

随着大量云原生技术的应用,IT系统日益复杂,主动感知、预测故障并迅速定位、排障的难度变得越来越大,传统监控方式已无法跟上需求,由此应运而生的可观测性,被视为未来云环境生产部署不可或缺的技术支撑。
 目前大多数传统企业对可观测性仍处于初步了解阶段,不少互联网公司在可观测性建设上也是起步不久。因此,围绕“从监控到可观测性应如何转变与升级”这一话题,本期dbaplus话题接力专栏,特别采访到知乎全链路可观测系统和接入层网络负责人-熊豹、虎牙直播SRE平台研发团队负责人-匡凌轩、好大夫基础架构部高级工程师-方勇三位老师,希望能通过他们在可观测性领域的研究心得和实践经验,帮助广大技术从业者准确认识可观测性、给企业搭建适配自身发展的可观测体系提供建议和启发。
目前大多数传统企业对可观测性仍处于初步了解阶段,不少互联网公司在可观测性建设上也是起步不久。因此,围绕“从监控到可观测性应如何转变与升级”这一话题,本期dbaplus话题接力专栏,特别采访到知乎全链路可观测系统和接入层网络负责人-熊豹、虎牙直播SRE平台研发团队负责人-匡凌轩、好大夫基础架构部高级工程师-方勇三位老师,希望能通过他们在可观测性领域的研究心得和实践经验,帮助广大技术从业者准确认识可观测性、给企业搭建适配自身发展的可观测体系提供建议和启发。
Q1监控与可观测性是什么关系?有什么区别?可否从两者的关注点、应用场景、作用、局限性等方面进行解析?
熊豹
“正在发生什么 与 为什么会这样”
监控是常见的运维手段,一般是指以观测系统的外部资源使用情况和接口表现来推测系统运行状态,即感知到“正在发生什么”。 可观测性是一种属性,是指在可以感知系统当前运行状态的性质,提升系统的可被观测的性质有助于我们了解“正在发生什么”以及“为什么会这样”。 云原生架构在业内逐步落地,给稳定性建设带来了更多新的挑战:迭代发布更迅速、业务系统更庞大、网络链路更复杂、运行环境更动态。在这样的混沌系统中仅仅只是知道问题发生是不够的,在这样纷繁复杂的环境下赤手空拳的我们很难去进行问题的追踪和溯源。我们要依托分层、多维度的观测数据来构建更立体和智能的诊断系统,以更多样的视角来观察和解读系统。
匡凌轩
“可观测性更多是对业务应用系统自身的要求”
我认为监控是可观测性能力的一部分,初期监控主要是外部对业务应用系统的主动行为,运维是传统监控的使用主体,如:通过业务进程状态、系统资源等监控数据的分析和告警来发现问题。而现在可观测性更多是对业务应用系统自身的要求,如何设计去暴露出更多可被观测的应用运行时的数据,并为这些数据之间建立关联,如:微服务框架在请求处理和RPC调用时提供一些AOP扩展的设计,可以更方便地对请求进行Metric度量和Trace追踪,以及异常情况的上下文关联。
方勇
“从局部到全局可用性视角的延伸”
两者的关系:监控和可观测性都旨在辅助建设高可用的服务,缩短故障处理时长,两者往往是密切协作的,界限相对模糊。 两者的区别:监控往往关注告警触发的瞬时状态,一般围绕告警事件展开,涉及从告警事件的产生到应急响应等一系列动作。关注的视角一般是局部可用性,关注每个具体的监控项,如CPU负载、剩余内存等。监控是个老生常谈的话题,最常见的场景是系统资源监控、进程或服务状态的粗粒度监控。对定制化的业务指标监控不太友好,另外传统的监控体系对云原生的支持、对微服务体系监控的支持也不太友好。 可观测性可以看作是监控的一种延续,涉及面较广,包括全链路分析(APM)、业务服务质量(SLA)、业务容量等,聚焦服务的整体可用性。关注的视角一般是全局可用性,会忽略不影响服务质量的一些指标,如CPU负载高,服务整体时延波动不大就会忽略这个CPU负载指标。 可观测性的应用场景一般与业务能力相绑定,通过可视化聚合展示影响SLA的相关指标(SLI),再配合监控告警,通过可观测性看板下钻分析异常根因。另外可观测性打通Metrics/Traces/Logs后可主动识别出服务的潜在风险,能先于用户发现问题。 可观测性也有所局限,由于需要收集业务数据,对业务具有一定的侵入性,加上打造可视化平台投入成本较高。另外可观测性整体处于初期阶段,很多工具链还不太完善,价值预期其实是被高估了。 Q2从监控到可观测性都有哪些变化?对运维、开发、架构师等岗位人员分别提出了怎样的新要求?
熊豹
“要把可观测性理念贯穿到架构和程序设计中”
目标不一样了,除了要知道“正在发生什么”,还要尝试解释“为什么会这样”。我们需要把可观测性的理念贯穿到架构和程序设计中,而不是到事发或事后再来补救。我们需要有意识地设计一些机制来观察业务指标的关联变化、系统架构的数据漏斗模型、程序内逻辑分支的运行开销、外部资源依赖的健康状态,还要暴露程序内的一些资源并发度、池的填充率和命中率、运行时的状态等情况,当运行错误时也要在错误信息中携带足量的上下文信息。 运维同学要为可观测场景提供更坚实的工具基础,在上述庞大的数据压力下,保障和解决数据存储和查询的性能、资源开销、集群的拓展性和稳定性等问题。
匡凌轩
“从被动监控向主动发现与定位问题的转变”
我认为最大的变化是应用系统自身角色的转变,从被动监控转向主动发现与定位问题,在设计应用系统架构之初就需要考虑到系统自身的可观测性建设。运维、开发、架构师都是各环节设计的参与者,在协作方式也有一定的改变:
-
运维:深入熟悉产品业务和应用服务,定义并关联业务指标、应用服务指标、系统资源指标等。
开发:在框架层设计和实现对分布式应用服务运行时的Metric、Trace、Log数据采集。
架构师:业务应用系统和可观测性系统的整体架构设计,需要关注无侵入式采集上报、多维度量聚合、错误寻根分析、整体海量数据处理和存储等。
总体来说,需要各角色有更多跨技术领域的知识储备、业务思维和模型抽象能力。
方勇
“职责分工、认知意识、排障效率的转变和升级”
个人认为主要变化有以下几个方面:
-
职责分工的转变,研发关注服务质量后,部分职责从运维侧开始迁移到研发侧。研发上线后不再当甩手掌柜,开始对自己的服务负责。
认知意识的提高,从被动响应告警到主动提升服务质量。
排障效率的提升,从原先的黑盒排障模式逐渐朝可视化发展。
对不同岗位人员也有新的要求:
-
运维,需要摆脱传统监控的意识枷锁,拥抱云原生监控体系,同时和其他岗位人员达成共识,共建高可用服务。
开发,接棒部分运维职责,聚焦服务可用性,需要有MDD(Metrics-Driven Developmen)的思想,建设具有高韧性的服务。
架构师,在架构设计的过程中需要暴露可观测性的指标,同时需要提升数据分析的能力,建模分析Metrics/Traces/Logs数据,识别服务中潜在的风险。围绕可观测性打造相应的工具链及服务治理平台。
Q3可观测性的核心方法论/关键技术有哪些?
熊豹
“数据的采集、存储、分析是核心关注点”
可观测性建设的核心关注点还是在数据的采集、存储、分析环节。 数据采集的覆盖可以以多种角度来看:可尝试梳理完整的数据链路,来覆盖从终端发起、网关、业务、基础设施中间的每一层组件;可以不同的观测视角进行覆盖,比如Metrics、Traces、Logs、Exception Collection、Profiler、Debuger、Changelog等类别的数据或能力都已建设齐备;可以多种维度来观察系统,比如业务维度、资源瓶颈、关联组件等维度进行覆盖的建设。 数据存储环节要关注多种类型数据的存储和查询系统选型。最为常见的是Metrics、Traces、Logs相关的存储系统,这三者都有非常广泛的基础软件选型。其中相对棘手的是指标维度爆炸、日志和Trace存储成本及性能相关的问题,一般需要搭配预聚合、前采样和后采样、存储分级等策略来解决。 数据分析环节要关联不同数据源的元信息,糅合以多维视角来构建查询界面。同时,我们也要关注如何在海量的原始数据中找到一些突出和异常的数据,一般需要建设一些流式检测和聚类分析的能力。
匡凌轩
“采集数据,建立关联,设计模型”
可观测性的核心思考:需要采集什么数据、如何建立关联、如何设计模型,我们以应用服务场景为例:
-
采集:请求量、耗时、错误和容量等,以及线程池、队列、连接池等资源指标。
关联:纵向关联请求上下游链路和调用栈,横向关联请求和处理请求所消耗的应用资源。
模型:数据采集和关联、异常定义和分析、全链路错误寻根三方面统一的模型化设计。
以上可指导我们针对不同的业务应用系统进行合理抽象,建设更标准的可观测性能力。
方勇
“MDD思想主张指标驱动开发”
常用方法论: 1、SLI选择:
-
参考Google VALET(Volume、Available、Latency、Error、Ticket)模型。
Netflix的USE方法,USE是Utilization(使用率)、Saturation(饱和度)、Error(错误)。
Weave Cloud的RED方法,Request-Rate(每秒接收的请求数)/Request-Errors(每秒失败的请求数)/Request-Duration(每个请求所花费的时间,用时间间隔表示)。
2、MDD(Metrics-Driven Development)思想:MDD主张整个应用开发过程由指标驱动,通过实时指标来驱动快速、精确和细粒度的软件迭代。指标驱动开发的理念,不但可以让程序员实时感知生产状态,及时定位并终结问题,还可以帮助产品经理和运维人员一起关注相关的业务指标。 关键技术: 1、数据收集:如果是基于Prometheus生态,有丰富的Exporte可用,还可以自研相应的Exporter。如果基于文件日志收集,可考虑Flume、Fluentd等等。 2、数据分析:可基于Clickhouse SQL分析提炼日志指标,如果是Prometheus体系,也有丰富的PromQL可用来分析相关指标。针对Traces、Logs分析一般采用自研分析引擎,并与Metrics打通。 3、数据存储:Prometheus本身就是一款很好的时序数据库,但不支持分布式存储。一般采用远程存储引擎搭配使用,常用Clickhouse、InfluxDB等。Traces和Logs一般可采用Elasticsearch存储。 4、数据展示:数据最终呈现形式,需要契合可视化设计规划,支持上卷/下钻。大部分需求可采用Grafana呈现,Grafana提供了丰富的插件,支持丰富的数据库类型,也可基于Echarts自研。如果托管公有云,可充分利用公有云自有的体系,不过有些需要单独付费。
Q4如何将Metrics、Traces、Logs三者打通并发挥最大价值?
熊豹
“基于时间范围内的统计关系或Label和TraceID关联”
我们已知的有两类方式: 1、基于时间范围内的统计关系:一般的使用习惯是在Metric异常的时间区间里去找到对应时间区间出现异常行为的Traces和Logs,这种方式会依赖对Traces和Logs的聚类分析能力。 2、基于Label和TraceID关联:基于OpenTelemetry Collector可观测数据采集的框架,我们可以以插件的形式、以Trace Span元数据Label来生成访问指标,也同时将TraceID携带记录到日志的元信息中,这样就能以同样的TraceID或Label维度进行关联查看了。另外当前Prometheus实现了一个exemplar特性可以将Metric与TraceID关联存储,这个设计也挺有意思的。
匡凌轩
“全链路错误寻根是三者打通的最大价值”
三者打通最大的价值是能做到全链路错误寻根,即从发现请求Metric指标异常,通过指标关联分析,并逐层下钻到明细Trace追踪和具体Error Log,全流程自动化从宏观到明细的错误发现和根因定位。 虎牙为三者统一设计了应用监控模型,包括应用服务的透明零成本SDK接入,三者数据自动采集和关联,以及在虎牙大型分布式系统充分实践的全链路错误寻根算法。就整体实践经验来说,最终业务价值在于帮助研发和运维提高了应用服务的排障和治理效率。
方勇
“打通后可立体、全息分析整个服务的可用性”
从投入成本(CapEx)、运维成本(OpEx)、响应能力(Reaction)、查问题的有效程度(Investigation)几个方面分析。Metrics、Logs、Traces具有以下特征:
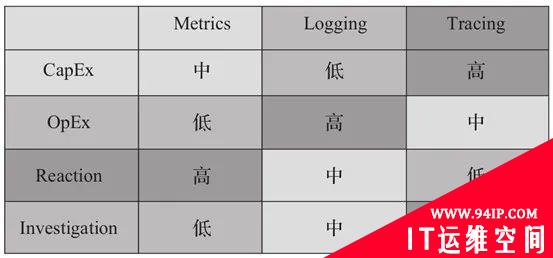 Logs和Traces一般采用trace_id打通,trace_id一般在端入口生成,贯穿整个请求的生命周期,业务记录Logs的时候可记录当前的trace_id,这样Logs和Traces就能打通了。
与Metrics打通一般是采用标签Tags模式,如某个服务servername产生的metrics可与Traces中的servername关联。
打通后可以服务名的维度,立体、全息分析整个服务的可用性。
Logs和Traces一般采用trace_id打通,trace_id一般在端入口生成,贯穿整个请求的生命周期,业务记录Logs的时候可记录当前的trace_id,这样Logs和Traces就能打通了。
与Metrics打通一般是采用标签Tags模式,如某个服务servername产生的metrics可与Traces中的servername关联。
打通后可以服务名的维度,立体、全息分析整个服务的可用性。
Q5可观测性工具如何选型?有通用的标准吗?
熊豹
“高可用、可伸缩、降成本、易运维”
我们关注可观测工具系统的这些特性:
-
高可用:可观测系统作为稳定性的守卫者,本身要求更高的可靠性。
可伸缩:我们关注存储写入和查询能力的可拓展性,以支持更大的数据量级。
降成本:观测类数据会随着时间的推移逐渐失去价值,历史数据最好能低成本地失效或能对存储介质进行降级。
易运维:拥有一定的自动化能力或者本身架构足够简单。
匡凌轩
“是否基于业界标准且方便扩展”
虎牙主要是基于OpenTracing标准进行的深度自研和扩展,通过业界标准来做会有充分的开源代码和社区支持,可以节省很多基础代码的工作,让我们更关注自身的业务系统特性和模型设计。现在OpenTelemetry对Metrics、Traces、Logs三者提供了统一标准,开源社区热度也比较大,是个值得去研究和实践的方向。 可观测性工具选型建议可考虑两个方面:
是否基于业界标准,有更多社区和厂商支持。 是否方便扩展,更容易把共性和个性结合,最终在此基础上建设符合自身业务特性的可观测性系统。方勇
“根据已有技术栈按需选择,不必盲从主流”
可观测性分析整个技术栈可参考如下图:
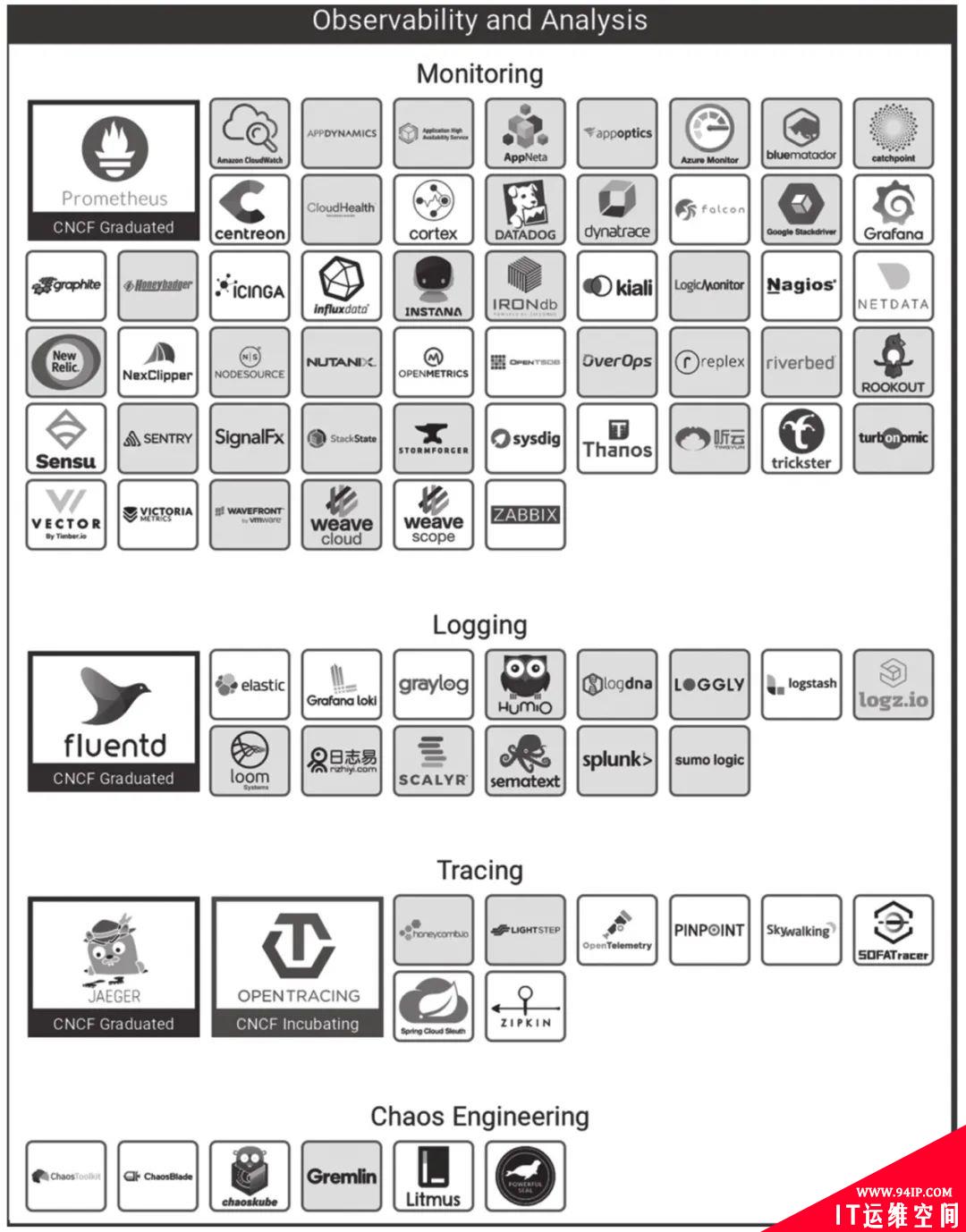 工具选型:
工具选型:
-
Metrics:常用Zabbix、Nagios、Prometheus,及相关高可用部署方案如Prometheus-operator、Thanos。
Logging:ELK Stack、Fluentd、Loki等。
Traceing:常用Jaeger、SkyWalking、Pinpoint、Zipkin、Spring Cloud Sleuth等。
可视化:Grafana。
其实技术选型没什么特定的标准,每个企业不同阶段可能有不同的选择,适合自己的才是最好的,这里总结几点心得:
-
控制成本预算,企业一般需要从自身的发展阶段实际情况考虑,不必一上来就整全链路可观测性,也许初期只用传统的Zabbix就满足需求了。理性按需选择,大可不必盲从主流。
拥抱开源,初期一般采用开源产品,开箱即用,搭顺风车。另外,选型时还需要考虑周边生态的丰富度。
根据团队技术栈选择,中间件、业务服务、云原生、物理机监控等选型都要贴合团队已有的技术栈。
转载请注明:IT运维空间 » 运维技术 » 从监控到可观测性,设计思想、技术选型、职责分工都有哪些变化
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/10.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论