017.
[3] Ibitoye O, Shafiq O, Matrawy A, et al. Analyzing Adversarial Attacks against Deep Learning for Intrusion Detection in IoT Networks[C]. global communications conference, 2019.
[4] Clements J, Yang Y, Sharma A A, et al. Rallying Adversarial Techniques against Deep Learning for Network Security.[J]. arXiv: Cryptography and Security, 2019.
[5] Wang Z. Deep Learning-Based Intrusion Detection With Adversaries[J]. IEEE Access, 2018: 38367-38384.
[6] Hartl A, Bachl M, Fabini J, et al. Explainability and Adversarial Robustness for RNNs.[J]. arXiv: Learning, 2019.
[7] 潘一鸣, 林家骏. 基于生成对抗网络的恶意网络流生成及验证[J]. 华东理工大学学报(自然科学版), 2019, 45(02):165-171.
[8] Rigaki M, Garcia S. Bringing a GAN to a Knife-Fight: Adapting Malware Communication to Avoid Detection[C]. ieee symposium on security and privacy, 2018: 70-75.
[9] Usama M, Asim M, Latif S, et al. Generative Adversarial Networks For Launching and Thwarting Adversarial Attacks on Network Intrusion Detection Systems[C]. international conference on wireless communications and mobile computing, 2019: 78-83.
[10] Hashemi, M. J., Cusack, G, et al. Towards Evaluation of NIDSs in Adversarial Setting. the 3rd ACM CoNEXT Workshop on Big Data, Machine Learning and Artificial Intelligence for Data
Communication Networks. 2019: 14-21.
[11] Kuppa A, Grzonkowski S, Asghar M R, et al. Black Box Attacks on Deep Anomaly Detectors[C]. availability, reliability and security, 2019.
[12] Alhajjar, E, Paul M and Nathanie D. B. Adversarial Machine Learning in Network Intrusion Detection Systems. arXiv preprint arXiv:2004.11898 (2020).
[13] Huang W, Peng X, Shi Z, et al. Adversarial Attack against LSTM-based DDoS Intrusion Detection System. arXiv preprint arXiv:2613.1684 (2020).
[14] Peng X, Huang W, Shi Z, et al. Adversarial Attack Against DoS Intrusion Detection: An Improved Boundary-Based Method[C]. international conference on tools with artificial intelligence, 2019.
[15] Goodfellow I J , Shlens J , Szegedy C . Explaining and harnessing adversarial examples[C]// ICML. 2015.
[16] Szegedy, C, et al. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013).
[17] Carlini N , Wagner D . Towards Evaluating the Robustness of Neural Networks[J]. 2016.

转载请注明:IT运维空间 » 安全防护 » 漫谈在人工智能时代网络入侵检测器的安全风险之逃逸攻击
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-
MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-

Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)









发表评论