


前言
最近几年做分布式项目,很多工作是关于OLTP(联机交易系统)场景下数据分布式架构的,疫情期间正好整理下这方面的一些设计与实践。为避免篇幅太长,本文分为设计篇和技术篇,设计篇主要偏向数据拆分的理论与方法,还有一些原则与经验。技术篇则主要会介绍分库分表中间件的设计与使用实践,以及如何构建一个完整的分布式数据服务平台。
一般来说做分布式架构,应用层是好做分布式的,因为往往都是无状态的(或者通过将数据转移到DB、缓存、MQ等方式来实现无状态),只需在流量入口、即在应用前面加一个负载均衡即可(例如Nginx、HAProxy、F5),这在大单体架构也多已具备。所以一般我们说分布式架构,一个重要的部分就是要做数据的分布式化。
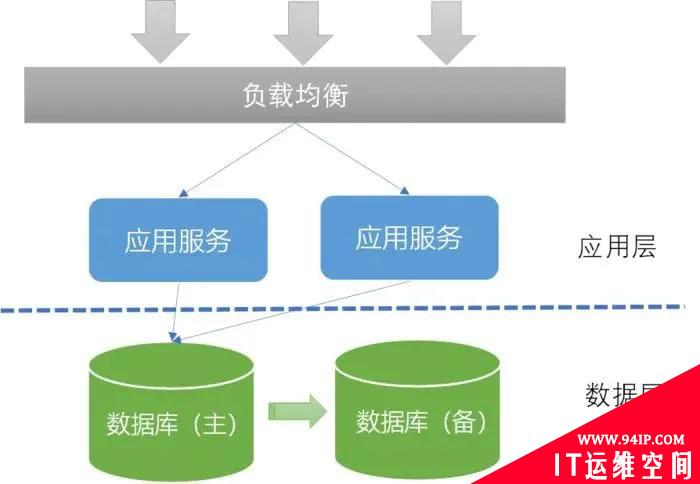
传统单体集中式架构
数据的分布式不像应用那么简单,因为各节点的数据可能是不一样的,需要进行路由、解决多副本一致性,甚至多写冲突等问题。虽然实现方案复杂,不过数据的分布式本质上就两种朴素思想:复制和分片。复制技术在传统关系数据库中也很常见,主要用来做主备、双活,例如 MySQL Replication、Oracle DataGuard等。分片在数据库里也有对应产品。例如 MySQL Fabric、Oracle Sharding,但与复制相比,这些数据库厂商对应的分片方案却一直没有被大众广泛接受。
在NewSQL数据库中往往都内置了sharding机制,而且都基于paxos、raft算法来保证复制一致性,关于分库分表与NewSQL方案对比选型,可参见我之前一篇文章《分库分表 vs NewSQL数据库》。
在OLTP场景下,复制和分片思想应用在传统关系数据库上,有两个更为人熟知的名字,分库分表与读写分离。
分库分表,就是对原来单一数据库表进行拆分,是基于传统关系数据库实现分布式架构转型的一个主要方式,因此首先第一个问题:
为什么拆分?什么时候需要拆分?
容量、性能、横向扩展、微服务
单机数据库的存储、CPU、内存等资源都存在上限瓶颈,当数据量、访问量到达一定量级后,性能则会急剧下降,也就是说通过scale up这种垂直扩展的方式是一个上限的,而且成本是较高的。
如果要实现scale out横向扩展,就需要把原来一张表的数据拆分到多张物理库表中存储(水平拆分)。
另外如果是微服务架构,拆分后的服务归属不同的系统,对应不同的数据库,其实就已经进行了垂直拆分。
拆分方式有哪些?
1、垂直拆分
垂直拆分一般更加贴近业务的拆分方式,在做微服务时使用最多的就是这种方式,具体会根据DDD(领域驱动设计)技术或者业务能力进行拆分,一般有界上下文确定了,拆分规则也就比较明确了。
这种方式对应用侵入性较小,往往只需要配置各自独立数据库(可能是物理机,也可能只是不同的实列)即可,最多做一个多数据源选择的数据访问层。
另外还有一种垂直拆分的场景是由于冷热数据,同一行数据的不同列访问频率差别很大,或者是有些Text、Blob等大字段影响读写效率,这时也会将这些列拆分到不同表中。这种方式一般不常见,很多时候是在做性能优化时会考虑。
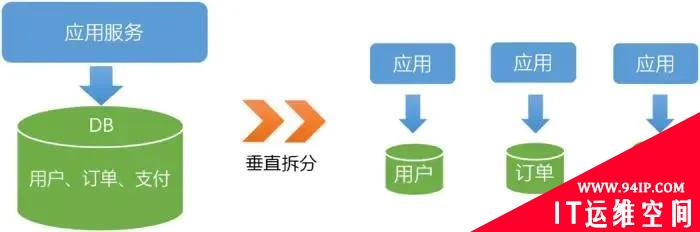
垂直拆分
垂直拆分的优点:
- 拆分后业务清晰,拆分规则明确。往往是按照系统或者交易的
- 系统之间整合或扩展容易
- 数据维护简单、架构复杂度低
垂直拆分的缺点:
- 部分业务表无法join,只能在应用层通过接口方式解决
- 受每种业务不同的限制存在单库性能瓶颈
- 往往会产生分布式事务场景
由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,这时就需要水平拆分来做解决。
2、水平拆分
水平拆分更加技术化,将一张表的数据分布到多张库与表中,具体方式可分为:只分库、只分表、分库又分表。例如order表,只分库(ds1.order、ds2.order…dsk.order),只分表(ds.order_0、ds.order_1…ds.order_n),分库又分表(ds1.order_0、ds2.order_1…dsk.order_n)。
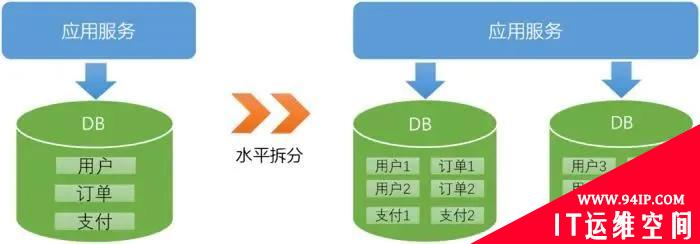
水平拆分
水平拆分的优点:
- 如果操作数据分布在同一库中, 可以支持join、子查询等复杂SQL
- 解决了单库性能瓶颈,支持横向扩展
- 由于应用未拆分,如果有分布式数据访问层,则应用改造较少
水平拆分的缺点:
- 拆分规则、分库分表数量需要精心设计
- 如果涉及多个库,会产生分布式事务场景
- 数据扩容时数据迁移工作量较大
- 跨库join往往需要应用实现,性能较差
- 数据合并、聚合、分页等无法由数据库直接支持
数据库有分区表还要分库分表吗?
传统关系数据库的分区表本质上还是共享cpu、内存,所以仍然面临着scale up的问题,而且分区表支持的分区键往往也不够灵活。但新的一些NewSQL分布式数据库,如OceanBase的分区表分散在不同的存储节点上,从而避免单机性能瓶颈问题。
拆分具体步骤
1、确定拆分方式
根据业务特性选择合适的拆分方式,一般结合使用。
1)垂直拆分
- 场景:字段长度、访问频率差别较大字段表、微服务化
- 注意:需要在同事务中操作的表尽量不要做拆分
2)水平拆分
- 场景:数据量较大,超过单表、单库性能
- 注意:是否有跨库事务,是否有非分片键操作表的场景,会涉及到库表扫描交易
2、确定拆分字段
1)垂直拆分表、字段
按照功能模块进行拆分直接按表即可,如果是拆分部分列,则需添加关联列甚至冗余列。
2)水平拆分字段
确保 拆分表都有分片键,多为主键或唯一索引,这些列中需包含分片信息。如果请求中未包含分片信息,则需要一个全局的路由表。
3、确定拆分规则
1)范围Range
适合按照一定规律有序递增的业务字段,例如日期、流水ID等,这种方式,例如0-9999->库1,10000~19999->库2 …;20150101-20161231->库1,20170101-20171231->库2…。
这种方式天然支持水平扩展,方便进行冷热分离、归档,按需扩容方便,但负载容易不均衡,如果单库压力大,则也需数据迁移。
2)哈希Hash
数据分布比较均衡,一般通过mod库/表数量计算路由,本质上一种预分配,因此扩容时需要进行数据迁移,通常有一致性哈希、成倍扩容法。
3)应用自定义
由应用自定义路由规则,配置有分片ID对应的库表序号,可以通过路由表、配置文件或其它自定义算法。这种方式灵活度最高,容易实现动态改变。
在我们项目中是1、2、3方式都有使用。
4、确定拆分数量
1)假设目标数据量为T(根据业务发展需求预估)
2)单表数据量建议P(例如MySQL 为500w),分表数量=T/P
3)目前配置典型业务场景下,单库性能稳定前提下对应的数据容量上限L
单库性能可以根据cpu(80% 以上)、磁盘IO(磁盘使用率100% iowait出现并逐步增大)、交易tps稳定性(出现tps大幅度波动)等系统指标确定其瓶颈状态从而得到容量上限的评估。
4)分库数量=T/L
库表的数量关系到未来扩容、以及运维需求,不宜太多也不宜太少,以上主要是从容量角度去计算,实际场景下还需要结合硬件成本预算、数据清理归档策略等因素综合考虑。
拆分后怎么扩容?
1、垂直扩容
垂直拆分后,如果某个应用的数据库压力太大,可通过增加其资源配置(CPU、内存、PCIE)进行垂直扩容。
2、水平扩容
水平拆分下可以通过增加数据库服务器进行扩容。这种方式需要进行数据迁移,如果一致性哈希则迁移就近节点数据,如果是成倍扩容时则需迁移所有节点一半数据。
一致性哈希模式虽然迁移的数据量较小,但容易造成数据的冷热不均,因此我们项目中采用的成倍扩容方式,具体方式是提前将表分出来,例如分成128张表,项目初期将这些表均匀分布在4台数据库服务器,随着业务增加数据量增长,扩容到8台数据库,只需要将原4台数据库各自一半数量的表迁出到新增的4台服务器,然后修改SQL路由即可。
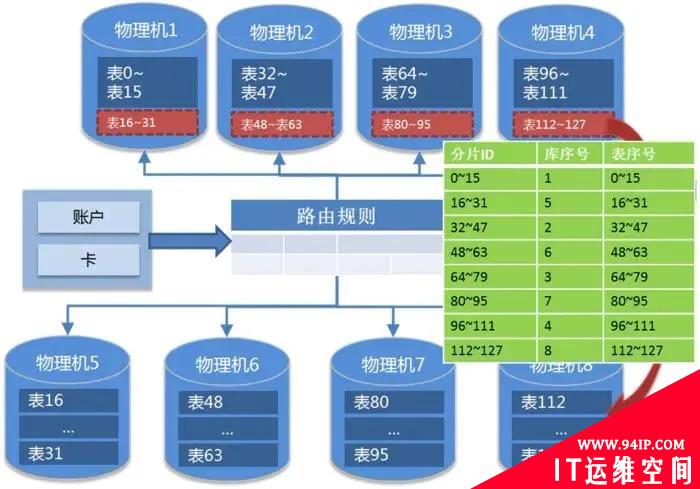
成倍扩容:应对整体数据量增长,扩容后物理机是原有2倍
如果是单台数据库有热点数据压力,也可以只将该库一部分数据迁移出新扩容的库。
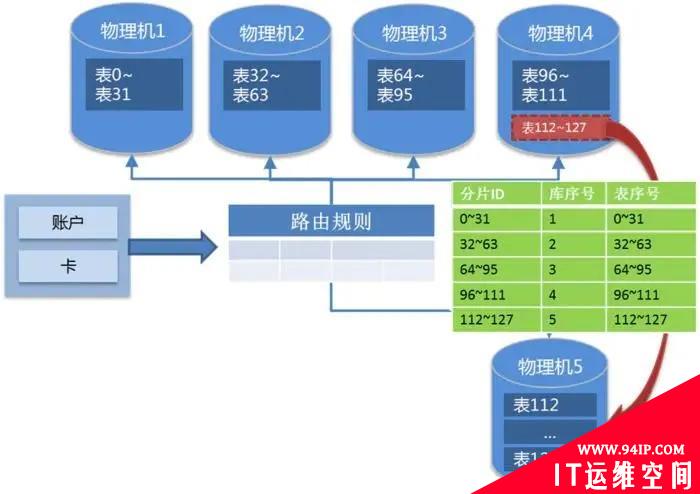
单库扩容:应对某个切片数据增长过快,扩容到独立的物理机
拆分后面临的问题
- 引入分布式事务的问题
- 跨库Join的问题
- 多库合并排序分页问题
- SQL路由、重写问题
- 多数据源管理问题
- 多维度拆分后带来的数据汇总查询等操作问题
解决方式:
- 尽可能避免分布式事务、跨节点join、排序场景
- 避免使用数据库分布式事务,提供柔性事务支持(幂等、冲正、可靠性消息、TCC)
- 由应用层解决join问题
- 提供分布式数据访问层
- 汇总库、二级索引库、小表广播
关于分布式数据访问层在技术篇进行详细介绍。
读写分离
在实际业务场景中,对数据库的读写频率是不一样的。有的是写多读少,例如交易流水表;有的是读写均衡,例如订单表;有的则是读多写少,如客户、信息以及配置等信息表。
数据分片解决的是单点性能瓶颈和横向扩展能力,适合写压力比较大的场景。而读多写少的这类场景,如果单库容量可以满足,则可通过读写分离来解决读压力大的问题。具体可以把写操作路由到主库,读操作按照权重、机房等分散在主库和各个从库。
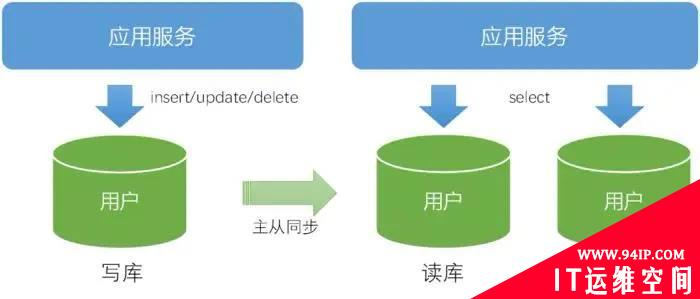
读写分离
读写分离模式下需要注意几点:
1)主从延迟。在从库上读比主库数据有一定时延(一般在毫秒级别,写压力大时可能在秒级别),所以选择这种方式时业务上要允许一定的数据时延,例如一般对外查询类交易都使用这种方式。
2)同一事务中,不能在从库读取数据,因为可能由于数据延时读取到脏数据,违背事务的一致性,所以必须在主库读取。在实际开发时,数据访问层可根据是否关闭事务自动提交来自动判断是否必须在主库读。
3)对于数据延迟容忍度很低的查询交易,可以在开发时单独再封装一个从主库查询的接口,或者在入参增加“是否需要强一致”标志,交易实现时根据该标志选择从主库还是从库读。
在实际项目中分库分表和读写分离方式都有场景在用,但注意一般情况下避免使用分库分表+读写分离这种复杂方案,因为分库分表后读写压力也不会太大了。
原则与经验
数据分布式是个系统工程,需要从领域建模、场景划分、数据访问、数据迁移扩容等多方面综合考虑,在落地实现前要从全局做好设计,这里简单列下我们的一些设计原则与经验:
1)用简单的方案解决问题。能不切分尽量不要切分,切莫为了分布式而拆分。读写分离能解决问题,就不分库分表。
2)切分一定要选择合适切分规则(能保证90%交易不会跨分片), 梳理好所有场景,提前规划好再实施。
3)数据访问层设计上功能要强大,但一定明确使用场景,切忌无脑滥用。比如我们项目中数据访问中间件虽然支持分布式事务XA,但一般并不推荐使用;支持DDL,但联机交易时禁止使用;支持多库链式事务提交,但默认只支持严格单库事务。
4)制定应用开发规范,明确SQL使用限制与要求,SQL要尽量简单。例如我们项目使用MySQL,部署在PC Server上,单机性能相比小型机上DB2、Oracle差很多,因此禁止使用触发器、外键、join,SQL操作必须携带索引与拆分列(数据访问层也会校验),主键必须是自增等等。
5)尽量使用柔性事务解决跨库与跨系统事务问题。能用MQ最终一致性就别用Saga、TCC。
转载请注明:IT运维空间 » 运维技术 » 简单明了!OLTP场景下的数据分布式设计原则
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值















发表评论