

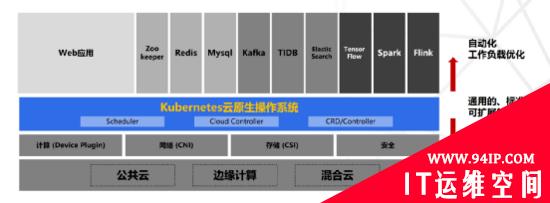
 Kubernetes是一个开源容器编排平台,管理大规模分布式容器化软件应用,是云计算发展演进的一次彻底革命性的突破。Kubernetes是谷歌的第三代容器管理系统,是Borg独特的控制器和Omega灵活的调度器的组合。Kubernetes中的应用被打包成与环境完全分离的容器镜像,并且自动配置应用并维护跟踪资源分配。
Kubernetes是以应用为中心的技术架构与思想理念,向下屏蔽基础设施差异,实现底层基础资源统一调度及编排;向上通过容器镜像标准化应用,实现应用负载自动化部署;中间通过Kubernetes通用的编排能力,开放API以及自定义CRD扩展能力,打造云原生操作系统能力,形成云计算新界面;助力研发团队快速构建标准化、弹性高可靠、松耦合、易管理维护的应用系统,提升交付效率,降低运维复杂度。Kubernetes在技术架构方面具备三个能力:
Kubernetes是一个开源容器编排平台,管理大规模分布式容器化软件应用,是云计算发展演进的一次彻底革命性的突破。Kubernetes是谷歌的第三代容器管理系统,是Borg独特的控制器和Omega灵活的调度器的组合。Kubernetes中的应用被打包成与环境完全分离的容器镜像,并且自动配置应用并维护跟踪资源分配。
Kubernetes是以应用为中心的技术架构与思想理念,向下屏蔽基础设施差异,实现底层基础资源统一调度及编排;向上通过容器镜像标准化应用,实现应用负载自动化部署;中间通过Kubernetes通用的编排能力,开放API以及自定义CRD扩展能力,打造云原生操作系统能力,形成云计算新界面;助力研发团队快速构建标准化、弹性高可靠、松耦合、易管理维护的应用系统,提升交付效率,降低运维复杂度。Kubernetes在技术架构方面具备三个能力:
-
敏捷的弹性伸缩能力:不同于虚拟机分钟级的弹性伸缩响应,容器应用可实现秒级甚至毫秒级的弹性伸缩响应;
智能的服务故障自愈能力:容器应用具有极强的自愈能力,可实现应用故障的自动摘除与重构;
大规模的复制分发能力:容器应用标准化的交付制品,可实现跨平台、跨区域,云边一体规模化复制分发部署能力。
一、Kubernetes整体架构
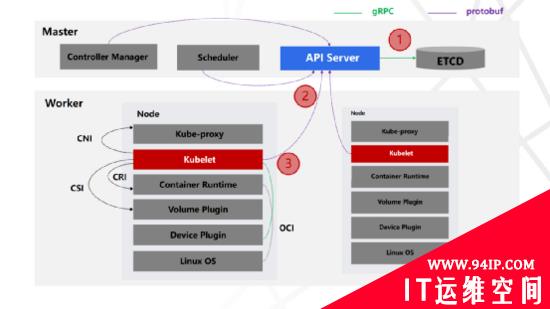 Kubernetes是典型的主从分布式架构,由集中式管理节点(Master Node),分布式的工作节点(Worker Node)以及辅助工具组成。
Kubernetes是典型的主从分布式架构,由集中式管理节点(Master Node),分布式的工作节点(Worker Node)以及辅助工具组成。
1、集中式管理节点
集中式管理节点,对集群进行调度管理,有四大核心组件:
-
API Server:承担集群的网关,实现统一认证鉴权对外服务,同时也是管理Node/Pod资源代理通道;
Scheduler:资源调度器,除了Kubernetes默认的调度器,也支持自定义调度器;
ETCD:集群状态统一存储,与Zookeeper类似的key-value存储;
Controller Manger:控制管理器实现自愈、扩容、应用生命周期管理、服务发现、路由、服务绑定等能力;Kubernetes默认提供Replication Controller、Node Controller、Namespace Controller、Service Controller、Endpoints Controller、Persistent Controller、DaemonSet Controller等控制器。
2、分布式的工作节点
分布式的工作节点,工作节点运行业务应用容器;默认会运行三大核心组件:
-
Kubelet:与管理节点通信并触发指令执行,管理驱动网络,存储及容器运行时;
Kube Proxy:通过DNS实现服务发现,借助iptables规则引导访问至服务IP,并将重定向至正确的后端应用,实现高可用负载均衡能力;
Container Runtime:容器运行时。为了扩展Kubernetes平台适配能力,同时也标准化整个生态,通过CNI与CSI标准规范网络及存储的扩展;通过CRI与OCI标准规范容器镜像及容器运行时的扩展;目前CRI支持的容器运行时有docker、rkt、cri-o、frankti、kata-containers和clear-containers等。
3、辅助工具
辅助工具,主要是辅助集群管理及网络扩展:
-
kubectl通过API Server进行交互,实现集群管理的命令行工具;
Dashboard是Kubernetes的web用户管理监控界面;
Core DNS是可扩展的DNS服务器,实现集群服务发现能力。
二、Kubernetes核心理念
1、POD容器组,Kubernetes最小调度单元
Pod是Kubernetes的最小调度及资源分配单元,Pod之间相互隔离,通常情况一个Pod只建议运行一个容器,当某些容器之间关系非常紧密(Tightly coupled),可以运行在同一Pod运行多个容器方便一起调度管理。一个Pod就是一个应用运行实例,通过同时运行多个Pod来实现应用横向扩展能力。Pod本身没有自恢复能力,当调度或运行失败时,需要管理节点的Controller根绝配置触发实现Pod重启、重建或迁移等操作。
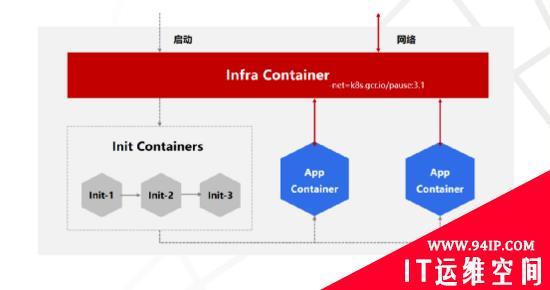 从Pod启动过程来看,Pod容器主要是Pause Container,Init Container以及App Container三种类型容器组成:
从Pod启动过程来看,Pod容器主要是Pause Container,Init Container以及App Container三种类型容器组成:
-
Pause Container:又叫Infra Container,Pod通过Pause Container实现Pod多个容器网络共享,Pause Container最先启动并绑定Pod唯一IP地址与各种网络资源,其他容器通过加入PauseContainer的Network namespace来实现网络共享。Pause是C语言实现,镜像非常小只有700KB左右,并且永远处于Pause(暂停)状态;官方镜像是gcr.io/google_containers/pause-amd64:3.0,同时也支持自定义。
Init Container:Pod中可以自定义一个或者多个Init Container,按照顺序依次启动,在应用Container之前启动并执行一些辅助任务,比如执行脚本、拷贝文件到共享目录、日志收集、应用监控等。将辅助功能与主业务容器解耦,实现独立发布和能力重用。除了不支持Readiness Probe,其他与特性与普通容器保持一致。
App Container:Pod真正承接业务的Container,一般情况会独立运行,如果是有微服务治理等需求会搭配Sidecar Container一起运行。在Init Container启动完成之后,App Container会并行启动,但是需要等待所有App Container处于就绪状态,整个Pod才算启动成功。
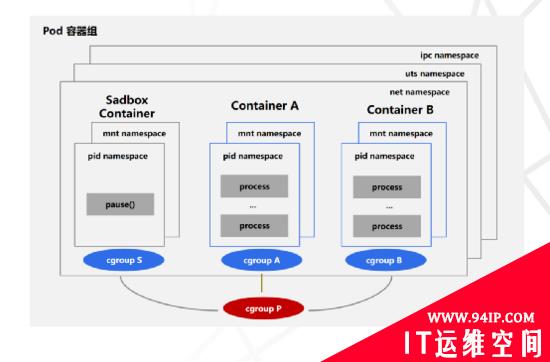 从POD的资源隔离来看,Pod容器主要由Linux提供的Namespace和Cgroup能力实现的,Namespace实现进程间隔离,Cgroup实现进程资源控制;其中Namespace由ipc 、uts 、net 、mnt 、pid 各种资源空间联合组成。
CRI是Kubernetes v1.5引入的,将Kubelet与容器运行时解耦;CRI中定义了容器和镜像的服务的接口,因为容器运行时与镜像的生命周期是彼此隔离的,所以定义了RuntimeService和ImageService两个服务,其中RuntimeService主要包含Sandbox和Container两种容器的管理gRPC接口,Sandbox就是上面Pod启动过程中提到的Pause容器。目前支持CRI的后端有cri-o,cri-containerd,rkt,frakti,docker等,cri-o是由redhat发起并开源且由社区驱动的container-runtime,轻量化专为kubernetes而生,主要目的就是替代docker作为kubernetes集群的容器运行时。
从POD的资源隔离来看,Pod容器主要由Linux提供的Namespace和Cgroup能力实现的,Namespace实现进程间隔离,Cgroup实现进程资源控制;其中Namespace由ipc 、uts 、net 、mnt 、pid 各种资源空间联合组成。
CRI是Kubernetes v1.5引入的,将Kubelet与容器运行时解耦;CRI中定义了容器和镜像的服务的接口,因为容器运行时与镜像的生命周期是彼此隔离的,所以定义了RuntimeService和ImageService两个服务,其中RuntimeService主要包含Sandbox和Container两种容器的管理gRPC接口,Sandbox就是上面Pod启动过程中提到的Pause容器。目前支持CRI的后端有cri-o,cri-containerd,rkt,frakti,docker等,cri-o是由redhat发起并开源且由社区驱动的container-runtime,轻量化专为kubernetes而生,主要目的就是替代docker作为kubernetes集群的容器运行时。
2、Volume存储卷,Kubernetes复杂的存储架构
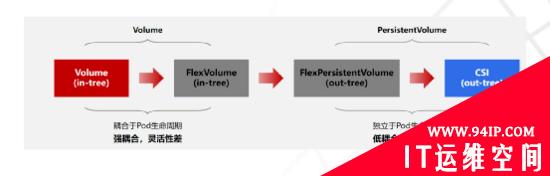 存储非常重要关键,同时也是生态与技术都比较复杂的领域,就linux、window两个生态支持的文件系统就多达20+。对于Kubernete存储架构设计一直在持续演进完善,为了尽可能多地兼容各种存储平台,Kubernetes以in-tree plugin的形式默认对接很多不同类型的存储系统;同时也支持基于FlexVolume和CSI插件以out-of-tree plugin来实现自定义存储服务。
对Kubernetes存储,主要有应用的基本配置文件读取、密码密钥管理;应用的存储状态、数据存取,不同应用间数据共享等三大使用场景。目前Kubernetes支持的Volume Plugins如下表:
存储非常重要关键,同时也是生态与技术都比较复杂的领域,就linux、window两个生态支持的文件系统就多达20+。对于Kubernete存储架构设计一直在持续演进完善,为了尽可能多地兼容各种存储平台,Kubernetes以in-tree plugin的形式默认对接很多不同类型的存储系统;同时也支持基于FlexVolume和CSI插件以out-of-tree plugin来实现自定义存储服务。
对Kubernetes存储,主要有应用的基本配置文件读取、密码密钥管理;应用的存储状态、数据存取,不同应用间数据共享等三大使用场景。目前Kubernetes支持的Volume Plugins如下表:
 Empty Dir:生命周期与Pod保持一致,当Pod删除后emptyDir中的数据也会被自动清除。当前emptyDir支持的类型有内存、大页内存、Node节点上Pod所在的文件系统。
Empty Dir:生命周期与Pod保持一致,当Pod删除后emptyDir中的数据也会被自动清除。当前emptyDir支持的类型有内存、大页内存、Node节点上Pod所在的文件系统。
-
ConfigMap:主要是承担配置中心,用于存储应用的配置数据,比如Springboot应用properties配置文件数据,但是空间大小限制在1MB内。
Secret:功能与ConfigMap类似,用于存储应用的敏感数据,比如数据密码、token、证书等,可以与ConfigMap联合使用,同样空间大小限制在1MB内。
HostPath:将Node节点本地文件系统路径映射到pod容器中使用。与emptyDir不同之处就是Pod删除后,HostPath中的数据Kubernetes根据用户的配置,可以不被清除。
In-tree网络存储:网络存储跟随Pod的生命周期,通过存储插件对接不同类型存储;其中FlexVolume虽然允许自定义开发驱动来挂载卷到集群Node节点上供Pod使用,但生命周期与pod同步。
PersistentVolumeClaim网络存储:具有独立的生命周期,可以通过存储的out-tree插件对接不同类型存储。当前支持的存储插件类型有FlexVolume与CSI。
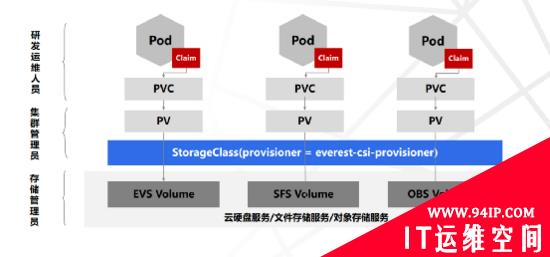 引入PV、PVC、StorageClass之后,资源管控更加灵活,团队职责更加明确,研发人员只需考虑存储需求(IO、容量、访问模式等),不需要关注底层存储细节;底层复杂的细节都由专业的集群管理与存储管理员来完成。
CSI是Kubernetes 1.9版本开始引入,建立一套标准的存储管理接口,通过该接口为容器提供存储服务。从而实现Kubernetes平台与存储服务驱动完全解耦。CSI主要包含CSI Controller Server与CSI Node Server两个部分,Controller Server主要实现创建、删除、挂载、卸载等控制功能;Node Server主要实现的是Node节点上的 mount、unmount的操作。
引入PV、PVC、StorageClass之后,资源管控更加灵活,团队职责更加明确,研发人员只需考虑存储需求(IO、容量、访问模式等),不需要关注底层存储细节;底层复杂的细节都由专业的集群管理与存储管理员来完成。
CSI是Kubernetes 1.9版本开始引入,建立一套标准的存储管理接口,通过该接口为容器提供存储服务。从而实现Kubernetes平台与存储服务驱动完全解耦。CSI主要包含CSI Controller Server与CSI Node Server两个部分,Controller Server主要实现创建、删除、挂载、卸载等控制功能;Node Server主要实现的是Node节点上的 mount、unmount的操作。
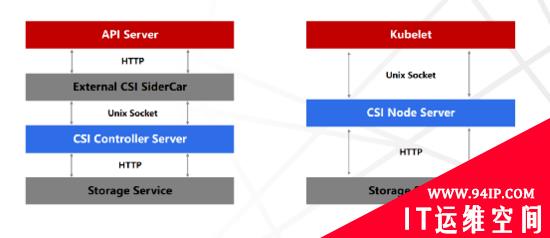 CSI Controller Server和External CSI SideCar是通过Unix Socket来进行通信的,CSI Node Server和Kubelet也是通过Unix Socket来通信。CSI实现类也日趋完善,比如ExpandCSIVolumes可以实现文件系统扩容;VolumeSnapshotDataSource可以实现数据卷的快照;VolumePVCDataSource实现自定义定PVC数据源;CSIInlineVolume在Volume中定义一些CSI的驱动。阿里云也开源了阿里云盘、NAS、CPFS、OSS、LVM等CSI存储插件。
CSI Controller Server和External CSI SideCar是通过Unix Socket来进行通信的,CSI Node Server和Kubelet也是通过Unix Socket来通信。CSI实现类也日趋完善,比如ExpandCSIVolumes可以实现文件系统扩容;VolumeSnapshotDataSource可以实现数据卷的快照;VolumePVCDataSource实现自定义定PVC数据源;CSIInlineVolume在Volume中定义一些CSI的驱动。阿里云也开源了阿里云盘、NAS、CPFS、OSS、LVM等CSI存储插件。
3、Ingress与Service,百花齐放的Kubernetes网络
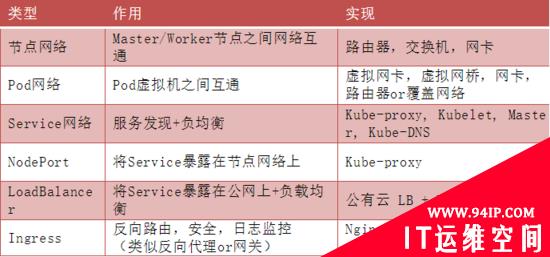
 Kubernetes 容器网络非常复杂,涉及的概念也比较多,比如Pod网络,Service网络,Cluster IP,NodePort,LoadBalancer和Ingress等,为此将Kubernetes 的网络参考TCP/IP协议栈抽象为四层:
第0层:Node节点网络比较简单,就是保证Kubernetes 节点(物理或虚拟机)之间能够正常IP寻址和互通的网络,一般由底层(公有云或数据中心)网络基础设施支持。
第1层:Pod是Kubernetes的最小调度单元,Pod网络就是确保Kubernetes集群中所有Pod(包括同一节点及不同节点上的Pod),逻辑上在同一个平面网络内,能够相互IP寻址和通信的网络。是容器网络最复杂部分,通过各种容器网络插件满足不同网络需求,通过CNI标准化及开放网络自定义能力。
第3层:虽然单个Pod都有IP,但是与Pod生命周期一致,为了解决一组相同Pod统一稳定的访问地址,并且将请求均衡的分发到后端Pod应用服务中。Kubernetes引入了Service网络,以此实现服务发现(Service Discovery)和负载均衡(Load Balancing)能力,底层是通过Kube-Proxy+iptables转发实现,对应用无侵入且不穿透代理,没有额外性能损耗。
第4层:Kubernetes Service网络是集群内部网络,集群外部是无法访问,需要将内部服务暴露外部才能访问。Kubernetes通过NodePort,LoadBalancer和Ingress多个方式构建外部网络接入能力。
Kubernetes 容器网络非常复杂,涉及的概念也比较多,比如Pod网络,Service网络,Cluster IP,NodePort,LoadBalancer和Ingress等,为此将Kubernetes 的网络参考TCP/IP协议栈抽象为四层:
第0层:Node节点网络比较简单,就是保证Kubernetes 节点(物理或虚拟机)之间能够正常IP寻址和互通的网络,一般由底层(公有云或数据中心)网络基础设施支持。
第1层:Pod是Kubernetes的最小调度单元,Pod网络就是确保Kubernetes集群中所有Pod(包括同一节点及不同节点上的Pod),逻辑上在同一个平面网络内,能够相互IP寻址和通信的网络。是容器网络最复杂部分,通过各种容器网络插件满足不同网络需求,通过CNI标准化及开放网络自定义能力。
第3层:虽然单个Pod都有IP,但是与Pod生命周期一致,为了解决一组相同Pod统一稳定的访问地址,并且将请求均衡的分发到后端Pod应用服务中。Kubernetes引入了Service网络,以此实现服务发现(Service Discovery)和负载均衡(Load Balancing)能力,底层是通过Kube-Proxy+iptables转发实现,对应用无侵入且不穿透代理,没有额外性能损耗。
第4层:Kubernetes Service网络是集群内部网络,集群外部是无法访问,需要将内部服务暴露外部才能访问。Kubernetes通过NodePort,LoadBalancer和Ingress多个方式构建外部网络接入能力。
 CNI最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。Container Runtime在创建容器时,先创建好network namespace,再调用CNI插件为network namespace配置网络,最后启动容器内进程。CNI插件包括CNI Plugin与IPAM Plugin两部分:
CNI最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。Container Runtime在创建容器时,先创建好network namespace,再调用CNI插件为network namespace配置网络,最后启动容器内进程。CNI插件包括CNI Plugin与IPAM Plugin两部分:
-
CNI Plugin:负责配置管理容器网络,包括两个基本的接口:
网络配置:AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)
清理网络:DelNetwork(net NetworkConfig, rt RuntimeConf) error
IPAM Plugin:负责容器IP地址分配,实现包括host-local和dhcp。
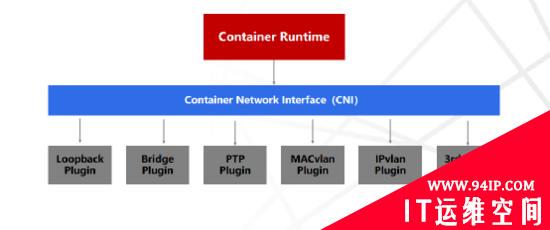 容器网络技术也在持续演进发展,社区开源的网络组件众多,比如Flannel、Calico、Cilium、OVN等,每个组件都有各自的优点及适应的场景,难以形成大一统的组件及解决方案。
容器网络技术也在持续演进发展,社区开源的网络组件众多,比如Flannel、Calico、Cilium、OVN等,每个组件都有各自的优点及适应的场景,难以形成大一统的组件及解决方案。
4、Workload工作负载,Kubernetes应用中心理念
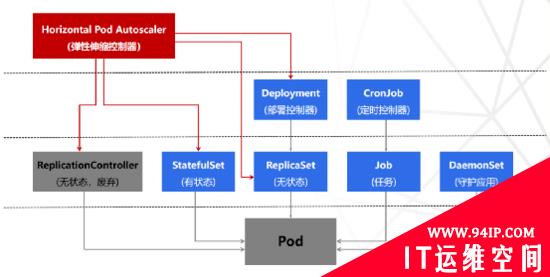 Kubernetes通过工作负载Workload实现应用管理部署与发布,践行Kubernetes以应用为中心的理念。Kubernetes支持多种类型的工作负载,包含Deployment、StatefulSet、ReplicaSet、Job、CronJob、DaemonSet,以满足不同场景的需求。
Kubernetes通过工作负载Workload实现应用管理部署与发布,践行Kubernetes以应用为中心的理念。Kubernetes支持多种类型的工作负载,包含Deployment、StatefulSet、ReplicaSet、Job、CronJob、DaemonSet,以满足不同场景的需求。
-
Deployment与ReplicaSet:替换原来的ReplicationController对象,管理部署无状态应用,Deployment管理不同版本的ReplicaSet,ReplicaSet管理相同版本的Pod,通过Deployment调整 ReplicaSet的终态副本数,控制器会维持实际运行的Pod数量与期望的数量一致,Pod 出故障时会自动重启或恢复。
StatefulSet:管理部署有状态应用,创建的Pod拥有根据规范创建的持久型标识符。Pod迁移或销毁重启后,标识符仍会保留。如每个Pod有序号,可以按序号创建更新或删除;Pod有唯一网络标志(hostname)或独享的存储PV,支持灰度发布等。
DaemonSet:管理部署每个节点运行的守护任务,如监控、日志收集等。新加入的节点也运行,移出节点是需要删除。也可以通过标签的指定运行节点。
Job与Cronjob:Job是一次性任务,可创建一个或多个Pod,监控Pod是否成功运行或终止;根据Pod状态设置重复次数、并发度、重启策略。Cronjob是定时调度的Job,可以指定运行时间、等待时间、是否并行运行、运行次数限制。
在Kubernetes生态中,还有一些提供额外操作的第三方工作负载,同时也可以通过使用CRD自定义工作负载,还有就是Device Plugin驱动的硬件工作负载。
5、Controller控制器,Kubernetes集控管理中心
Controller Manager作为Kubernetes集控管理中心,负责集群的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的资源管理,并通过API Server接口实时监控集群的每个资源对象的状态,一旦发生故障导致系统状态发生变化,就会立即尝试修复到“期望状态”。

-
Replication Controller:保证集群中一个RC所关联的Pod副本数始终保持预设值。
ResourceQuota Controller:确保Kubernetes中的资源对象在任何时候都不会超量占用系统物理资源。有容器,Pod以及Namespace三个级别。
Namespace Controller:通过API Server定时读取Namespace信息。如果Namespace被API标记为优雅删除(即设置删除期限,DeletionTimestamp),则将该Namespace状态设置为“Terminating”,并保存到etcd中。同时删除该Namespace下的ServiceAccount、RC、Pod等资源对象。
Endpoint Controller:Endpoints是Service对应所有Pod副本的访问地址,Endpoint Controller主要负责监听Service和对应的Pod副本的变化,从而生成和维护Endpoints对象控制器。
-
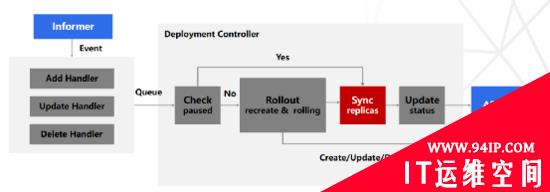
Deployment Controller:Deployment通过控制ReplicaSet,ReplicaSet再控制Pod,最终由Deployment Controller驱动达到期望状态,Deployment Controller会监听 DeploymentInformer、ReplicaSetInformer、PodInformer 三种资源。
另外,在Kubernetes v1.6引入了云控制管理器Cloud Controller Manager(CCM),提供与阿里公有云基础产品对接的支持。
三、总结
 总结一下,Kubernetes不仅是一个强大的容器编排系统本身,而且促进了一个庞大的工具和服务的生态系统,云原生时代的操作系统,形成云计算新界面。
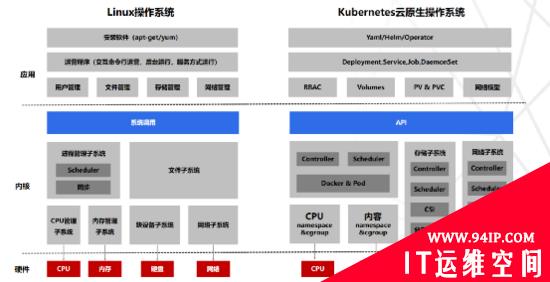
从设计理念方面,Kubernetes是以应用为中心的构理念,向下屏蔽基础设施差异,实现底层基础资源统一调度及编排;向上通过容器镜像标准化应用,实现应用负载自动化部署;中间通过Kubernetes通用的编排能力,开放API以及自定义CRD扩展能力;
从技术架构方面,Kubernetes是典型的分布式主从架构,由Master控制节点与可以水平扩展的Worker工作节点组成,Master实现集中式控制管理,Worker实现分布式运行;与Openstack的架构还有基于SpringCloud研发的分微服业务应用没有太大区别。
从设计模式方面,Kubernetes通过定义大量的模型(原语、资源对象、配置、常用的 CRD),通过配置管理模型实现集群资源的控制;虽然模型多切复杂,可以分层(核心层,隔离与服务访问层,调度层,资源层)逐步理解。
从平台扩展方面,Kubernetes是一个开放可扩展平台,不仅有开发的API,开放标准(CNI,CSI,CRI等)以及CRD,不仅是一个单纯运行时平台,同时面向运维的开发平台。
总结一下,Kubernetes不仅是一个强大的容器编排系统本身,而且促进了一个庞大的工具和服务的生态系统,云原生时代的操作系统,形成云计算新界面。
从设计理念方面,Kubernetes是以应用为中心的构理念,向下屏蔽基础设施差异,实现底层基础资源统一调度及编排;向上通过容器镜像标准化应用,实现应用负载自动化部署;中间通过Kubernetes通用的编排能力,开放API以及自定义CRD扩展能力;
从技术架构方面,Kubernetes是典型的分布式主从架构,由Master控制节点与可以水平扩展的Worker工作节点组成,Master实现集中式控制管理,Worker实现分布式运行;与Openstack的架构还有基于SpringCloud研发的分微服业务应用没有太大区别。
从设计模式方面,Kubernetes通过定义大量的模型(原语、资源对象、配置、常用的 CRD),通过配置管理模型实现集群资源的控制;虽然模型多切复杂,可以分层(核心层,隔离与服务访问层,调度层,资源层)逐步理解。
从平台扩展方面,Kubernetes是一个开放可扩展平台,不仅有开发的API,开放标准(CNI,CSI,CRI等)以及CRD,不仅是一个单纯运行时平台,同时面向运维的开发平台。
转载请注明:IT运维空间 » 运维技术 » 运维入坑必看:Kubernetes平台架构解读
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-
oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/7.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论