

什么是分布式锁?分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。

图片来自 Pexels
如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
为什么要使用分布式锁
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行。
在传统单体应用单机部署的情况下,可以使用 Java 并发处理相关的 API(如 ReentrantLock 或 Synchronized)进行互斥控制;在单机环境中,Java 中提供了很多并发处理相关的 API。
但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的 Java API 并不能提供分布式锁的能力。
为了解决这个问题就需要一种跨 JVM 的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
举个例子:机器 A,机器 B 是一个集群。A,B 两台机器上的程序都是一样的,具备高可用性能。
A,B 机器都有一个定时任务,每天晚上凌晨 2 点需要执行一个定时任务,但是这个定时任务只能执行一遍,否则的话就会报错。
那 A,B 两台机器在执行的时候,就需要抢锁,谁抢到锁,谁执行,谁抢不到,就不用执行了!
锁的处理
锁的处理方式如下:
- 单个应用中使用锁:(单进程多线程)Synchronize。
- 分布式锁控制分布式系统之间同步访问资源的一种方式。
- 分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
分布式锁的实现
分布式锁的实现方式如下:
- 基于数据的乐观锁实现分布式锁
- 基于 Zookeeper 临时节点的分布式锁
- 基于 Redis 的分布式锁
Redis 的分布式锁
获取锁
在 set 命令中,有很多选项可以用来修改命令的行为,以下是 set 命令可用选项的基本语法:
redis127.0.0.1:6379>SETKEYVALUE[EXseconds][PXmilliseconds][NX|XX] -EXseconds设置指定的到期时间(单位为秒) -PXmilliseconds设置指定的到期时间(单位毫秒) -NX:仅在键不存在时设置键 -XX:只有在键已存在时设置
方式 1:推介
privatestaticfinalStringLOCK_SUCCESS="OK";
privatestaticfinalStringSET_IF_NOT_EXIST="NX";
privatestaticfinalStringSET_WITH_EXPIRE_TIME="PX";
ublicstaticbooleangetLock(JedisClusterjedisCluster,StringlockKey,StringrequestId,intexpireTime){
//NX:保证互斥性
Stringresult=jedisCluster.set(lockKey,requestId,SET_IF_NOT_EXIST,SET_WITH_EXPIRE_TIME,expireTime);
if(LOCK_SUCCESS.equals(result)){
returntrue;
}
returnfalse;
}
方式 2:
publicstaticbooleangetLock(StringlockKey,StringrequestId,intexpireTime){
Longresult=jedis.setnx(lockKey,requestId);
if(result==1){
jedis.expire(lockKey,expireTime);
returntrue;
}
returnfalse;
}
注意:推介方式 1,因为方式 2 中 setnx 和 expire 是两个操作,并不是一个原子操作,如果 setnx 出现问题,就是出现死锁的情况,所以推荐方式 1。
释放锁
方式 1:del 命令实现
publicstaticvoidreleaseLock(StringlockKey,StringrequestId){
if(requestId.equals(jedis.get(lockKey))){
jedis.del(lockKey);
}
}
方式 2:Redis+Lua 脚本实现(推荐)
publicstaticbooleanreleaseLock(StringlockKey,StringrequestId){
Stringscript="ifredis.call('get',KEYS[1])==ARGV[1]thenreturn
redis.call('del',KEYS[1])elsereturn0end";
Objectresult=jedis.eval(script,Collections.singletonList(lockKey),
Collections.singletonList(requestId));
if(result.equals(1L)){
returntrue;
}
returnfalse;
}
Zookeeper 的分布式锁
Zookeeper 分布式锁实现原理
理解了锁的原理后,就会发现,Zookeeper 天生就是一副分布式锁的胚子。
首先,Zookeeper 的每一个节点,都是一个天然的顺序发号器。
在每一个节点下面创建子节点时,只要选择的创建类型是有序(EPHEMERAL_SEQUENTIAL 临时有序或者 PERSISTENT_SEQUENTIAL 永久有序)类型,那么,新的子节点后面,会加上一个次序编号。
这个次序编号,是上一个生成的次序编号加 1,比如,创建一个用于发号的节点“/test/lock”,然后以他为父亲节点,在这个父节点下面创建相同前缀的子节点。
假定相同的前缀为“/test/lock/seq-”,在创建子节点时,同时指明是有序类型。
如果是第一个创建的子节点,那么生成的子节点为 /test/lock/seq-0000000000,下一个节点则为 /test/lock/seq-0000000001,依次类推,等等。
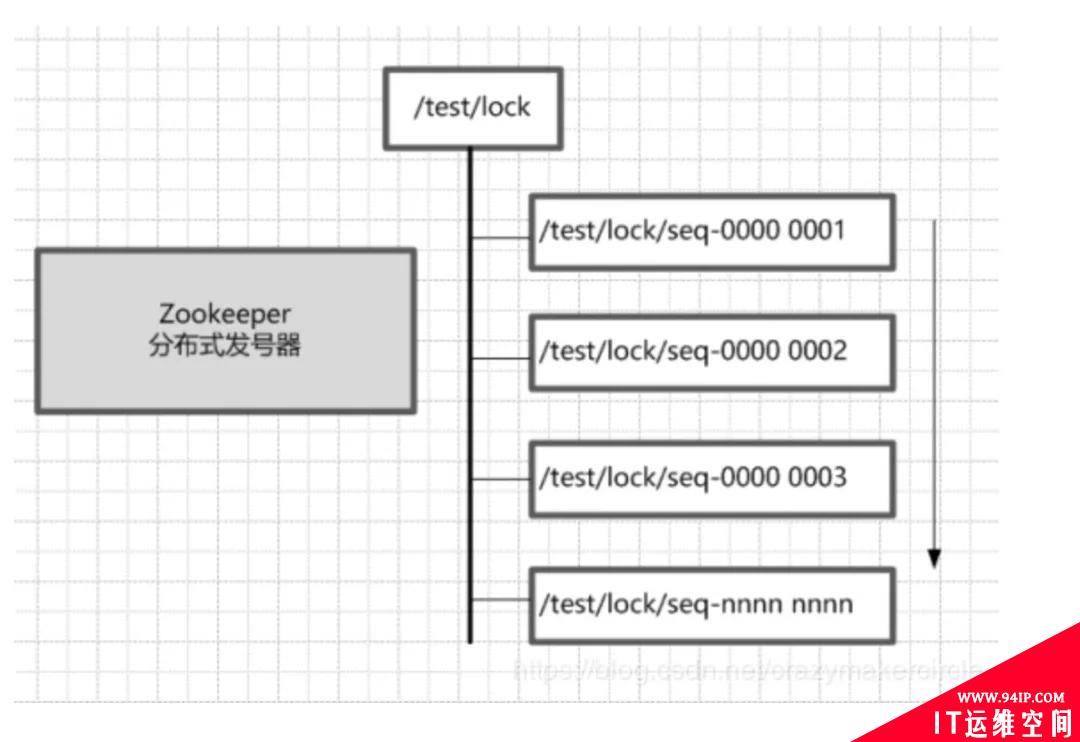
其次,Zookeeper 节点的递增性,可以规定节点编号最小的那个获得锁。
一个 Zookeeper 分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT 类型),然后每个要获得锁的线程都会在这个节点下创建个临时顺序节点,由于序号的递增性,可以规定排号最小的那个获得锁。
所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
第三,Zookeeper 的节点监听机制,可以保障占有锁的方式有序而且高效。
每个线程抢占锁之前,先抢号创建自己的 ZNode。同样,释放锁的时候,就需要删除抢号的 Znode。
抢号成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个 Znode 的通知就可以了。
当前一个 Znode 删除的时候,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。
Zookeeper 的节点监听机制,可以说能够非常完美的,实现这种击鼓传花似的信息传递。
具体的方法是,每一个等通知的 Znode 节点,只需要监听 linsten 或者 watch 监视排号在自己前面那个,而且紧挨在自己前面的那个节点。
只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,则获得锁。
为什么说 Zookeeper 的节点监听机制,可以说是非常完美呢?
一条龙式的首尾相接,后面监视前面,就不怕中间截断吗?比如,在分布式环境下,由于网络的原因,或者服务器挂了或者其他的原因,如果前面的那个节点没能被程序删除成功,后面的节点不就永远等待么?
其实,Zookeeper 的内部机制,能保证后面的节点能够正常的监听到删除和获得锁。
在创建取号节点的时候,尽量创建临时 Znode 节点而不是永久 Znode 节点。
一旦这个 Znode 的客户端与 Zookeeper 集群服务器失去联系,这个临时 Znode 也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。
说 Zookeeper 的节点监听机制,是非常完美的。还有一个原因。Zookeeper 这种首尾相接,后面监听前面的方式,可以避免羊群效应。
所谓羊群效应就是每个节点挂掉,所有节点都去监听,然后做出反映,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反映。
Zookeeper 分布式锁实现示例
Zookeeper 是通过临时节点来实现分布式锁:
terruptedExceptione){
e.printStackTrace();
}
System.out.println("*********业务方法结束************\n");
}
//这里使用@Test会报错
publicstaticvoidmain(String[]args){
//定义重试的侧策略1000等待的时间(毫秒)10重试的次数
RetryPolicypolicy=newExponentialBackoffRetry(1000,10);
//定义zookeeper的客户端
CuratorFrameworkclient=CuratorFrameworkFactory.builder()
.connectString("10.231.128.95:2181,10.231.128.96:2181,10.231.128.97:2181")
.retryPolicy(policy)
.build();
//启动客户端
client.start();
//在zookeeper中定义一把锁
finalInterProcessMutexlock=newInterProcessMutex(client,"/mylock");
//启动是个线程
for(inti=0;i<10;i++){
newThread(newRunnable(){
@Override
publicvoidrun(){
try{
//请求得到的锁
lock.acquire();
printNumber();
}catch(Exceptione){
e.printStackTrace();
}finally{
//释放锁
try{
lock.release();
}catch(Exceptione){
e.printStackTrace();
}
}
}
}).start();
}
}
}
基于数据的分布式锁
我们在讨论使用分布式锁的时候往往首先排除掉基于数据库的方案,本能的会觉得这个方案不够“高级”。
从性能的角度考虑,基于数据库的方案性能确实不够优异,整体性能对比:缓存>Zookeeper、etcd>数据库。
也有人提出基于数据库的方案问题很多,不太可靠。数据库的方案可能并不适合于频繁写入的操作。
下面我们来了解一下基于数据库(MySQL)的方案,一般分为三类:
- 基于表记录
- 乐观锁
- 悲观锁
基于表记录
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们想要获得锁的时候,就可以在该表中增加一条记录,想要释放锁的时候就删除这条记录。
为了更好的演示,我们先创建一张数据库表,参考如下:
CREATETABLE`database_lock`( `id`BIGINTNOTNULLAUTO_INCREMENT, `resource`intNOTNULLCOMMENT'锁定的资源', `description`varchar(1024)NOTNULLDEFAULT""COMMENT'描述', PRIMARYKEY(`id`), UNIQUEKEY`uiq_idx_resource`(`resource`) )ENGINE=InnoDBDEFAULTCHARSET=utf8mb4COMMENT='数据库分布式锁表';
①获得锁
我们可以插入一条数据:
INSERTINTOdatabase_lock(resource,description)VALUES(1,'lock');
因为表 database_lock 中 resource 是唯一索引,所以其他请求提交到数据库,就会报错,并不会插入成功,只有一个可以插入。插入成功,我们就获取到锁。
②删除锁
INSERTINTOdatabase_lock(resource,description)VALUES(1,'lock');
这种实现方式非常的简单,但是需要注意以下几点:
①这种锁没有失效时间,一旦释放锁的操作失败就会导致锁记录一直在数据库中,其他线程无法获得锁。这个缺陷也很好解决,比如可以做一个定时任务去定时清理。
②这种锁的可靠性依赖于数据库。建议设置备库,避免单点,进一步提高可靠性。
③这种锁是非阻塞的,因为插入数据失败之后会直接报错,想要获得锁就需要再次操作。
如果需要阻塞式的,可以弄个 for 循环、while 循环之类的,直至 INSERT 成功再返回。
④这种锁也是非可重入的,因为同一个线程在没有释放锁之前无法再次获得锁,因为数据库中已经存在同一份记录了。
想要实现可重入锁,可以在数据库中添加一些字段,比如获得锁的主机信息、线程信息等。
那么在再次获得锁的时候可以先查询数据,如果当前的主机信息和线程信息等能被查到的话,可以直接把锁分配给它。
乐观锁
顾名思义,系统认为数据的更新在大多数情况下是不会产生冲突的,只在数据库更新操作提交的时候才对数据作冲突检测。如果检测的结果出现了与预期数据不一致的情况,则返回失败信息。
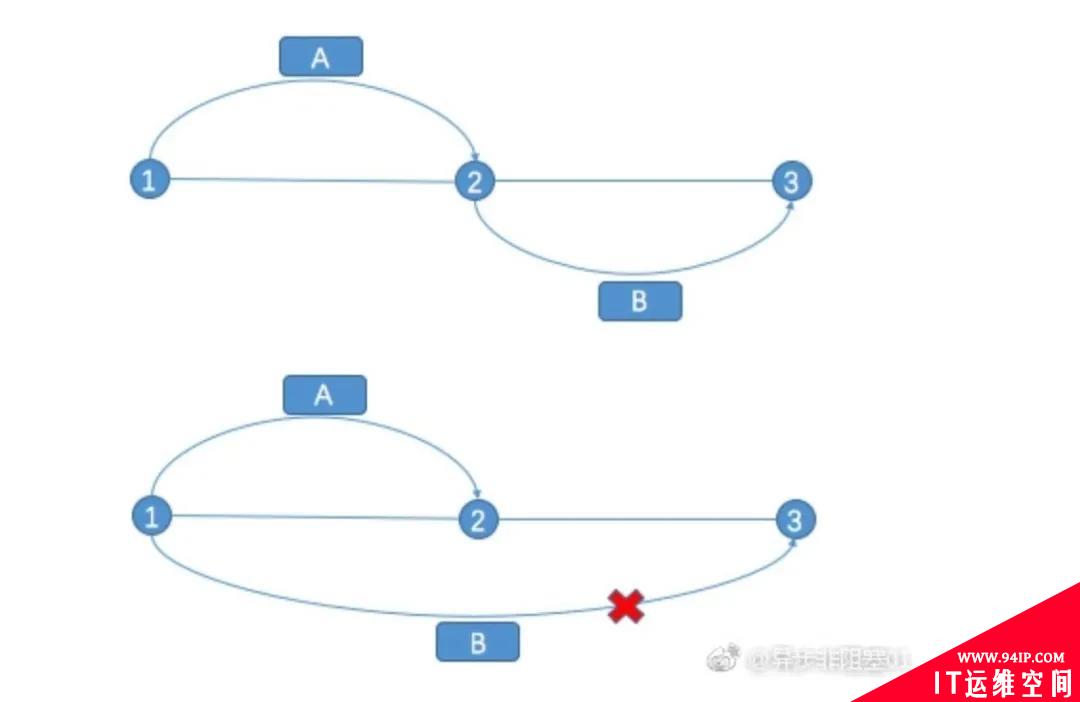
乐观锁大多数是基于数据版本(version)的记录机制实现的。何谓数据版本号?
即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个 “version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加 1。
在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。
为了更好的理解数据库乐观锁在实际项目中的使用,这里也就举了业界老生常谈的库存例子。
一个电商平台都会存在商品的库存,当用户进行购买的时候就会对库存进行操作(库存减 1 代表已经卖出了一件)。
如果只是一个用户进行操作数据库本身就能保证用户操作的正确性,而在并发的情况下就会产生一些意想不到的问题。
比如两个用户同时购买一件商品,在数据库层面实际操作应该是库存进行减 2 操作。
但是由于高并发的情况,第一个用户购买完成进行数据读取当前库存并进行减 1 操作,由于这个操作没有完全执行完成。
第二个用户就进入购买相同商品,此时查询出的库存可能是未减 1 操作的库存导致了脏数据的出现【线程不安全操作】。
数据库乐观锁也能保证线程安全,通常代码层面我们都会这样做:
selectgoods_numfromgoodswheregoods_name="小本子"; updategoodssetgoods_num=goods_num-1wheregoods_name="小本子";
上面的 SQL 是一组的,通常先查询出当前的 goods_num,然后再 goods_num 上进行减 1 的操作修改库存。
当并发的情况下,这条语句可能导致原本库存为 3 的一个商品经过两个人购买还剩下 2 库存的情况就会导致商品的多卖。那么数据库乐观锁是如何实现的呢?
首先定义一个 version 字段用来当作一个版本号,每次的操作就会变成这样:
selectgoods_num,versionfromgoodswheregoods_name="小本子"; updategoodssetgoods_num=goods_num-1,version=查询的version值自增wheregoods_name="小本子"andversion=查询出来的version;
其实,借助更新时间戳(updated_at)也可以实现乐观锁,和采用 version 字段的方式相似。
更新操作执行前线获取记录当前的更新时间,在提交更新时,检测当前更新时间是否与更新开始时获取的更新时间戳相等。
悲观锁
除了可以通过增删操作数据库表中的记录以外,我们还可以借助数据库中自带的锁来实现分布式锁。
在查询语句后面增加 FOR UPDATE,数据库会在查询过程中给数据库表增加悲观锁,也称排他锁。当某条记录被加上悲观锁之后,其它线程也就无法再改行上增加悲观锁。
悲观锁,与乐观锁相反,总是假设最坏的情况,它认为数据的更新在大多数情况下是会产生冲突的。
在使用悲观锁的同时,我们需要注意一下锁的级别。MySQL InnoDB 引起在加锁的时候,只有明确地指定主键(或索引)的才会执行行锁 (只锁住被选取的数据),否则 MySQL 将会执行表锁(将整个数据表单给锁住)。
在使用悲观锁时,我们必须关闭 MySQL 数据库的自动提交属性(参考下面的示例),因为 MySQL 默认使用 autocommit 模式。
也就是说,当你执行一个更新操作后,MySQL 会立刻将结果进行提交。
mysql>SETAUTOCOMMIT=0; QueryOK,0rowsaffected(0.00sec)
这样在使用 FOR UPDATE 获得锁之后可以执行相应的业务逻辑,执行完之后再使用 COMMIT 来释放锁。
我们不妨沿用前面的 database_lock 表来具体表述一下用法。假设有一线程A需要获得锁并执行相应的操作。
那么它的具体步骤如下:
STEP1-获取锁:SELECT*FROMdatabase_lockWHEREid=1FORUPDATE;。 STEP2-执行业务逻辑。 STEP3-释放锁:COMMIT。
作者:凌晶
简介:生活中的段子手,目前就职于一家地产公司做 DevOPS 相关工作, 曾在大型互联网公司做高级运维工程师,熟悉 Linux 运维,Python 运维开发,Java 开发,DevOPS 常用开发组件等,个人公众号:stromling,欢迎来撩我哦!

转载请注明:IT运维空间 » 运维技术 » 为什么Zookeeper天生就是一副分布式锁的胚子?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com./zb_users/theme/ydconcise/include/random/2.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论